
Chaos新觀察 No.17
大模型不是萬能解藥。
文 | 曹乙
報道 | Chaos新觀察
ID | GoChaos
封面來源 | Unsplash
“不管什么賽道,只要大廠一做,你就知道要开始卷了”——這句行業內的戲言如今正在大模型身上應驗。
自今年3月ChatGPT爆火之後,國內起了一股“備战”大模型之風,各大廠紛紛重金押注:all in AI多年的百度推出“文心一言”誓與ChatGPT一战,華爲“盤古”席卷行業,阿裏“通義千問”落地辦公領域……大模型的火熱程度,似乎爲唱衰許久“大廠流量見頂”的陰霾照進了一絲光明。
與此同時,全球大模型獨角獸企業“瘋狂吸金”,短短半年內,由前OpenAI領導人創立的人工智能企業Anthropic就連獲三輪大額融資,總額超8.5億美元。這進一步刺激了國內大模型創業,截至今年5月,中國公开發布的AI大模型數量就已近百個,單獨統計帶有 AIGC 標籤的公司,2023 年上半年融資交易 58.9 億元,事件數量 42 起,均遠超往年。
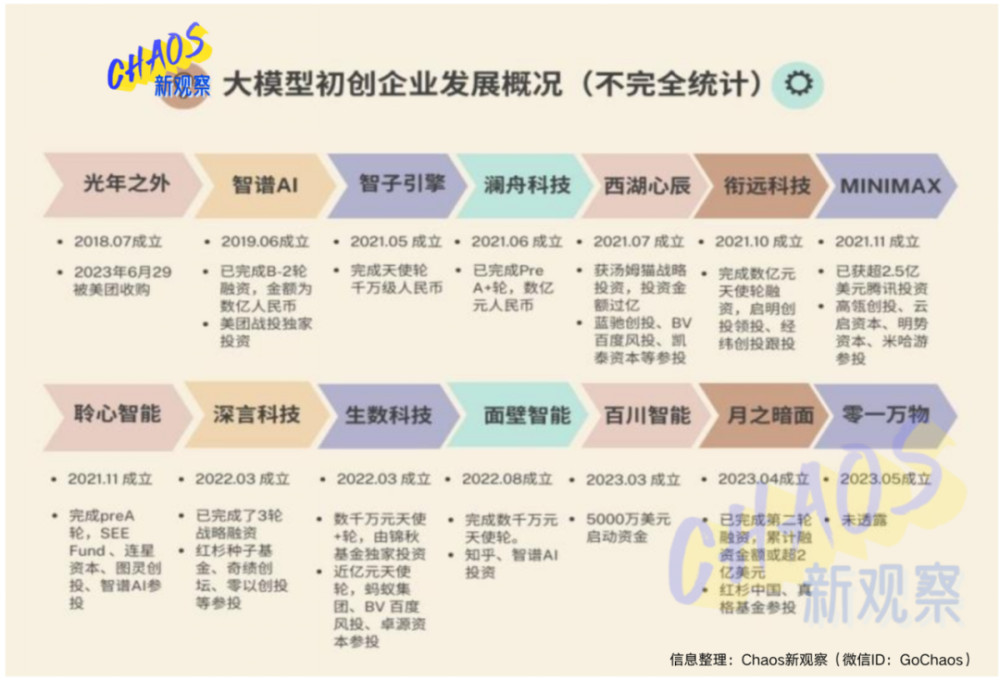
但進入下半年,行業开始逐漸降溫。盈利點不清晰,許多創業項目還停留在概念驗證階段,初創企業融資越來越難:一部分投資人舉棋不定,一部分投資人幹脆放棄看大模型項目,轉向芯片。
馬太效應正在加劇,創業公司突圍艱難。對於初創企業來說,“落地”成了重中之中。誰能推出重磅應用,或能率先殺出重圍。

大廠的“必爭之地”
大模型到底是一種什么技術?
