OpenAI的最新技術成果——文生視頻模型Sora,在春節假期炸裂登場,令海內外的AI從業者、投資人徹夜難眠。
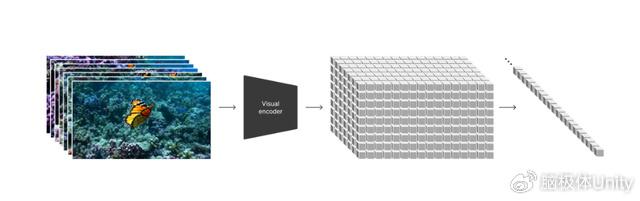
如果你還沒有關注到這個新聞,簡單介紹一下:Sora是OpenAI使用超大規模視頻數據,訓練出的一個通用視覺模型,可以理解和模擬運動中的物理世界,生成不同時間、縱橫比和分辨率的視頻,最大版本的Sora能夠生成長達一分鐘的高保真視頻。

Sora發布之前,也有許多採用各種方法的視頻生成模型,但都使用較少的視覺數據,只能生成較短(4秒)或固定大小的視頻。所以,Sora逼真的視覺效果、碾壓級的性能提升,在震撼整個科技圈之余,也導致了“中國AI焦慮症”的人傳人現象。
廣大網友們再一次痛心疾首,對中國A發出質問:
爲什么又一個AI元創新沒能發生在中國?我們點錯了科技樹,好難過;
中國跟美國的AI差距越來越大,Sora這波國內慢了十年吧?這下真跟不上了;
復制Sora算力是最大阻礙,從芯片禁運开始咱們就完敗了,沒戲了。
當然也不乏陰陽怪氣的,“等國外的類Sora模型开源,國內AI公司就又能創新啦”。

在中美對弈的時代背景下,上述焦慮情緒,每一次在海外科技取得重大突破的時候,都會蔓延开來。但時間證明,作爲全球唯二的AI大國之一,中國發展了多年AI技術,就算美國真有什么新AI成果是其他國家做不了、趕不上的,那也絕對不是中國。
拿並不遙遠的ChatGPT來說,經過一年狂奔,“中國有沒有自己的ChatGPT”已經不再成爲問題。2023年很多國產“類ChatGPT”大語言模型已經向公衆开放使用,走進行業場景,有數億用戶檢測過中國AI的真實水平,或許與OpenAI還存在差距,但肯定不是一些人擔憂的那樣,認爲“中國做不到”“技術有代差”。
這就像我們經常會看到一類“震驚體”新聞,一種新藥問世,就說人類離永生不遠了;一個AI突破,就說AGI要實現了,人類要被毀滅了。讀者在這些奇談怪論中“死去活來”,對AI的認知也在“成神”和“騙子”之間反復橫跳。而真正懂藥的人,肯定不會相信一種藥能包治百病,而是搞清楚療效和副作用,在對應的症狀上使用。
同理,真正了解AI產業的人,也能正視中國AI的長處,承認現實差距,不卑不亢,積極應對。
尤其是經過了ChatGPT的“練兵”之後,這一次我們應該更有底氣,客觀看待Sora對中國AI帶來的真實變化,准備迎接又一個“AI之春”。
變化一:拉近差距
在“ChatGPT爲什么沒有誕生在中國?”之後,龍年版本已經成了“Sora爲什么沒有誕生在中國?”接連兩次錯失“元創新”,讓期待中國AI“彎道超車”“後來居上”的急性子讀者,大感失望。
科技發展從來不是一步登天,現實並沒有爽文小說中逆襲打臉的“金手指”,只能是一步一個腳印邁進。不能否認,大語言模型、文生視頻模型的顛覆性產品,沒有首發在中國,但也必須看到,中國AI一直都在正確的道路上,並且腳步在加速。

Sora的發布,反而會讓中美AI的距離進一步拉近,原因有三:
首先,方向一致。
錯過一場技術革命,最可怕的不是來得晚,而是點錯技能樹,比如歷史上日本大力發展的“五代機”,選錯方向就錯過了一個時代。OpenAI的ChatGPT、Sora都是在大規模預訓練模型的技術路徑上,進行大量的工程實踐創新。由此可見,一項新突破,技術積累、技術選型是十分重要的,而這條以Transformer架構爲主的“大模型之路”,中國AI一直在持續跟進,基礎設施和算法層面的堅實程度是肉眼可見的。
