2022年OpenAI虧了30多億元,
站在風口上,誰的壓力會小呢?

【科技明說 | 每日看點】站在風口上。OpenAI公司在2022年虧得十分“燦爛”,和往年同比幾乎翻了一倍,虧損約達5.4億美元,折合人民幣約31億元。
就算是這樣翻倍地虧損,OpenAI也沒有商湯科技SenseTime表現強烈,商湯科技財報顯示2022年虧損約61億元左右。
比燒錢速度,更要比創新速度
如果非得再對比一下年營收,商湯科技可謂贏得太漂亮了,OpenAI的2022年營收才多少錢?商湯科技2022年營收高達38億元,令OpenAI的老板們羨慕嫉妒恨了么?OpenAI雖然估值接近300億美元,約超2000億元人民幣,但2022年營收卻少得可憐,約3600萬美元,約合人民幣2.5億元,2023年預估能到2億美元,也就是約合人民幣不到14億元。
然而,虧了30多億元的OpenAI,引領着全球ChatGPT的AI大潮;虧了61億元的商湯科技,帶來了大家意想不到的“商量 SenseChat、秒畫 SenseMirage、如影 SenseAvatar、瓊宇 SenseSpace、格物 SenseThings,以及日日新SenseNova。
其名字確實非常亮眼,達到行業國際水平的同時,有一種趕超OpenAI,將ChatGPT踩在腳下磨擦的氣勢。但能否引領全球AI趨勢卻是一個大問題,不過,有着這樣豐富的大模型產品方向,我想商湯科技至少在中國應是AI行業領先水平了吧?
業內傳說商湯科技擁有有2.7萬張AI專用GPU。目前7000張GPU對外服務8家大型客戶,實現算力Infrastructure as a Service。其自然語言大模型Sense Chat已經可以實現基本的語言交互、寫故事、法律專業領域的文本分析、代碼編程、醫療問診。當然商湯科技不能算是一個公有雲廠商,但已經在着手提供類似雲服務的算力與GPT輸出了。
我不禁想問一下:同樣是做大模型AI領域的科技公司,爲啥差距這么大呢?
我只能這么說,大型人工智能(AI)語言模型是一項昂貴的業務,但貴有貴的道理,花了高價錢可以看到真正的技術引領,真金白銀換創新也是值得的。
然而更悲催的是,業界傳言說OpenAI雖然牛氣衝天,實際上是靠挖了一些谷歌、蘋果等科技公司AI領域的高手過來做ChatGPT。挖人成本高,所以虧損大。這個邏輯我感覺不對,靠挖人可以做到世界第一,我覺得是非常成功的了。就算虧得一塌糊塗也是可以看到未來的,畢竟微軟也不斷在給OpenAI輸血,據說累計投資OpenAI已經高達130億美元了,這個投資節奏可能不會變化,還會繼續高投入,搶未來。
即便OpenAI燒錢速度快,但其GPT迭代速度也是驚人的,在GPT-4出來後不久,就已經开啓了开源战略。可以想象一下,未來的AI世界除了OpenAI,還會有誰呢?有誰還可以如OpenAI這樣吸金,這樣燒錢,這樣高速創新GPT呢?
你覺得還會有誰,請空了告訴我一下。謝謝。
字節跳動悄然在GPT上“練舞”

不過我們再看看另外一個科技公司:字節跳動ByteDance有啥GPT“動作”。
業內也盛傳字節跳動在大模型上也在低調潛行,並且在2022年底專門組建了一個針對GPT模型研究的團隊,主要研究人員也是來自字節跳動的搜索業務部門、AI Lab和AML(應用機器學習)等團隊成員。在多模態場景下,字節跳動在視頻、圖片、語音等數據比較豐富,訓練起來還是非常有基礎。基於技術研究的成熟度,字節跳動對外透露的消息稱,前期主要針對在語言和圖像兩種模態發力,後期針對視頻方面的研究也將是一個重要的目標。
只是,字節跳動還有一條重要的發展路线就是火山引擎。2023年4月18日,火山引擎正式推出自研DPU等系列雲產品,並推出新版機器學習平台:支持萬卡級大模型訓練、微秒級延遲網絡,彈性計算可節省70%算力成本。有着更豐富與更強大性能的自研DPU的GPU實例,對於後期在GPT領域的自研與探索將帶來很好的基礎支持,當然火山引擎雲也是字節跳動對外輸出AI能力的重要途徑之一。
業內朋友評論說到,要做大模型,必須“背靠大數”(也是大樹)才可以。比如OpenAI背後的微軟,可以百億美元地投入眼睛都不眨一下。字節跳動不僅有海量數據的“大數”,也有龐大的技術團隊“大樹”。
沒有對比就沒有鑑別。就此來看看,字節跳動的發展非常迅速,在2022年,字節跳動躋身“年營收5000億元俱樂部”,开始看齊三巨頭,京東、阿裏巴巴和騰訊。
5000億元年營收,意味着什么呢?