大模型,即大語言模型,是指使用大量文本數據訓練的深度學習模型,可以生成自然語言文本或理解語言文本的含義。簡單來說,大模型能夠模擬人類學習語言的過程,以類似人類的方式理解和生成文本,是通向人工智能的重要途徑。
在ChatGPT爆火之前,人們對於AI的現實印象還停留在Siri和天貓精靈,那時人們戲稱其爲“人工智障”,意在吐槽這一時期的AI“不夠智能”。誰也沒有想到短短幾年時間,AI就從“聽懂指令”進化到“執行指令”,甚至能夠基於指令自我學習,創作文案、腳本、繪圖。
2016年,AlphaGo战勝世界圍棋冠軍李世石,曾引發人們對AI發展的短暫恐慌。但很快,消費互聯網的爆發佔據了人們的注意力,AlphaGo等機器人被認爲只能用於像下棋這樣的益智遊戲;7年後,在經歷了消費降級、人口紅利消失等危機後,ChatGPT的橫空出世,讓人們嗅到了一絲來自未來的挑战。有的大廠積極調轉車頭押注AI,有的大廠則是默默耕耘,一朝聞名。
打響第一槍的是百度“文心一言”——這是百度在2021年12月推出的百度·文心(ERNIE 3.0 Titan)迭代而來的細分模型,百度創始人李彥宏稱將用其重構百度所有的應用。6年前,百度开啓“all in AI”战略轉型人工智能,現在看來是一個十分具有前瞻性的战略。

百度文心一言發布會
作爲國內首屈一指的搜索應用,百度擁有龐大而豐富的中文語料庫,天然具有研發AI大模型所需要的深度學習基因:2019年百度與國外同期搭建了學習型的文心大模型,而後2022年上线了基於文心大模型的AI繪圖文心一格,2023年3月推出生成式AI產品文心一言......這也難怪產品一經發布,就被網友們用於和ChatGPT比較。
隨後,4月11日,阿裏雲推出通義千問大語言模型,迎战文心一言。阿裏董事會主席兼CEO張勇宣布,阿裏所有產品將接入大模型全面升級。
阿裏雲的強大算力和巨量數據正是研發大模型優勢所在,而通義千問也不負衆望地實現了衆多功能:多輪對話、文案創作、邏輯推理、多模態理解、多語言支持等功能,融入了多模態的知識理解,能夠續寫小說,編寫郵件等。日前通義千問已嘗試向辦公領域落地,接入辦公軟件釘釘,开始幫打工人“搬磚”——做ppt、表格、設計海報、撰寫文案。