其次,目標明確。
OpenAI的元創新讓人應接不暇,處於全球AI領先地位,中國AI企業確實與其存在差距,始終在追趕。但這並不是諷刺中國AI的理由。“沒有從頭發明xx技術”,並不代表不優秀,OpenAI也不是Transformer發明者。而且,OpenAI本身就是一家集合了全球頂尖人才、力量與資本的特殊AI公司,就連谷歌都跟在後面屢敗屢战,用OpenAI的標准去要求各方面資源受限的中國AI產學研機構,其實是不公平的。
Sora明確了,“視頻生成模型是一條構建物理世界通用模擬器的有效路徑”,印證了暴力計算的又一次勝利,“Scaling Law”大力出奇跡的湧現效果,相當於爲中國AI領域完成了“探路”。有了清晰的追趕目標,中國AI各界反而能快速整合資源、投入研發,從而進一步拉近中美在文生視頻上的距離。和ChatGPT一樣,中國AI做出“類Sora”也是必然的,絕不可能錯過這一波或者徹底跟不上。
最後,能力具備。
或早或晚,中國一定會做出“類Sora”,但到底是三年後、五年後,還是十年後?我們認爲,2024年應該就會看到國產Sora問世。無論是Sora所用到的基礎模型LLM、文生圖模型DALL·E 3、大規模視頻數據集、AI算力體系、大模型开發工具棧等核心基礎設施,中國都已經具備。比如原創的基礎大語言模型文心一言、訊飛星火、BAICHUAN等,以及文生圖模型文心一格、騰訊混元等,加上過去一年大模型存算傳基礎設施的突飛猛進,有能力和條件支持中國AI修成正果,在視頻生成賽道再現 類ChatGPT 式的成功。
面對Sora,中國AI努力追趕是必須的,但數一數行囊中的工具和果實,不必妄自菲薄,更不用亂了陣腳。沿着正確且清晰的道路,加速向前跑,中美AI的差距才能縮小。
變化二:國產大模型格局再優化
和LLM一樣,不會出現Sora在全球一枝獨秀,而國內卻無視頻生成模型可用的情況。衷心希望,我們在不久的未來,不會像LLM百模大战一樣,從擔憂“中國沒有Sora”,轉而擔憂“中國要那么多Sora怎么用”。
從這個角度看,OpenAI從ChatGPT到Sora的持續輸出,會讓國內AI大模型市場少一點虛火,多一分理性。
少一點虛火,是指底層模型的重要性,被Sora再一次“劃重點”,避免國產大模型低水平的重復建設。
2023年一個又一個大語言模型被訓練出來,推向市場,其中原創性的基礎模型佔比最小,更多是行業大模型,以及很多私有化部署的大模型,在數據規模、參數規模上無法與基座模型相提並論,生成效果也會差很多。這種低水平的重復建設,也會造成AI算力、投資的浪費。
而Sora在視頻領域的驚豔表現,再次證明了暴力美學的有效性,將曾經大火的AI視頻創業公司的模型直接碾壓。正如OpenAI CEO奧特曼在YC W24 啓動會上的演講中所說:最正確的做法是設想一個“上帝般的”模型正在運作,然後基於這種設想來構建最好的產品。

對中國AI來說,將爲數不多具有底層原創能力的基座模型,如文心、星火等,作爲大模型基礎設施與支柱,支持初創企業和千行百業做好精調、優化,避免“重復造輪子”,是非常重要的。
多一分理性,是在被Sora驚豔的同時,也要想到應用和商業化的漸進性,以更合理的方案來進行國產類Sora的开發。
類ChatGPT的大語言模型在狂奔一年之後,在與各個行業結合的過程中,已經暴露出實際應用場景局限、商業價值雖有但不多、大模型投入產出比較低的挑战。如何用好大模型,已經成爲中國AI的關鍵考驗。