縱觀2022年全年,年營收5000億元俱樂部的中國科技公司主要有,京東、阿裏巴巴、騰訊和字節跳動。
京東集團2022年全年淨收入10462億元人民幣(約1517億美元),同比增長9.9%。歸屬於普通股股東的淨利潤爲104億元,2021年爲134億元,同比下降22%。
阿裏巴巴2022年自然年營收爲8645.39億元,因爲財年與自然年出入比較大,這裏僅作營收的自然年統計。對於淨利潤而言,業內有數字在說息稅折舊及攤銷前利潤 (EBITDA)約爲227億美元,但這個數字未得到正確途徑證實。
騰訊控股2022年營收5545.5億元(約796億美元),同比下滑1%;歸屬於普通股股東全年淨利潤1882.4億元,同比下滑16%,
字節跳動2022年收入超800億美元,折合人民幣超5000億元。這比2021年的約600億美元增長了30%以上。由此字節跳動也正式入圍“年營收5000億元俱樂部”。同時業內有傳言說,2022年字節跳動息稅折舊及攤銷前利潤 (EBITDA)約爲250億美元(1718億元),同比增長79%。 如果這個數據是真實的話,對比阿裏巴巴、京東、騰訊而言,在淨利潤表現上字節跳動穩贏了。
據業內分析,字節跳動的收入增長貢獻最大的來源於在中國大陸的核心廣告業務,2022這部分業務帶來的收入與2021年同比增長了2.5倍,達到100億美元左右。
除此之外,BAT中的百度2022年實現營收1236.75億元,歸屬百度的淨利潤(非美國通用會計准則)206.8億元,同比增長10%。假如只是從年營收來看,百度距離京東、阿裏巴巴、騰訊和字節跳動的距離還不小。
當然,5000元年營收,意味着進入這個階段的科技企業擁有更爲全面的市場競爭力與影響力,大者恆大的效應也將放大。
假如這個分析正確的話,那么小者會不會恆小呢?還是說小者求大?
對於大模型的研究投入,前衛的OpenAI虧得嚇人,火力全开的商湯科技虧得也厲害。相對而言,字節跳動植根自己的數據基礎與研發隊伍,一步一步地嘗試,身體力行,從大模型軟件與DPU、GPU雲產品雙管齊下,積極進取不冒進的這個思路值得一看。
公有雲廠商的ChatGPT之變

大模型如此這般火熱,也引發了業界正在熱議的另外一個話題:ChatGPT發展大放異彩,公有雲格局會不會大變?
首先得明確,AI風暴來襲,雲與ChatGPT到底啥關系?
在看到公有雲廠商紛紛开始大模型發布,开始GPT的融入之時,我是在想AI風暴來襲,在擔心AI帶給人類危險的同時,更想知道公有雲與ChatGPT到底關系如何?
業內有朋友說,公有雲可能會喫掉ChatGPT,要不然就是ChatGPT會喫掉公有雲。
也有業內朋友指出,這最終雲廠商賣的還是算力,核心還是GPU。
這么說還是商湯最牛了,業內朋友傳說商湯科技至少手裏握了上萬張英偉達的卡。有卡的不一定牛逼,可能是最大的韭菜。會賣韭菜也是能力,就看商湯科技的AI創新能力到底如何了。還有賣給誰很重要,像我這樣的人,肯定不喜歡喫韭菜。但不少人還是喜歡韭菜盒子,韭菜雞蛋餃子。羅卜白菜各有所愛,就看誰喜歡了吧?
但在算力上疊加GPT和模型,價值還是可以挖,只是我感覺很難。雲廠商做通用GPT,搭上行業模型,還是有機會。只是比較難做,因爲做行業模型就必須另外找團隊,需要投資更多錢,現在雲廠商盈利都難,這個事情很矛盾。
如果這個事情可以做通,再擴展一下,專門提供有行業屬性GPT+行業模型的行業雲打包賣。
現在,在ChatGPT與公有雲結合上,公有雲廠商怎么接招?拆招?
