
中國學術圈,又迎來一個歷史性事件。
最近這幾天在美國西雅圖舉辦的 2023 ACM SIGMOD 大會上,由阿裏雲聯合浙大提出的數據庫漏洞檢測系統 TQS( Transformed Query Synthesis ),斬獲了本屆 SIGMOD 最佳論文。

這是 SIGMOD 自 1975 年創立以來,中國大陸研究團隊首次獲此殊榮。
可能有些朋友不太了解 SIGMOD 是什么,它是計算機數據庫領域三大頂級會議之一,其它兩個分別是 VLDB 會議( Very Large Data Bases )以及 ICDE( IEEE International Conference on Data Engineering )會議。
在這三個頂級會議之中,SIGMOD 的重要程度最高,論文錄取難度最大,平均錄取率只有 17% 左右,由此可見獲得本次最佳論文的含金量了。
而這次的 TQS 之所以能夠獲獎,審稿人給出的原因是:
它優雅、有效地解決了現代數據庫管理系統( DBMS )的關鍵問題之一——在執行連接查詢( Join Queries )中 Debug 那些復雜邏輯漏洞,並在开源的、業界領先的系統中證明了 TQS 的能力。
那這個數據庫管理系統到底有多重要?爲什么解決了其中的邏輯漏洞就能拿到頂會的最佳論文呢?
咱們得先聊聊數據庫是什么。
構築起當今這個信息時代的,有三大核心基礎技術,它們分別是操作系統、芯片技術以及數據庫。
操作系統和芯片的重要性不必多說,大家應該了解程度比較高。唯有其中的數據庫技術,平常在媒體的宣傳中也不是那么多,憑啥它也是三大核心技術呢?
因爲在計算機中,不管是什么應用,都離不开存儲數據的需求。
隨着數據量的愈發龐大,如何有組織地儲存這些數據,方便檢索和讀取,就成了一件非常重要的事情。
於是數據庫以及數據庫管理系統,就誕生了。