相比“人人皆可上手”的大語言模型,視頻生成模型的應用門檻更高,受衆群體更小,目前OpenAI僅开放給創作者使用,而非像ChatGPT那樣开放給大衆。不難看到,視頻生成模型從研發到落地,整個過程會更加緩慢,應用潛力與商業出口還有待探索。
這一方面留給中國AI產學各界了較長的追趕窗口期,同時,由於Sora能夠激活多大的商業價值尚不明確,除了字節跳動、流媒體平台等要全力投入,其他科技企業和初創公司都要考慮到商業化的問題,爲創作、商用場景打磨好工具,做好視頻生成模型的提示詞工程,以便非專業背景的廣大行業用戶們上手使用。
大模型的價值需要商業化來證明,Sora也不例外。視頻生成模型走向行業的長跑,才剛剛开始。在更廣袤的產業空間裏,如何讓類Sora產品帶來真實價值,這個答案OpenAI沒有給,美國AI不會給,只能由中國AI自己來書寫,而這也是國內更勝一籌的地方。
變化三:長期動能的查漏補缺
不必焦慮Sora,並不意味着中國AI就能躺平“坐看雲卷雲舒”了。必須承認,國產大模型還有很多瓶頸尚待解決。
Sora模擬物理世界的通用能力,不僅可以用於影視制作等內容創意行業,還可以爲遊戲、自動駕駛、工業數字孿生、電商、文旅等各行各業,提供一個構建敘事融合世界的技術支柱。
那么問題來了,國產Sora一定會出現,但我們做好各行業規模應用Sora的准備了嗎?恐怕今天的答案還是,沒有。
前面提到,Sora的“暴力美學”再次證明了Scale的價值。而要達到湧現效果,基座模型仍然高度依賴於大量高質量數據集,超大規模算力,大量工程化調優人才,以及由此帶來的巨大开發及運行成本。
即使背靠微軟雲的OpenAI,也沒有面向公衆开放使用Sora,也沒有向开發者开放API接入,就連正式开放使用的時間表都欠奉。國產AI本就存在的專項算力緊缺問題,在Sora問世之後變得更加緊迫。
同時不難預料,爲了進一步阻截中國AI的發展,圍繞AI算力的新一輪限制一定會來。完善和發展AI基礎設施,構建自主可控的產業鏈,讓大語言模型、視頻生成模型等新AI技術都不缺席中國式現代化的進程,讓算力成爲中國數字經濟長期發展的動能,中國計算行業依舊重任在肩。
此外,在中美AI差距中,數據的規模與質量成爲越不過的門檻。2023年5月英國《經濟學人》提出,中國在建立基礎模型方面比美國落後兩到三年,造成這一差距的首要原因就是數據,AI模型在訓練時難以充分利用互聯網內容。
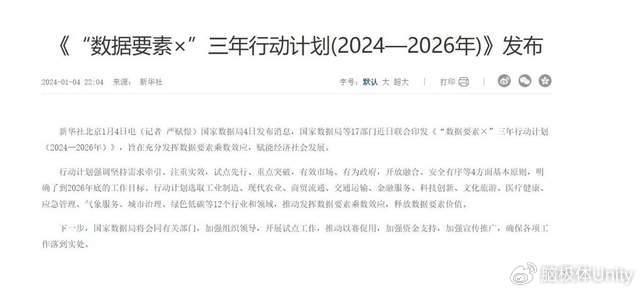
針對這一現狀,2023年12月15日,國家數據局同中央網信辦、科技部、工業和信息化部等17個部門聯合印發《“數據要素×”三年行動計劃(2024—2026年)》,目標是到2026年底,數據要素應用場景廣度和深度大幅擴展。2024年,我們一定會見證該行動的推進與落地,見證數據要素成爲國產AI的養料。
由此可見,中國AI的查漏補缺,不是一朝一夕的事,也不是某一家AI企業、某一個模型廠商的事,面對已經在行動的中國產業各界,何妨多一些耐心。
智者不惑,仁者不憂,勇者不懼。正視Sora給中國AI帶來的變化與挑战,不爲一時的缺席而焦慮,是相信我們有能力登場,也終將登場。
標題:Sora給中國AI帶來的真實變化
地址:https://www.utechfun.com/post/334053.html