看看亞馬遜雲科技AWS是這樣做的,宣布Amazon EC2 Trn1n 和 Amazon EC2 Inf2實例正式可用:最具成本效益的生成式AI雲基礎設施,與此同時AWS亞馬遜雲科技順應潮流也推出了自己的大模型,Amazon Titan基礎模型目前包括了兩個全新的大語言模型。
再看看阿裏雲是這樣做的,隨着通義千問的大模型發布,阿裏巴巴集團董事會主席兼CEO、阿裏雲智能集團CEO張勇在阿裏雲北京峰會上強調說,阿裏所有產品未來將接入大模型全面升級。
再看看騰訊雲在阿裏雲發布通義千問的大模型之後發布的新一代HCC高性能計算集群,採用最新一代星星海自研服務器,搭載NVIDIA H800 Tensor Core GPU。基於自研網絡、存儲架構,帶來3.2T超高互聯帶寬,TB級吞吐能力和千萬級IOPS。
騰訊雲給出的實測結果顯示,新一代集群算力性能較前代提升3倍。而在2022年10月,騰訊完成首個萬億參數的AI大模型——混元NLP大模型訓練。在同等數據集下,將訓練時間由50天縮短到11天。如果基於新一代集群,訓練時間將進一步縮短至4天。目前針對新一代HCC高性能計算集群,用戶需要通過騰訊雲的官方通道申請參與內測,什么時候公开GA值得關注一下。
百度算是國內發布大模型很早的科技公司了,文言一心並沒有爲百度帶來意想不到的收獲,相反,更多的是邁向ChatGPT領域的教訓與經驗。當然,至少對百度的中文搜索引擎帶來更貼身用戶的搜索結果,不過,很遺憾的是不少像我這樣的百度用戶卻對搜索結果中包含衆多軟性廣告感到十分麻煩。
雖然華爲的大模型並沒有像百度的文言一心那樣高調發布,但華爲大模型發布比百度還要早,2021年就公开了,從時間上來看華爲領先了許多。盤古大模型由NLP大模型、CV大模型、多模態大模型、科學計算大模型等多個大模型構成,這樣看來華爲做事情還是講究專業,專業的事情做起來對旁觀者而言就顯得復雜。
另外,在ChatGPT與公有雲結合路线上,業界大牛還是微軟莫屬,微軟投巨資支持的OpenAI公司在2023年4月推出了GPT-4,开始真正成就了一個大型多模態模型,能接受圖像和文本輸入,再輸出正確的文本回復。實驗表明,GPT-4 在各種專業測試和學術基准上的表現與人類水平相當。例如,它通過了模擬律師考試,且分數在應試者的前10%左右;相比之下,GPT-3.5的得分在倒數10%左右。
在過去的兩年裏,OpenAI重建了整個深度學習堆棧,並與微軟Azure一起爲ChatGPT工作負載從頭开始設計了一台超級計算機。這台超級計算機基於微軟的Azure雲基礎設施,使用了上萬顆Nvidia H100和A100Tensor Core GPU,同時採用了Quantum-2 InfiniBand高速網絡架構。不僅如此,微軟還將ChatGPT的能力全面加持在了全球著名的辦公軟件、搜索引擎bing等產品領域,微軟已經走上了全面ChatGPT化。
不過就此分析,在GPT不斷融入公有雲的進程上,公有雲廠商的業務本質依然不變,還是賣資源。也有人對我問道,ChatGPT不斷融入雲上,雲服務會越來越便宜么?我認爲不會,而是越來越實惠。對於用戶來說,雲帶來的只是實惠,而不是便宜。因爲只有重度的公有雲長期用戶就深有體會,公有雲到底是便宜還是昂貴。
正因爲如此,業內有朋友一直認爲,ChatGPT與公有雲沒有關系,一是一二是二,如果1+2可以結合的話,依然還是等於1+2而不是新的數字3。
由此分析來看,公有雲想方設法將ChatGPT融入雲服務之中,最終目的還是希望帶動雲資源的銷售增長,更進一步讓雲的用戶成其爲雲的深度使用者。從這個角度來分析,公有雲因ChatGPT而變化並非真正實現迭代的進化,加持AI能力並不能代表公有雲主流業務的本質改變。
進一步分析來看,對於用戶而言,將會更容易深度綁定在公有雲之上,一旦業務發展變化需要下雲落地之時,用戶需要付出的代價將會更高。當然,對於自身業務必須架構在公有雲之上的用戶而言,這樣“雲+GPT”的變化不存在這個方面的下雲落地問題,反而更有利於其業務加速創新。
此外,對於开發者,利用AI平台的便利性確實可以帶來很多幫助,節省开發流程的時間。亞馬遜雲科技推了CodeWHisperer,這么好的AI編程工具,全开源全免費,可謂程序員的最佳日常伴侶,人見人愛花見花开……如果1000人採用無所謂改變啥,試想1000萬人使用了,將會怎樣?