數據庫就像一個大倉庫,存儲數據時,數據都會按照不同數據庫設定好的分類方式進行分類存儲,以方便索引。
比如最早期的層次數據庫,數據都以樹狀結構互相聯系,層層遞進。
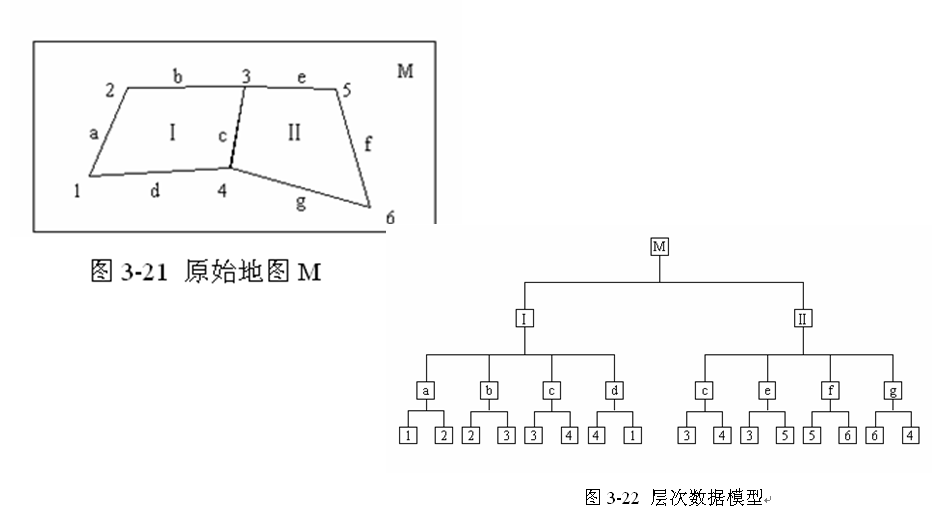
網狀數據庫則相對復雜點,數據不拘泥於層層遞進的效果,而是有多點聯系。

而現在使用最多的關系數據庫,數據之間是以行和列的形式存儲,整個數據類型更像是一個二維表格的集合。
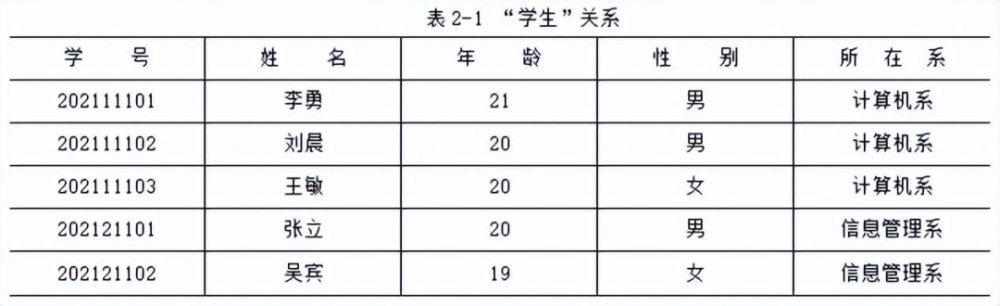
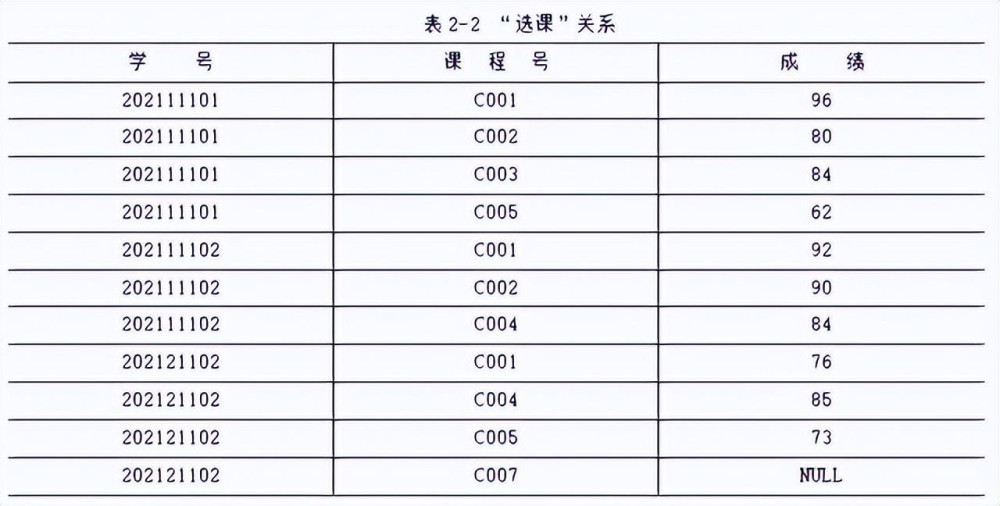
有沒有數據庫,在對於數據的存儲和索引上,需要的時間可能相差巨大。
打個簡單的比方,有兩個倉庫,第一個只是單純的文件系統,第二個是有數據庫的。
當我們往第一個倉庫存放東西時,由於沒有數據庫以及相應的管理系統,倉庫員工只能自己把東西隨地擺放,或者按照他自己的想法分一個簡單的類。
等到所有倉庫空間都擺滿了,這時如果有人想要從倉庫裏找出相對應的物資時,他得從一大堆物資中一個個翻找,或者憑借記憶想想自己之前放的大概位置,此時查找一個物資有可能花上個一天才能找到。
而有了數據庫之後,這個倉庫就有了自己的物資擺放邏輯,比如第一排擺電子設備,並且按照電子設備的品牌和類型分門別類的擺放,第二排擺書籍,按照書籍類型和首字母順序來放。
這樣,當我要查找某個類型時,直接按照索引找到那個物件的位置就好,省時又省力。
但,只要是系統,就有一定的概率出錯,數據庫管理系統也是一樣。
而且隨着應用的復雜程度增加,對 DBMS 的安全性能需求也愈加的變高,因爲一個看似很小的數據庫漏洞,帶來的結果往往非常嚴重。
在今年的一月份,美國聯邦航空管理局就因爲系統出現故障,導致全美境內上萬航班停飛。
