近年來,人工智能應用正經歷一輪快速的發展與普及,而以ChatGPT等先進的大模型技術在此過程中起到了關鍵作用。這些模型對計算能力的需求不斷攀升,催生了AI芯片設計的不斷革新,進入了大算力時代。
目前,主流AI芯片的架構仍然沿用了傳統的馮·諾依曼模型,這一設計將計算單元與數據存儲分離。在這種架構下,處理器需要從內存中讀取數據,執行計算任務,然後將結果寫回內存。盡管AI芯片的算力在不斷提升,但僅僅擁有強大的數據計算能力並不足夠。當數據傳輸速度無法跟上計算速度時,數據傳輸時間將遠超過計算時間。
以Transformer架構爲基礎的AI大模型導致了模型參數量激增,短短兩年間模型大小擴大了驚人的410倍,運算量更是激增了高達750倍。盡管硬件的峰值計算能力在過去20年中提升了驚人的60,000倍,但DRAM帶寬的增長卻相對滯後,僅提高了100倍。計算能力與帶寬能力之間的巨大差距導致了內存容量和數據傳輸速度難以跟上AI硬件的計算速度,這已成爲限制AI芯片性能發揮的主要瓶頸,通常被稱爲“內存牆”問題。
內存牆的應對方法
針對內存牆問題,研究人員正積極探索多種解決方案,主要可分爲以下三個研究方向:
算法優化:重新審視網絡模型設計,致力於優化算法實現,以減少對高速數據傳輸的依賴。這一方向旨在從根本上降低數據傳輸需求,提升算法效率,從而打破內存牆的限制。
模型壓縮:通過降低模型精度(如量化)或去除冗余參數(如剪枝)來壓縮推理模型。這種方法可以顯著減少模型大小,降低內存佔用,從而減輕內存牆帶來的壓力。
AI芯片架構設計:設計高效的AI芯片架構,以優化數據流和計算流程。通過硬件層面的創新,減少數據搬運和計算量,提高整體系統效率。
算法的優化與模型的壓縮是軟件研究人員追求的重要方向。在AI芯片架構設計領域, 各大AI芯片公司也开始優化芯片架構, 以實現更爲高效的內存傳輸。安霸同樣提出了其專有的解決方案。
CV3系列芯片如何打破內存牆
2015年, 安霸收購了自動駕駛算法公司VisLab, 开始研究自動駕駛需要怎樣的芯片。 2017年,安霸推出第一代CVflow架構芯片CV1, 用於加速AI視覺計算。2018年开始逐步推出並量產專門針對車載輔助駕駛市場的第二代CVflow架構芯片CV2系列。 2019年,自動駕駛技術的突飛猛進,使得汽車行業對芯片算力的需求急劇增長,標志着大算力時代的來臨。在這樣的技術背景下,安霸前瞻性地啓動了CV3系列大算力芯片的設計工作,旨在爲自動駕駛場景提供強大的計算能力。經過三年的精心打磨與架構設計, 2022年, CV3架構的第一顆芯片CV3-HD成功點亮,其最高算力達到了1500 eTOPS(等效算力),而功耗僅爲50瓦,展示出了卓越的計算性能與能耗比。 2023年, 首個面向量產智駕域控制器的芯片CV3-AD685順利點亮並开始提供樣片, 其算力達到750 eTOPS(等效算力)。2024年1月,安霸再次推出了CV3-AD 汽車智駕域控制器芯片的最新成員:CV3-AD635 和 CV3-AD655。至此,CV3-AD 系列芯片已經實現了從主流到中、高端乘用車市場高級輔助駕駛與自動駕駛解決方案的完整覆蓋。
在深入洞察自動駕駛場景的基礎上, 安霸的CV3系列芯片在設計之初就敏銳地預見到大算力時代所帶來內存帶寬挑战。爲了突破內存瓶頸,CV3在內存控制器上採用了先進的LPDDR5技術,每位DRAM的數據傳輸速率高達8Gb/s。針對不同應用場景的算力需求,設計了64位、128位和256位的內存位寬,從而確保在各種計算場景下都能提供足夠的數據傳輸帶寬。
在AI加速器的架構設計上,CV3系列芯片推出了安霸特有的第三代CVflow架構。這一架構賦予了CV3卓越的算力性能和優異的能效比。如圖1所示,CVflow的總體架構展示了其數據流和計算單元的組織結構。
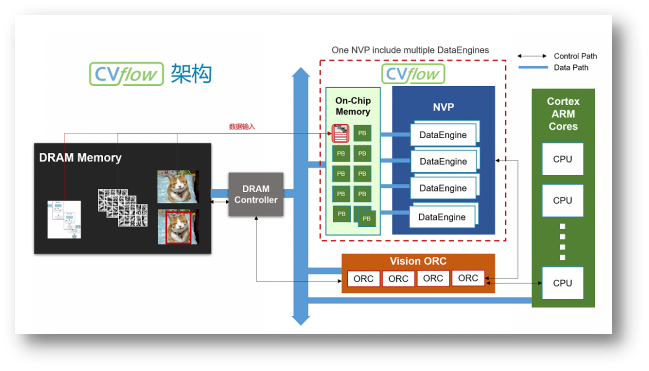