科學客觀認知GPT發展之勢
值得一提的是,最近埃森哲(Accenture)的研究指出,在現實世界和數字世界越來越密不可分的今天,生成式人工智能等技術的迅速演進正在創造更爲廣闊的全新商業未來。隨着ChatGPT的快速興起,生成式人工智能展現了其顯著增強人類能力的本領,成爲了全球焦點。
據埃森哲測算,在各行業,有四成的工作時間可由基於語言的人工智能技術提供支持或得到增值。全球的受訪企業高管幾乎一致(98%)認爲,未來三至五年內,人工智能基礎模型會對企業組織战略產生極爲關鍵的影響。
同時,埃森哲《技術展望2023》揭示了四大趨勢,幫助企業开啓數實融合的新發展歷程,即:通用智能、數字身份、數據透明和前沿探索。其中針對通用智能,無論是擔任個人助手、創意搭檔或者專業顧問,生成式人工智能將不斷提升人類能力。幾乎所有受訪高管都認爲,這類工具可以激發出巨大的創造力和創新力(比例達98%),开啓企業級智能的新時代(95%)。
由這個研究可以看到,ChatGPT雖然不能徹底革新公有雲的主流業務,但改善改進增加雲服務的本身的價值還是很值得發展。
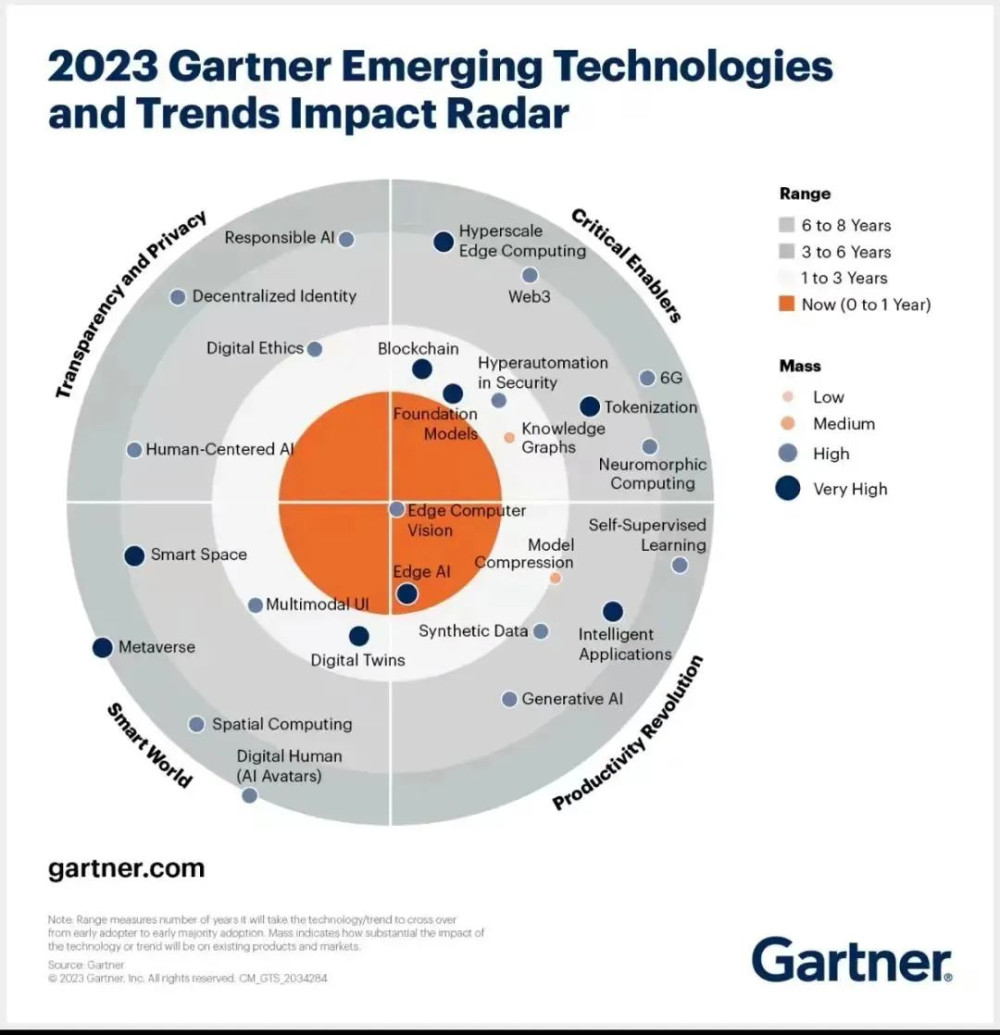
在Gartner的一份報告《2023 Gartner Emerging Technologies and Trends Impact Radar》新興技術及趨勢影響雷達中提到26項最具影響力的新興技術和趨勢可以看到,邊緣AI、基礎模型Foundation Models、Model Compression的發展將會更爲迅猛,特別是模型壓縮(model compression)可以將大模型壓縮成小模型,壓縮後的小模型也能得到和大模型接近的性能,這對於ChatGPT進入垂直行業領域帶來更大可能。
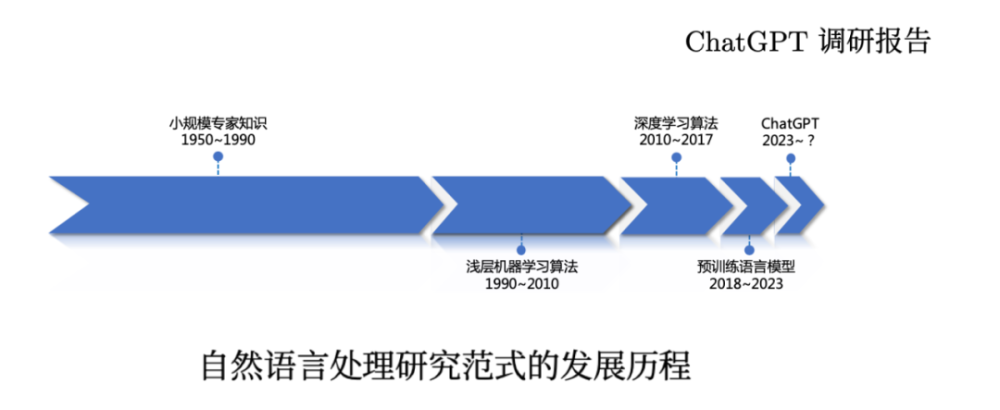