緊接着,4月24日,科大訊飛星火認知大模型官網正式上线。作爲AI語音龍頭,訊飛星火認知大模型圍繞“知識問答、代碼編程、數理推算、創意聯想、語言翻譯”等場景布局,並嘗試與教育垂直場景的深度融合。
同樣在探索垂直場景的,還有京東在7月13日發布的靈犀大模型:與京東賦能產業的核心战略相同,靈犀大模型融合了70%通用數據與30%數智供應鏈原生數據,深入零售、物流、金融、健康、政務等知識密集型、任務型產業場景,解決真實產業問題。
與以上幾家正在探索落地的大廠不同,華爲的盤古大模型似乎已經找到了“落點”:7月18日,華爲聯合山東能源集團舉行發布會,宣布華爲盤古大模型在礦山領域實現首次商用,爲大模型的落地應用提供了良好的範本。實際上,盤古大模型就啓動研發,華爲雲CEO張平安表示,希望用盤古大模型幫助各行各業,例如金融、政務、礦山、氣象等行業,利用盤古大模型在產品研發、生產供應鏈、市場營銷以及數字運作領域爲其賦能——這與華爲的B端策略一脈相承。
在這場“百模大战”中,字節和騰訊兩家巨頭卻顯得尤爲低調。字節系的火山引擎6月28日發布大模型服務平台“火山方舟”,面向企業提供模型精調、評測、推理等全方位的平台服務,集成多個大模型,供客戶直接對比——大搭戲台,聚衆所長,正是字節風格;而騰訊的混元大模型,於8月3號宣布進入內測階段,主要應用於騰訊廣告、3D虛擬場景自動生成、對話式智能助手等。
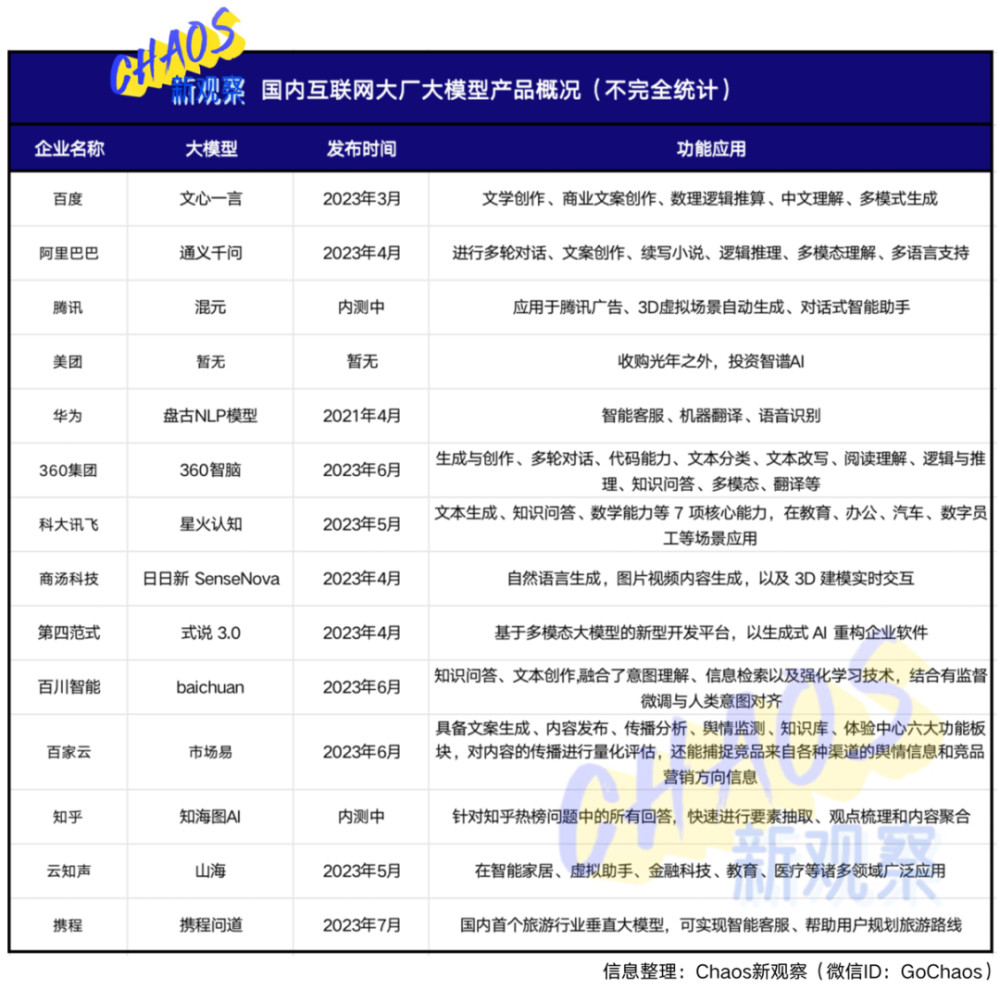
從消費互聯網時代脫穎而出的美團則選擇“燒錢”模式——前有狂砸20.65億元收購大模型創業公司光年之外,後又花費數億投資智譜AI,比起自研大模型耗費的大量人力、物力、算力和高要求的技術基礎,和創業公司合作,既可以節省時間和精力,又避免與巨頭正面競爭。
不難發現,大模型的研發具有共性:即,背後需要“巨量數據、巨量算法、巨量算力”支撐,同時還需要“巨量”人力、時間、財力的投入——這與消費互聯網時代“服務器+程序員隊伍+產品經理”搭起一個應用不同,打造一個大模型對任何企業而言都不是一件容易的事情。可以預見,未來大模型基本會成爲大平台和科技公司的專屬領地。
那么,耗費了巨額成本的大模型,能夠肩負起大廠“第二增長曲线”重任嗎?
