
最近 Google Gemini 引人注目,號稱是第一個各種任務可與 OpenAI ChatGPT 媲美的大模型。某報告顯示 Gemini「Ultra」版各種任務都比 GPT-4 優秀,Gemini「Pro」版則與 GPT-3.5 不相上下。
美國卡內基美隆大學近日,深入探討Google Gemini語言理解和產生能力,並與OpenAI GPT系列比較,得到有趣結論:Google Gemini綜合表現與ChatGPT仍有差距。
一,Gemini僅能與GPT-3.5 Turbo比
CMU研究探討兩個問題:
- 比較OpenAI GPT和Google Gemini能力,並提供可重現程式碼和完全透明結果。
- 深入研究後,找出兩模型某類的優勢領域。
研究團隊以分析推理、回答基於知識的問題、解決數學問題、語言翻譯、生成程式碼及充當指令遵循代理,測試各種語言能力的十個資料庫。所有基準測試任務基礎上,CMU團隊發現:
Gemini Pro模型大小和種類與GPT 3.5 Turbo相當,準確度也相當只略遜;與GPT 4比較則差很多。
Gemini Pro平均表現略低於GPT 3.5 Turbo,尤其多選題回答順序偏差、多位數數學推理、過早終止智能體任務及因激進內容過濾導致回答失敗等。特別長且複雜的推理任務,Gemini表現優於GPT 3.5 Turbo,如產生非英語語言及處理更長、更複雜的推理鏈。不過濾答案的任務,Gemini也擅長使用多種語言。
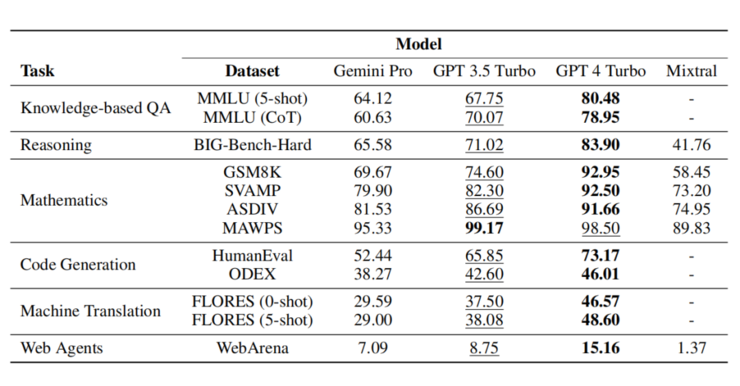
▲ 基準測試結果。最佳模型以粗體顯示,次佳模型以下劃線。Mixtral只評估部分任務)。
二,大模型關鍵能力分析
大模型幾項關鍵能力結果如下:
知識圖譜問答能力
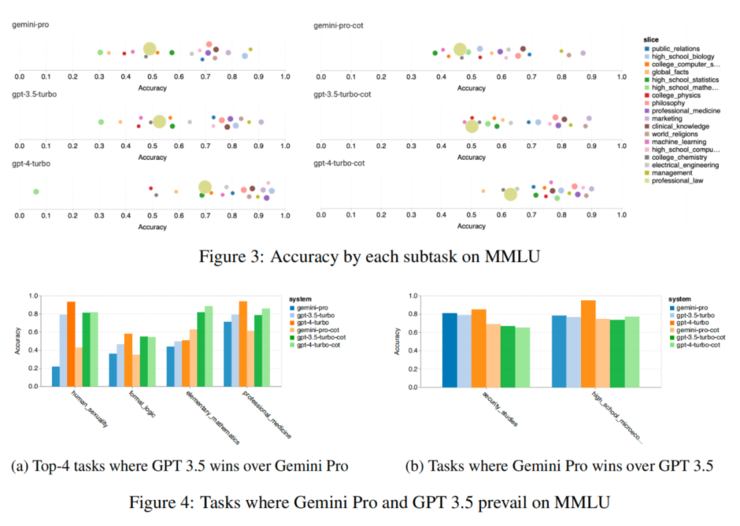
可看出每個模型部分代表性任務表現與GPT 3.5比,Gemini Pro多數任務表現不佳,思維鏈提示降低各子任務的差異。深入研究Gemini Pro表現低於/優於GPT-3.5的差距,得出結論:
- Gemini Pro在human_sexuality(社會科學)、formal_logic(人文科學)、elementary_mathematics(STEM)和professional_medicine(專業領域)落後GPT 3.5。
- Gemini Pro優於GPT 3.5 Turbo的兩個,Gemini Pro只取得微弱的優勢。
推理能力
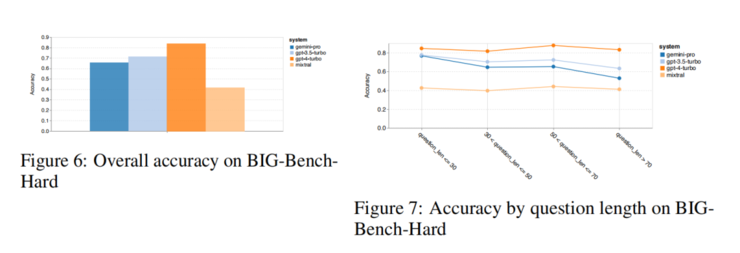
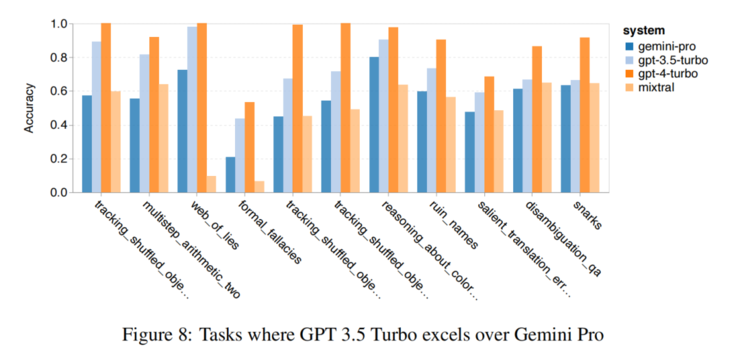
推理層面,Gemini Pro整體準確率略低於GPT-3.5 Turbo,遠低於GPT-4 Turbo;Gemini Pro更長、更複雜問題表現不佳,GPT模型較穩定。也給GPT-3.5 Turbo效能超過Gemini Pro最多的任務:
數學能力
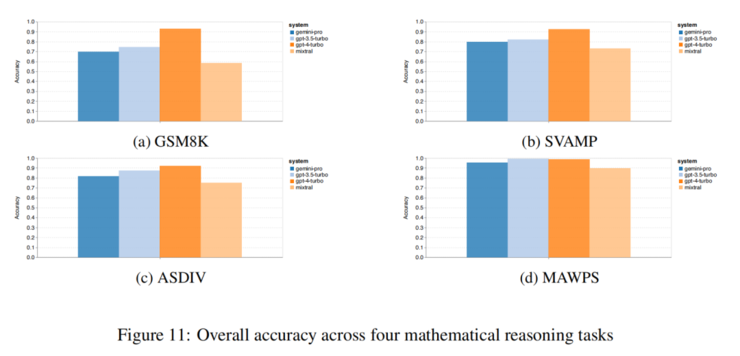
從數學推理結果可看出,多種語言模式GSM8K、SVAMP和ASDIV任務,Gemini Pro準確率略低於GPT-3.5 Turbo,遠低於GPT-4 Turbo。MAWPS任務,所有模型準確率都超過90%,但Gemini Pro仍略遜於GPT模型。
寫程式能力
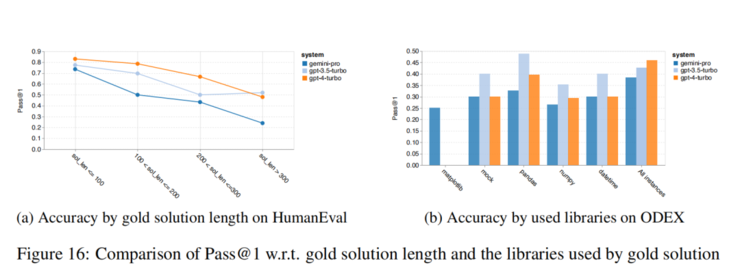
寫程式方面,英文任務Gemini Pro較長輸入和輸出表現較強。分析結果可以發現,多數使用函式庫時,如mock、pandas、numpy和datetime,Gemini Pro效能比GPT-3.5差。不過matplotlib下,性能優於GPT-3.5和GPT-4,表明Gemini透過程式執行繪圖視覺化時更強。
機器翻譯能力
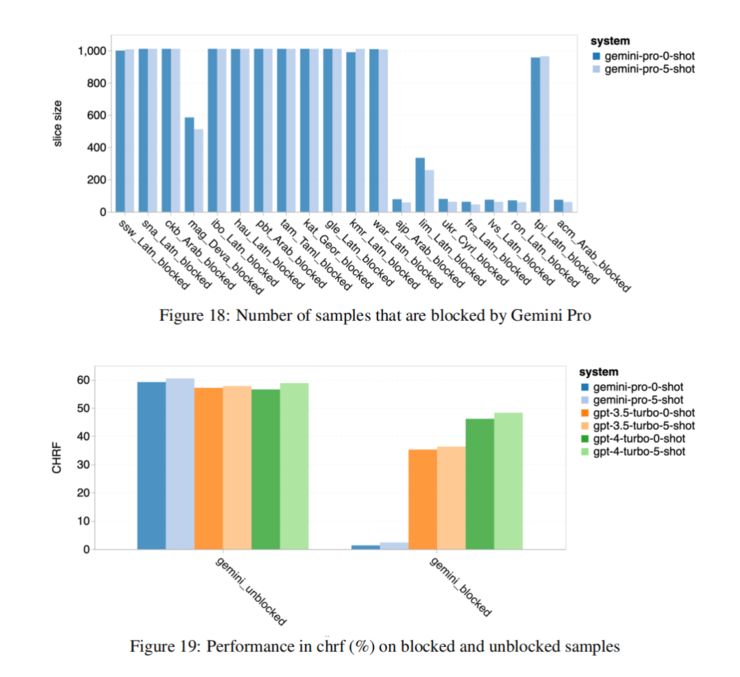
翻譯能力部分,Gemini Pro有八種語言效能優於GPT-3.5 Turbo和GPT-4 Turbo,四種語言取得最佳表現,但約十種語言表現出強烈阻塞回應趨勢。
(本文由 授權轉載;首圖來源:截圖)

標題:CMU 研究:Gemini 綜合不敵 ChatGPT,Google 還需努力
地址:https://www.utechfun.com/post/309463.html