然後,我還在哈工大自然語言處理研究所(HIT-NLP)出品的《ChatGPT調研報告》,是現在爲止我看到的對ChatGPT比較全面分析了。其中分析指出,從自然語言處理技術發展階段的角度看,可以發現一個有趣的現象,即每一個技術階段的發展時間,大概是上一個階段的一半。小規模專家知識發展了40年,淺層機器學習是20年,之後深度學習大概10年,預訓練語言模型發展的時間是5年,那么以ChatGPT爲代表的技術能持續多久呢?如果大膽預測,可能是2到3年,也就是到2025年大概又要更新換代了。
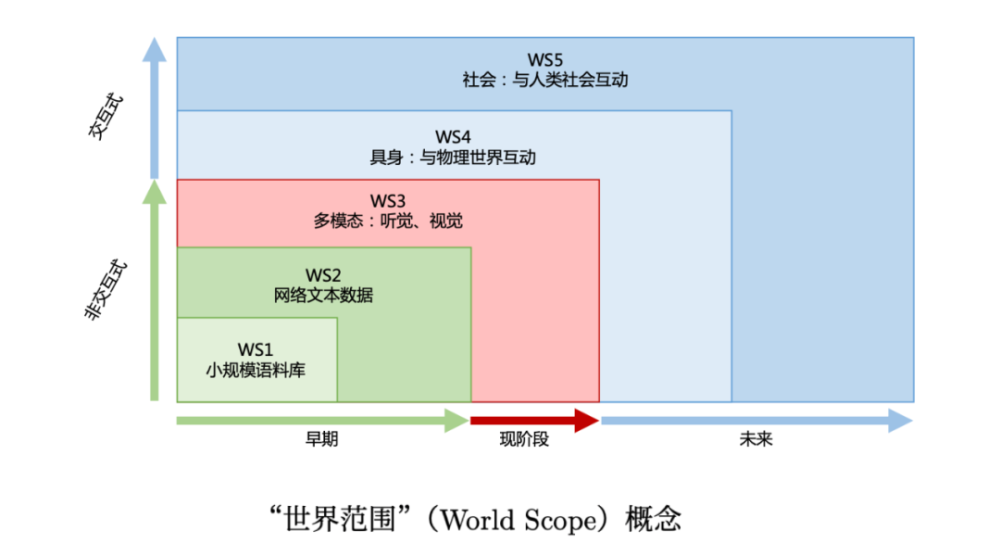
經過近70年的發展,自然語言處理技術先後經歷了五次範式的變遷,隨着ChatGPT的產生,人們也看到了實現通用人工智能(AGI)的曙光。在這個過程中,自然語言處理技術呈現了明顯的“同質化”和“規模化”的發展趨勢,使用參數量越來越大的模型,從越來越多的文本數據中進行學習。同時分析指出,自然語言處理未來需要融入更多的多模態信息。此外,還需要智能體能夠同物理世界以及人類社會進行交互,這樣才能真正理解現世界中的各種概念,從而實現真正的通用人工智能。
對於哈工大自然語言處理研究所(HIT-NLP)出品的《ChatGPT調研報告》有興趣的朋友,可以私信留言加阿明好友,阿明可以看情況私下分享業內學習參考。
不過,現在在AI與大模型領域逐漸呈現出百花齊放的態勢。來自新浪數科COO於冬琪的幾段觀點在朋友圈傳播,他個人最喜歡這么幾個項目:如改善盲人讀屏效率和爲盲人用戶讀出圖片上信息。幫助農民找到地裏的冬蟲夏草,提高挖掘效率。AI診斷皮膚問題。AI幫律師們快速整理法條、給出建議。 幫助刑警們基於目擊者描述,繪制出嫌疑人畫像。幫助醫生們,把語音自動錄入成病例。
他沒想到的是,現在有很多團隊有自研的技術和論文。甚至於有人做出來了可部署在個人電腦上、基於本地數據的丐版大模型。