大模型有了,應用在哪裏?
接下來要回答第二個問題,大模型究竟有什么用?
炙手可熱的同時,大模型也備受質疑:今年3月,超過千名產業界和學術界的大佬們發布聯名公告:呼籲全球所有實驗室暫停比更強的AI模型研發,暫停時間至少爲6個月。在此期間,人工智能領域的專家和行業參與者應該共同制定一套安全協議,並對技術發展進行嚴格的審查和監督。其中就包括了特斯拉 CEO 埃隆·馬斯克、以及蘋果聯合創始人Steve Wozniak。
而人們在嘗試過ChatGPT之後也發現,它所創作或呈現出來的答案並不理想,尤其是對中文語言的識別差強人意。6月份,ChatGPT網站在全球的桌面和移動端流量比5月減少9.7%,獨立訪客減少5.7%。
與此同時,使用AI所產生的倫理問題也被警惕起來。日前,黑莓公司(BlackBerry)發布了一項最新研究稱,目前全球有75%的組織,正考慮禁止在工作場所使用ChatGPT和其他生成式 AI 應用;61%正在部署或考慮ChatGPT禁令的公司表示,禁用ChatGPT的措施將是長期或永久性的。而其中被談論得最多的依舊是AI數據泄漏和隱私安全問題。
在國內,利用生成式AI詐騙的案例也層出不窮。曾有新聞爆出有受害者被AI詐騙430萬,AI換臉、AI擬聲的引起的侵權問題更是如雨後春筍。前段時間朋友圈刷屏的“妙鴨相機”也因爲隱私霸王條款和不支持退款的問題被上海市消協點名批評。
回到一开始的問題,大模型究竟有什么用?
如果說C端使用者對AI的需求仍停留在消費互聯網時代的社交、對話、聊天,那么B端才是大模型落地、“變現”的關鍵支點。畢竟,“百模大战”耗費的巨大成本無法支撐C端“注意力經濟”的玩法,只有走入垂直產業應用,才能真正讓AI服務人類。
目前國內行業大模型發展模式主要有兩種,一種是“自有通用大模型+外部行業數據”,另一種是“自有或其他开源大模型+自有行業數據”。
“自有通用大模型+外部行業數據”主要是自有通用大模型的企業以“1+N”模式拓展多個行業大模型,比如百度基於“文心”拓展了金融、醫療、傳媒等行業大模型,又如華爲基於盤古大模型拓展了礦山領域。這種模式的優勢在於,可以利用通用大模型的強大語言能力,快速適應不同行業的需求,同時也可以借助外部數據源,增強行業相關性和准確性。
“自有或其他开源大模型+自有行業數據”一般是由行業公司結合自身領域數據訓練,比如一站式AI視頻技術服務商百家雲,基於自身視頻SaaS/PaaS業務和產品數據,推出業內首款適用於企業市場部內容生產場景的GPT大模型引擎“市場易”,通過文案生成、內容發布、傳播分析、輿情監測、知識庫、體驗中心六大功能板塊,重構企業市場營銷及推廣工作機制。這種模式的優勢在於充分利用自有數據的質量和數量級,打造出更專業、更精准的行業大模型,同時也可以借鑑其他开源大模型的技術和經驗,提升訓練效率和效果。