原因就是數據庫其中的一個文件損壞。
所以如何測試以及發現 DBMS 中的 Bug,也是 DBMS 开發中極爲重要的一環。
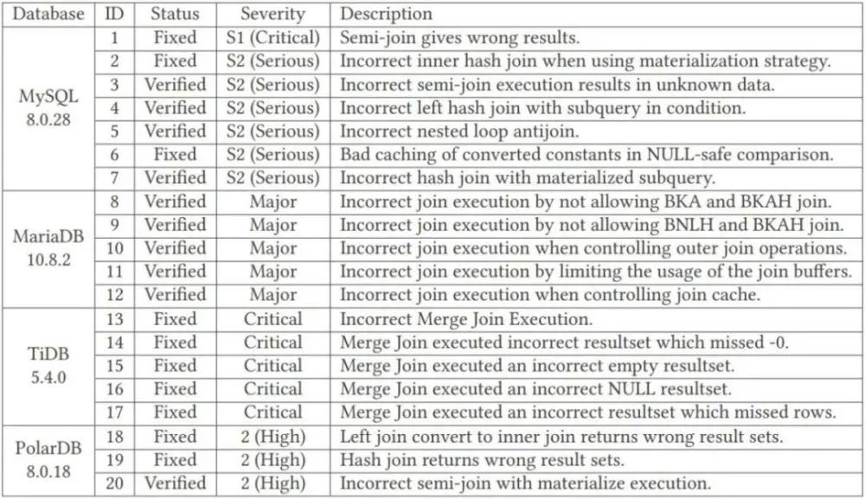
通常,在 DBMS 常見的查詢錯誤中,會有兩類 Bug。
一類是系統崩潰錯誤( Crash Bugs ),另一類則是邏輯錯誤( Logic Bugs )。
系統崩潰錯誤就是指在查詢過程中整個系統直接崩潰停止,這類 Bug 易於檢測和發現,畢竟整個程序都給你停了,是人都能反應過來。
而第二類邏輯 Bug,則危險的多,這類 Bug 是系統正常運行,但是當你查詢時,會返回錯誤的結果集,在沒有額外的數據核對的情況下,這種錯誤往往很難被發現。
比如下面這段代碼。

第一個查詢使用嵌套循環連接 ( Block Nested Loop Join ) 執行,返回正確結果集。
第二個查詢使用內部哈希連接 ( Inner Hash Join ) 連接時,因底層斷言 “ 0 ” 與 “ -0 ” 不相等,返回一個錯誤的空結果集。
最近,一種頗有成效的邏輯 Bug 檢測方法 PQS( Pivoted Query Synthesis )被提出,這種方式會在表單中隨機選擇一行,然後對這行的數據進行構造一系列的數據查詢,假如查詢的結果不包含該行數據,則表示有邏輯 Bug。
但這種方式目前更關注單表查詢,對於不同的連接算法和結構構成的多表查詢,目前還有大量的研究空白。
而本次的獲獎論文就是發明了一種新的數據庫測試方式( TQS ),能夠快速的發現 DBMS 中針對連接優化的邏輯錯誤。
想要查找出數據庫中的邏輯錯誤,面臨的最重要的挑战主要有兩個。
一是如何構建查詢真值, 以進行准確的查詢執行正確性驗證。