圖1 CVflow架構圖
具體來說, CV3的高算力與低功耗得益於以下幾個精心設計的架構特點。
Partial buffer架構
盡管許多AI芯片採用增大緩存的方式來減少DRAM訪問,但緩存系統存在幾個顯著問題:
設計復雜性與成本:緩存系統的設計相對復雜,相較於同等容量的SRAM,它需要佔據更大的芯片面積。這不僅增加了芯片的成本,還可能導致功耗上升。
軟件優化需求:爲了充分利用緩存系統,軟件算法需要針對其進行專門的優化,以提高緩存命中率。這增加了軟件开發的復雜性和工作量。
算力浪費:緩存系統通常遵循“使用時才加載”的策略,這導致計算單元在等待數據加載完成期間無法進行有效計算,從而造成算力的浪費。算力的有效利用率在很大程度上依賴於緩存命中率。
性能不穩定:在復雜的多核多线程環境中,緩存命中率與系統的負載密切相關。隨着負載的變化,緩存命中率可能會受到嚴重影響,導致系統性能的不穩定。
與傳統的緩存系統不同,CVflow架構採取了一種創新的策略,將片上內存(On-chip Memory)分割成多個不同大小的內存塊,這些內存塊被稱爲Partial Buffers(PB)。這些PB的主要用途是存儲計算過程中的中間結果,從而顯著減少對外部DRAM的訪問次數。Partial Buffers所帶來的優勢如下:
簡化的硬件設計與成本優化:PB的設計相較於傳統緩存更爲簡單,這意味着在硬件實現上,CVflow架構能夠節省更多的芯片面積,進而降低制造成本和功耗。
獨立的DMA通道:爲了確保數據的高效傳輸,CVflow架構爲Partial Buffers配置了獨立的DMA(Direct Memory Access)通道。這使得數據能夠從DRAM中快速、無縫地傳輸到PB中,從而避免了數據傳輸的瓶頸。
訪存效率高: 一次性從DRAM和PB之間傳輸大塊數據的策略, 替代了傳統的多次小塊數據傳輸的方式, 減少了數據在內存和向量處理器(NVP)之間的搬運數次,降低了數據傳輸的延遲和开銷
與計算單元並行處理:PB在CVflow內部被組織成一個環形結構。這意味着當一個PB的數據被使用後,CVflow的硬件調度器會智能地加載下一個所需的數據塊到空闲的PB中。這種設計允許數據預加載與計算單元的工作並行進行,從而消除了數據等待時間,提高了整體計算效率。
簡化的內存管理:與需要手動優化和管理的傳統緩存系統不同,CVflow轉換工具能夠自動、高效地管理PB。這意味着开發人員無需花費額外的時間和精力來管理片上內存,從而可以更加專注於算法和應用的开發。
以圖2所示的卷積神經網絡爲例,在傳統的計算架構中,該網絡通常需要12次的DRAM訪問來完成一次完整的計算過程。然而,在CVflow架構下,通過利用高效的Partial Buffers(PB)設計,3到12過程的內存訪問被低延遲的PB所取代。這意味着,中間計算結果可以直接在PB中完成,而無需頻繁地訪問外部的DRAM。因此,整個計算過程中,只需要在輸入和輸出階段各進行一次DRAM訪問,從而減少了10次的DRAM訪問。這種優化不僅顯著降低了計算過程中的延遲,還因爲減少了外部DRAM的訪問次數,從而降低了整體的功耗。
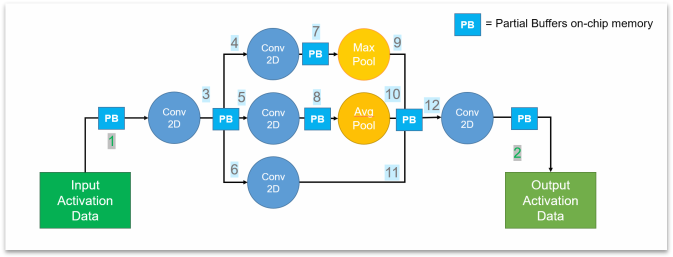
圖2 CVflow卷積神經網絡計算示例
並行的流式架構
CVflow工具根據芯片的片上內存大小,智能地將大型神經網絡切割成多個連續的、緊湊的計算單元,這些單元被組織成有向無環圖(DAG)的形式。這種獨特的架構帶來了多重優勢:
高效內存利用:每個DAG的中間計算步驟都在片上內存內完成,從而避免了頻繁訪問外部DRAM的需求。這不僅減少了數據傳輸的延遲,還提高了內存的使用效率。
快速啓動與並行處理:網絡加載時間大大縮短,因爲只需加載一部分網絡即可开始計算。同時,在計算過程中,CVflow能夠並行加載網絡的後續部分,實現了計算與數據加載的並行化,進一步提升了整體性能。