業內人士分析,相對而言,垂類大模型在細分領域在解決數據安全隱患、缺乏行業深度等問題方面更具優勢。以AI制藥行業對大模型的需求爲例,由於藥物研發對高精度實驗數據的獲取成本較高,且公开數據庫中有大量無標注數據,因此大模型在模型建構上的要求會更高。既要利用好大量無標注數據,又要利用好少量高精度數據,這樣的需要對於通用大模型而言無疑是一種“災難”。
通用大模型研發所需要的高額成本令不少企業“望洋興嘆”,而垂類大模型則有機會填補這一空白:當前需要探索的不僅僅是讓大模型如何“海納百川”、如何“更加聰明”,更應該考量如何降低垂類大模型在訓練時間、調試成本、部署成本方面的成本,讓大模型賦能百行千業、走進千家萬戶。
關於通用還是行業大模型路徑更好,有業內人士指出,當下被鼓吹的行業大模型始終存在着被替代的風險。有業內人士表示,10年前,在語音識別技術上,也曾誕生過諸多聚焦在通話、行車、辦公等不同場景的專用模型,但隨着通用模型技術的成熟,專用模型也隨之退場。從更長遠角度看,通用大模型才真正代表着一個平台級或顛覆性的大機會。
在場景落地方面,據不完全統計,至2023年5月,Bloomberg資訊中共有58個AI應用落地案例,主要集中在傳媒、遊戲、機器人、辦公、醫藥等領域。例如Discord、Snap、BuzzFeed等廠商通過OpenAI开發自身AI產品,Meta公司5月發布的AI Sandbox大模型,可以爲廣告生成不同的文字,以迎合不同消費者的需求,目前國內企業也推出了應用。
說到底,各企業的大模型產品各有側重、內核相似,但各家的競爭力如何?這取決於客戶。
創業公司能追上大廠嗎?
用戶在選擇大模型產品時,會重點考察哪些方面?
主要從雲、基礎設施、服務等角度來看。
大模型離不开雲廠商。國內迭代最快的大模型公司,如百度、阿裏都有自己的雲業務。
大模型創業的生態分爲四層——芯片層、框架層、模型層、應用層。其中芯片層+框架層是基礎設施,企業的進入門檻最高;模型層對算力、算法、數據、人才的要求非常高;應用層是基於前兩類大模型,調用API开發應用。所有的玩家都要在這四大層級裏站位,縱向覆蓋的層級越多,競爭壁壘越深厚。
企業客戶在選擇大模型時,不能只看中技術實力,是否懂行,能否保證交付,運維有沒有長期保障,同等重要。
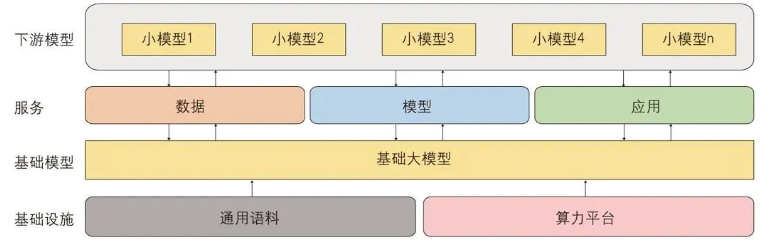