二是探索空間問題,隨着表單的數量增長,遍歷的所有可能的查詢數量會成指數級增加,這種情況下,短時間內無法列舉所有可能的查詢進行驗證。
針對這兩個問題,TQS 都有相應的解決方法,首先是構建真值問題,TQS 會把給定的寬表( 簡單理解就是數據量很多的表 )拆分成多個較小的表,並且插入一些噪音數據作爲邊緣測試的樣本。
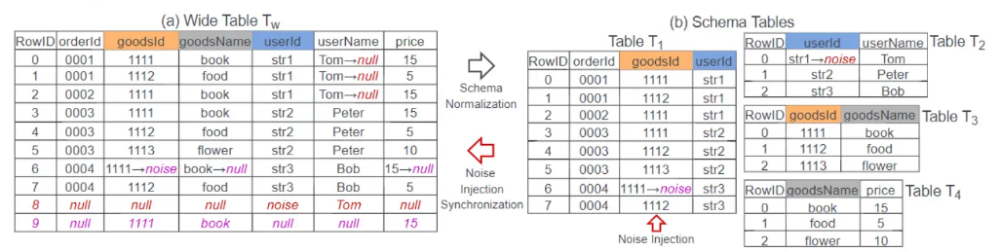
同時,對這個表單構建索引,並對增加的噪音數據進行更新。
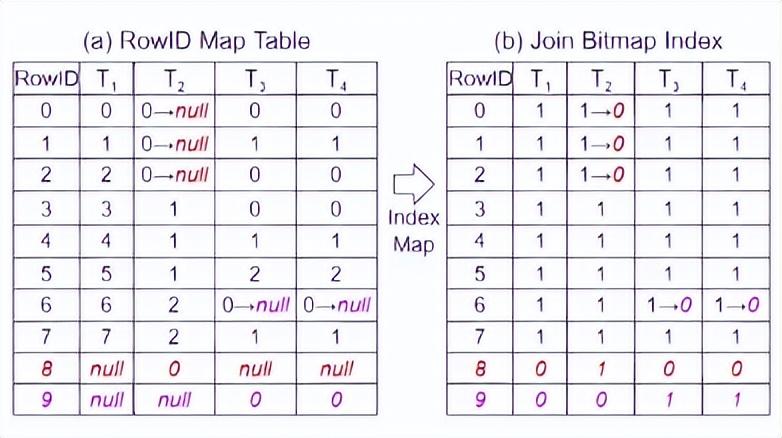
然後,基於這個數據庫的圖模型,生成一系列隨機的查詢請求,最後把查詢結果和直接在寬表查詢到的理論真值進行比對,如果都對上,則說明沒啥問題。
這種通過一張表來構築多表模型的方式,成功解決了多表模型中無法獲取正確真值的問題。
簡單的用人話解釋,因爲傳統的測試方式中,沒辦法知道多表任務中查詢的結果是真還是假,那我就把一張大表拆成幾個有聯系的小表,這樣我就可以通過查詢大表數據獲取正確的理論數值,這樣就能來對比測試多表查詢中的結果是不是對的。
對於探索空間,TQS 則主要注重於避免重復度過高的查詢。首先 TQS 會將模式圖擴展成計劃迭代圖表示整個查詢空間。如圖所示,每個節點代表着不同的行和列。
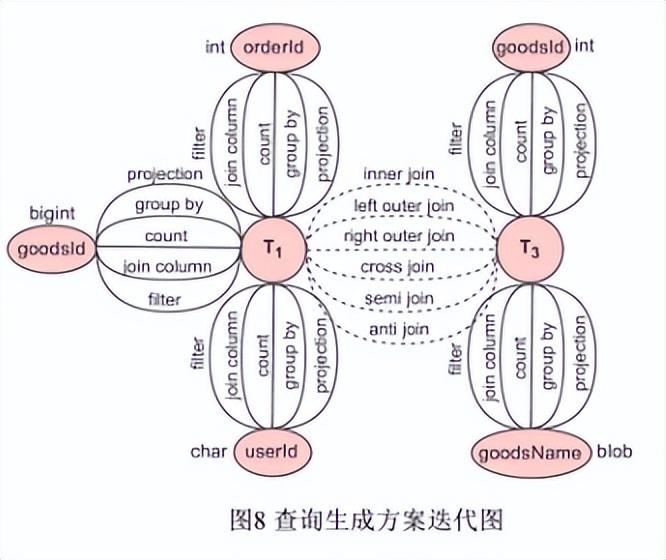
隨後構建索引以支持各種查詢連接操作。在查詢任務中,主要特別關注查詢連接部分的邏輯錯誤檢測。
同時建立圖索引以進行檢索。這樣,就可以確定當前生成的查詢是否已經被搜索過,即已經進行過檢測。如果查詢已經被檢測過,就沒有必要再次進行檢測。
一句話解釋,就是盡量測試那些不同類型的查詢方式,相似的查詢任務,就不查了,這樣就大大減少需要查詢的任務數了。
這兩個問題解決了,那么 TQS 它在實際測試中,結果如何呢?