綜合來看,AI風暴來襲,公有雲與ChatGPT關系越來越親密,也越來越復雜。到底該如何去發展,不管是微軟還是亞馬遜還是阿裏雲還是其他公有雲廠商,都在摸着石頭過河,就看誰更會探索,更會迅速了吧。
未雨綢繆,如何看AI威脅論?

再進一步看看針對AI的法律監管領域。不少國家开始出台法律法規監管AI,隨着GPT發展越來越快,相關監管規定也將加速出台。
當然,從通用大模型走向行業大模型,行業數據安全監管也是需要重視。
對此,我們又不得不再討論一下AI的人類威脅論。
至少當前要思考對AI能力邊界做一些框架限定,並有利於社會進步與人類社會的發展。據外媒消息說,馬斯克(Elon Musk)、蘋果聯合創始人沃茲尼亞克(Steve Wozniak)等1000多名科技研究人員和高管呼籲“暫停”OpenAI的GPT等先進人工智能系統的訓練6個月,用來开發和實施一套協議,使這些強大的人工智能系統更加准確、透明和值得信賴。
可能,這又是一次人類的覺醒,幸好馬斯克們在AI道路上沒有完全癡迷不悟! 然後,也有非營利活動組織Future of Life Institute發表了一封公开信,在發表後幾小時,已有來自學術界和科技行業的1100多人籤名。所有籤名的人都十分擔心,AI系統的智能可以與人類相媲美,可能對社會和人類構成嚴重威脅。
全球存儲觀察的阿明對此表示,“百年後,我們的子孫後代看到現在我們,他們會怎樣想現在的AI瘋狂?”
另有業內人士分析指出,國內現在還不用太擔心這個方面的問題,因爲像國內頂級“ChatGPT”啥時候和GPT-4一樣聰明了再說吧。
【全球存儲觀察 | 全球雲觀察 | 阿明觀察 |科技明說】專注科技公司分析,用數據說話,帶你看懂科技。本文和作者回復僅代表個人觀點,不構成任何投資建議。
原文標題 : 同樣是做大模型的科技公司,爲啥差距這么大呢?
標題:同樣是做大模型的科技公司,爲啥差距這么大呢?
地址:https://www.utechfun.com/post/213391.html