大模型框架圖
創業公司與大廠的競爭主要來自數據、算法、算力幾個維度。
有業內人士認爲,OpenAI並沒有在“科學”層面領先大家太多。模型效果更好的原因恐怕還是來源於“工藝”,追隨者能夠趕上的希望很大,畢竟數字世界的迭代速度遠超現實物理世界。
關鍵競爭點是數據質量和工程化能力,算法則可以逐步追平,創業公司或可以靠這些核心能力與大廠一战。
8月3日,阿裏大模型通義千問Qwen-7B日前宣布正式开源,阿裏雲成爲中國首個宣布大模型开源的大型互聯網科技公司。
對於正在探索大模型的中小企業和初創企業來說,Qwen-7B的出現無疑降低了他們的技術和應用門檻——开源大模型可以簡化模型訓練和部署的過程,讓用戶不必從頭訓練模型,只需下載預訓練好的模型並進行微調,就能快速構建高質量的模型。初創公司有望通過深耕細分領域拿到關鍵分。
但圍繞算力的搶奪、成本的持續增高,會成爲各家企業的共同痛點。
國內雲計算相關專家認爲,做好AI大模型的算力最低門檻是1萬枚英偉達A100芯片。TrendForce研究則顯示,以A100的算力爲基礎,GPT-3.5大模型需要高達2萬枚GPU,未來商業化後可能需要超過3萬枚。
A100愈發搶手,市面的價格开始水漲船高,從官方的1萬美元一枚,約合人民幣7萬,漲到8、9萬,甚至10萬一枚。代理商透露,英偉達A100芯片價格從去年12月开始上漲,5個月累計漲幅達到37.5%。
有媒體報道,國內雲廠商主要採用的是英偉達的中低端性能產品,擁有超過1萬枚GPU的企業不超過5家,其中,擁有1萬枚英偉達A100芯片的最多只有一家。
OpenAl則指出,AI大模型要持續取得突破,所需要消耗的計算資源每3一4個月就要翻一倍。業內指出,OpenAI每一次的訓練成本高達6000萬美元,每隔三四個月就需要訓練一次,迭代一次則需要四五次訓練。以此計算,每迭代一次技術基座可能需要2億到3億美元。
作爲大模型的主要入局者,國內互聯網大廠擁有天然的數據優勢,在算力資源上早有布局,業內人士表示,自2022年9月,美國禁止向國內客戶售賣英偉達A100、H100和AMD的MI250人工智能芯片後,國內大廠就开始大舉囤芯片。
在高額消耗面前,大廠的資金資源優勢凸顯,對於初創企業來說,只有推出“殺手鐗”應用才能在這輪AI競賽中獲得下一輪的入場券。對於大廠來說,早切入應用場景,也能早回血。
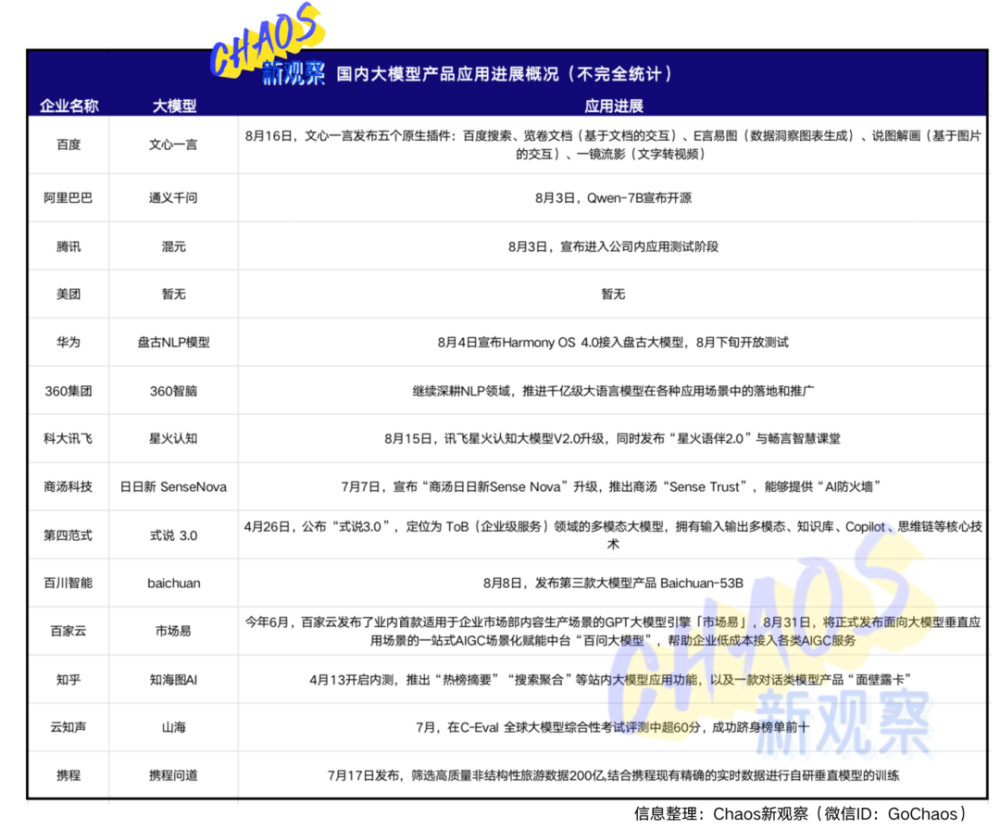