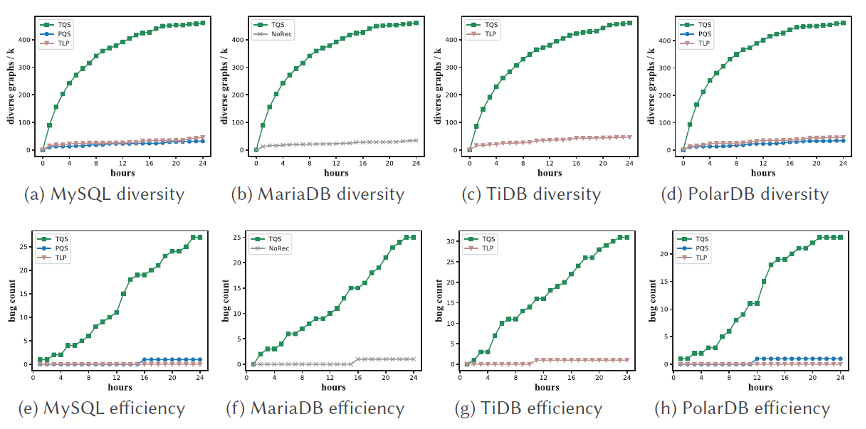
作者使用 TQS 在 MySQL、PolarDB 等四種數據庫上進行了 24 小時的數據庫測試後,一共檢測出了 115 個邏輯錯誤,其中 MySQL 31 個、MariaDB 30 個、 TiDB 31 個、PolarDB 23 個。錯誤類別總共 20 類。
在和傳統的 PQS、NoRec 以及 TLP 兩類測試方式效率對比上,TQS 也是遙遙領先。
值得一提的是,本文是阿裏雲與浙大的聯合研究成果。一作浙大唐秀博士,正是在阿裏雲研究型實習生期間,主導完成了這一成果。而另一作者李飛飛,是阿裏雲數據庫負責人,也是業界大拿,曾以一作身份獲得 2016 年 SIGMOD 最佳論文獎。
有意思的是,這次選題的提出,還是源於阿裏雲瑤池數據庫團隊內部的一次 PolarDB 雲原生數據庫內核測試,當時就組織了會議討論這個邏輯漏洞如何檢測的問題,大家夥對這個尋找 Bug 的過程都很感興趣,於是着手开發自動化數據庫邏輯測試工具,檢測出 50 余個程序錯誤,總結並提交相關程序錯誤信息,形成了這一成果。
其實在數據庫這一領域,學術界和工業界的聯系是非常緊密的。畢竟數據庫這一技術源於現實需求,學術界所研究的問題,基本都是來自現實中所遇到的需要解決的 Bug 和需求。
而阿裏雲數據庫能夠在學術界上取得如此突破性的成就,正是因爲阿裏雲在工業規模上夠大,對數據庫的安全需求夠極限。
另外,阿裏雲瑤池數據庫團隊在公共雲上爲百萬量級的客戶提供數據庫服務,這些來自各行各業的用戶,在雲數據庫中運行着多種多樣的 SQL 查詢請求。
而研發一套確保所有 SQL 運行正確性和高性能的系統,具有非常大的挑战,該次 Best Paper 的研究目標即着眼於解決這一問題。
換句話說,也只有阿裏雲瑤池數據庫這一規模體量下才能誕生出這樣的技術挑战以及對該解決方案進行實驗驗證的土壤。
以往,在數據庫領域,一直都是外企獨大,自 1982 年甲骨文推出 Oracle 系統之後,甲骨文在數據庫系統上一直都處於世界領先地位。