穩健的性能表現:由於大大減少了對DRAM的訪問次數,並且實現了計算與數據加載的並行處理,CVflow架構在面臨其他芯片模塊(如CPU、GPU、ISP)同時高負載運行的場景時,仍能保持穩定的性能表現,從而確保了在各種復雜環境下的可靠性。
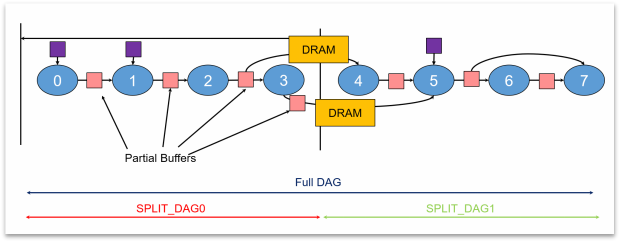
圖3 AI模型的DAG切割示意圖
硬件實現的算子
與GPU通過簡單地堆砌計算單元來提升算力的方式不同,CVflow架構致力於通過實現高效的硬件算子來加速計算過程。CV3的CVflow架構,基於對深度學習網絡的前瞻性研究,實現了超過100種常用算子的硬件化。這種設計策略使得CVflow在晶體管數量更少的情況下實現了出色的算力。
以8x8的矩陣乘法爲例,傳統的計算方式需要512個乘加(MAC)操作,但在CVflow架構中,其特有的矩陣乘法算子能夠在單個計算指令周期內完成。此外,CVflow還支持多種融合算子的應用。例如,對於常見的2D/3D卷積與池化操作,CVflow的轉換工具能夠自動將這兩個操作融合爲一個硬件算子操作,從而有效減少了數據吞吐量和計算周期,進一步提升了整體性能。
非結構化的稀疏加速
通過將AI模型稀疏化,去除冗余參數, CVflow架構帶來了顯著的性能提升, 具體而言:
CVflow工具能夠自動壓縮網絡參數,這減少了芯片端加載AI模型所需的時間。
芯片端的CVflow硬件調度器具備智能分析能力,可以自動識別並跳過不必要的計算,從而顯著降低了計算量。
無需對AI模型結構進行調整, 從而實現了算法的一次性开發和無縫部署。這種特性簡化了模型部署過程,使得模型开發人員無需擔心模型結構的兼容性問題,可以專注於算法的優化和創新。
CVflow工具鏈提供了多種稀疏策略來保證AI模型稀疏後的精度。
以7x7卷積爲例,未進行稀疏化之前,每次卷積操作都需要用到全部的49個參數,並且會執行49次乘加(MAC)操作。然而,當實施了80%的稀疏化後,情況發生了顯著變化:參數量減少了60%,這意味着存儲和傳輸的效率大大提升;計算量減少了80%,從而極大地提高了卷積操作的效率。這種CVflow獨有的稀疏化技術對於優化AI模型的性能和資源消耗至關重要。
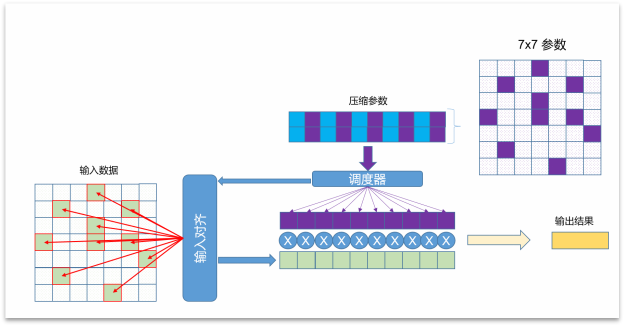
圖4 CVflow 網絡稀疏化示例
支持多種量化格式
CV3的CVflow架構具有強大的數據格式支持能力, 可以支持 4, 8, 16, 32的定點數據格式和16, 32位的浮點數據格式。CVflow工具能夠針對每一層網絡參數和輸入輸出數據進行精確的動態範圍分析,從而確定最優的量化精度,實現高效的混合精度部署。這一特性使得CV3在處理不同數據類型和規模的任務時,能夠靈活適應並發揮最佳性能。
2024年國際消費電子展(CES)期間,安霸展出了基於CV3平台的自動駕駛研發車輛, 並爲受邀客戶提供試駕體驗。此次展出進一步驗證了CV3 CVflow架構芯片的強大實力, 即便面對自動駕駛場景的大算力、高帶寬的復雜計算需求,也能遊刃有余地應對。
2023年, 特斯拉實現了首個端到端大模型自動駕駛系統, 將原本龐大的30萬行的人工規則算法精簡至僅2000行代碼。隨着駕駛數據的不斷積累,自動駕駛技術正朝着端到端大模型的方向發展。 面對未來大模型自動駕駛時代的算力與內存牆挑战, 專爲自動駕駛設計的CV3-AD系列芯片憑借第三代CVflow架構,以芯片架構創新的方式,突破大算力芯片的內存牆的限制,爲大模型算法提供了強大的硬件支持,助力高級輔助駕駛以及自動駕駛技術的普及與發展。
原文標題 : 大算力時代, 如何打破內存牆
標題:大算力時代, 如何打破內存牆
地址:https://www.utechfun.com/post/340784.html