
近來一波波影像生成模型出現,無論是貼近提示要求或在影像處理細節上,許多情況下展現出令人驚豔的高品質。Google 也不甘示弱,日前發表自主開發的大型語言模型 VideoPoet。
為了探索語言模型在影像生成中的應用,Google 引進全新大型語言模型 VideoPoet,能夠執行包括文字轉成影片、圖片轉成影片、影片風格轉換、影片修復、影片生成音訊等五大功能,而且預設產生直式短影音。
比方說,文字提示輸入「兩隻熊貓打撲克牌」,VideoPoet 產生兩隻熊貓坐在桌邊打撲克牌的短片。圖片轉成影片方面,像是上傳一張油畫圖片,畫中一艘航向大海的船遭遇雷電交加、波濤洶湧,藉由 VideoPoet 可以轉變成動圖型態。VideoPoet 也能為影片產生音訊,例如先以模型產生 2 秒短片,並嘗試在沒有任何文字提示下配上音訊,於是從單一模型就能產生影片和音訊。
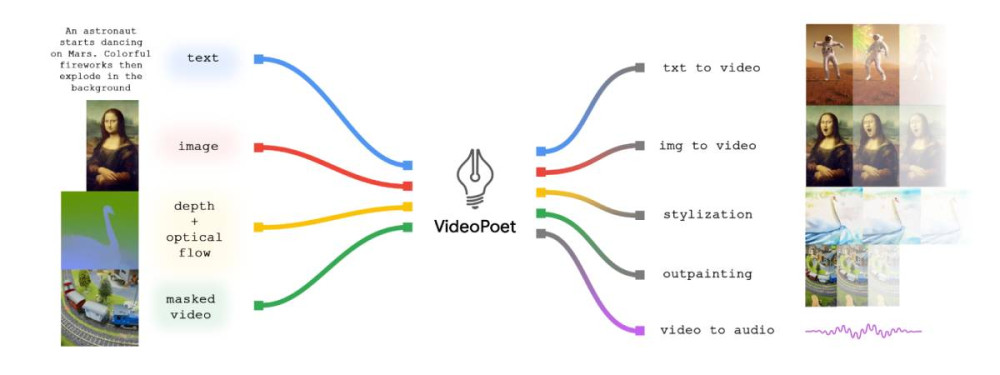
▲ VideoPoet 五大功能概述。
VideoPoet 是訓練一個自回歸語言模型,透過使用多個標記器(用於影片和圖片的 MAGVIT V2,以及用於音訊的 SoundStream)學習影片、圖片、音訊、文字形式,像是透過文字和圖片輸入分解、標記,進而產生複雜的影像。
Google 目標希望 VideoPoet 能夠「any-to-any」,根據任何提示任意轉換,同時也要擴展至文字轉成音訊、音訊轉成影片、產生影片字幕等功能。
VideoPoet 將許多影像生成功能無縫整合至單一模型,而不是針對不同任務單獨訓練模型,特別在產生有趣影片和高品質動作上,展現出大型語言模型具高度競爭力的影像生成品質。
▲ 開發團隊製作一部由 VideoPoet 產生不同短影音組合而成的介紹影片。
(圖片來源:)

標題:Google 推出影像生成模型 VideoPoet,五大功能產生直式短影音
地址:https://www.utechfun.com/post/308938.html