隨着時間的推移,數據庫系統也從離线本地的线下部署方式,轉爲了雲數據庫。
而在國際市場研究機構 Gartner 發布的《 2022 年度全球雲數據庫管理系統魔力象限報告 》 中,全球領導者象限的前四位都是外企。
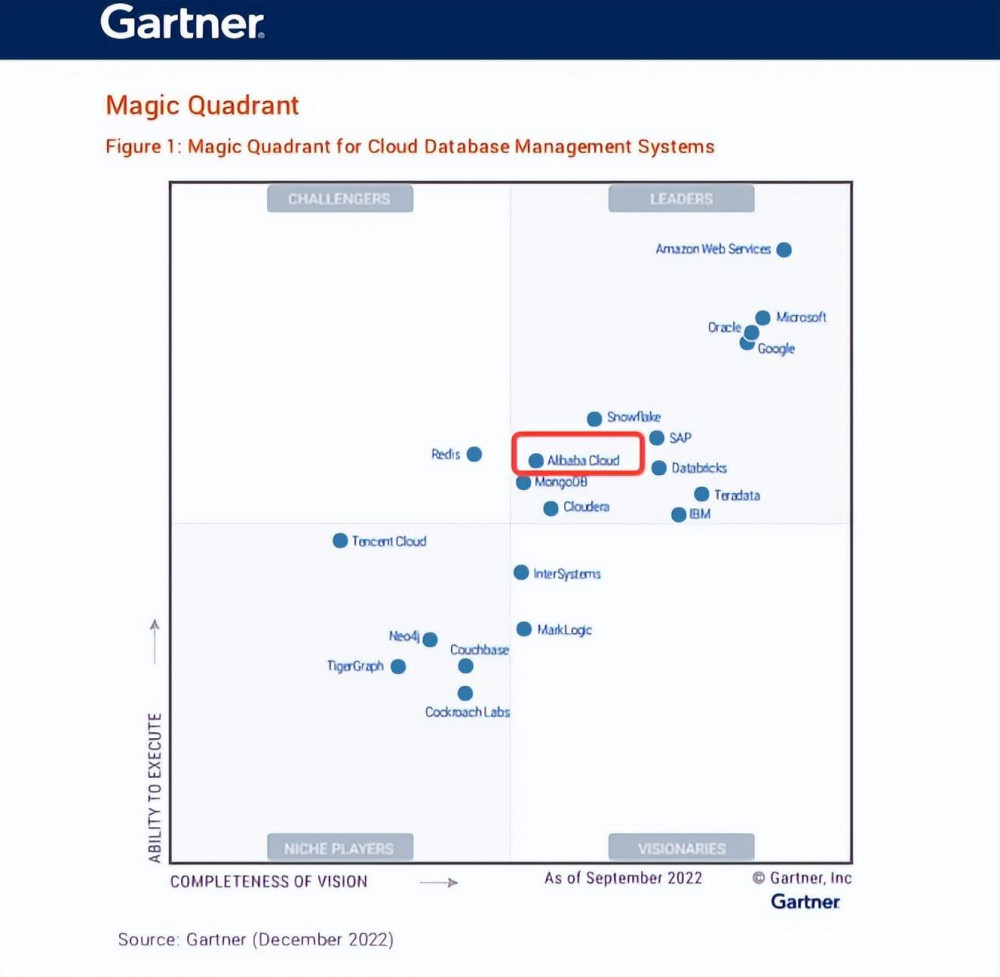
不過,在第一象限( 領導者象限 )中,你也能發現像阿裏雲這樣的國內廠商,並且,阿裏雲還是國內唯一、連續第三年入選該報告 “ 領導者( LEADERS )” 象限的服務商。
如果我們再翻翻阿裏雲在數據庫上的學術成就的話,就能知道這些成就的得來離不开阿裏雲數據庫長達 10 余年的持續深耕。
2022 年,在數據庫三大頂級會議上,阿裏雲數據庫團隊就有 17 篇論文入選,成果覆蓋雲原生、分布式、智能化、安全可信、時序時空等數據庫前沿研究方向。
2023 年至今,不過半年時間,更是有 18 篇論文入選,其中還包括一篇 SIGMOD 的最佳論文。
要說阿裏雲數據庫團隊的科研實力全球領先、中國第一,那還真的不算吹。
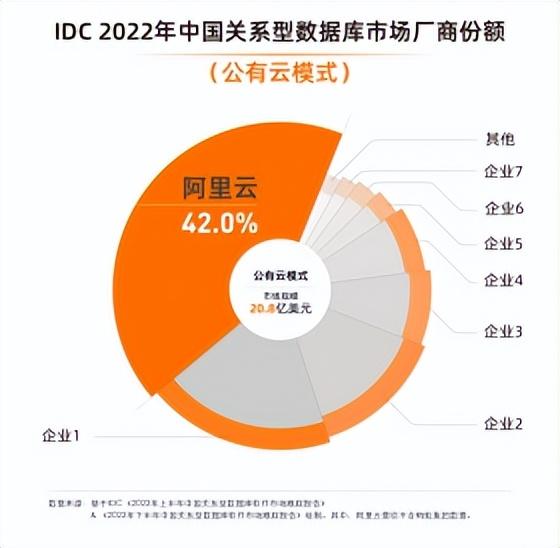
在市場佔有率上,阿裏雲佔據主導地位,在公有雲部署市場上,阿裏雲以 42% 的份額連續 4 年蟬聯第一,市場份額大於 2 到 4 名的總和,持續彰顯領先優勢。
畢竟只有技術先進才能贏得市場。
正是有了學術界如此多的成果,阿裏雲才能在全球的數據庫市場中,擠出自己的領導者地位。
很多人認爲,現在的社會是一個 AI 的時代,但,這同時也是一個數據的時代,沒有先進的數據處理,前者就不會存在。
其實不只是 AI,不誇張地講,基本所有現代科技,都建立在數據之上。
所以,我們需要更多 TQS 這樣的成果,也需要更多阿裏雲這樣的公司。
數據庫這種和芯片以及操作系統同等重要的技術,應該牢牢把握在我們自己手中。
本文作者可以追加內容哦 !
標題:斬獲頂會最佳論文,阿裏雲和浙大給數據庫帶來了些新思路
地址:https://www.utechfun.com/post/228342.html