百家雲發布的適用於企業市場部內容生產場景的大模型引擎「市場易」,就瞄准了企業市場宣傳和輿情監測需求,做到“易寫、易管、易看、易聽”,並能精准捕捉競品來自各種渠道的輿情信息和競品營銷方向信息,並對內容的傳播進行量化評估,爲企業制定战略提供有力支持。8月底,百家雲宣布,基於公司多年服務线上化場景的經驗,將在現有技術積澱上,進一步幫助企業客戶構建場景化AIGC應用,打造面向大模型垂直應用場景的一站式AIGC 場景化賦能中台“百問大模型”。據介紹,百問支持私有化部署,可在企業內部完整、獨立使用,服務更穩定。
業內人士表示,目前市場中的大模型產品大多是圍繞大語言模型。但是未來,大模型一定會走向多模態,形成具備圖像、視頻、語音、語義綜合感知能力的智能體。例如,AI大模型能接入機器人,提升機器人的語言能力、視覺能力、運動控制能力,還有虛擬仿真能力。
Meta公司在今年7月發布了开源可商用大模型LLaMA2,包含了70億、130億和700億參數3個版本。人們越來越發現,比之大模型本身,它背後日漸發展並快速迭代的生態更有價值。隨着大模型开源,未來,會有更多行業、更多企業加入這場浪潮,金融、醫療、傳媒、互聯網等知識密集型行業的一些固有工作模式或將被改變,屆時,互聯網世界將迎來一次大變革。
與這些積極的聲音不同的是,一些學者認爲,大型語言模型善於從數據中識別和提取因果關系,但缺乏自己主動推理新的因果場景的能力。它們具備通過觀察進行因果歸納的能力,但不具備因果演繹的能力。
AI 可能無法真正“學習”,而只能提煉信息或經驗。AI 不是形成一個全面的世界模型,而是創建了一個概要。從這一點看,大模型可能並不是最終解。
如果我們想讓AI能夠真正通向“智能”,而不是作爲一個“信息集成器”,並且像AlphaGo那樣曇花一現的話,那么在積極探索商業落地場景的同時,不妨也想一想,我們真正需要AI做什么。
*參考資料:
1.《大廠的大模型之战:八仙過海,各顯神通》,獨角獸挖掘機
2.《ChatGPT,將遭全球 75%的企業“封殺”?》,CSDN
3.《國產大模型已無公司可投》,量子位
4.《國內外大模型產業如何發展?》,通信世界
5.《通用大模型創業潮,首战即將終結》,36氪
*免責聲明:
1、本文內容爲Chaos新觀察原創,內容及觀點僅供參考,不構成任何投資建議;文中所引用信息均來自市場公开資料,我司對所引信息的准確性和完整性不作任何保證。
2、本文未經許可,不得翻版、復制、刊登、發表或引用。如需轉載,請聯系我們。
原文標題 : AI大模型在退燒,但巨頭已經卷瘋了
標題:AI大模型在退燒,但巨頭已經卷瘋了
地址:https://www.utechfun.com/post/260854.html