採寫/萬天南
編輯/陳紀英
在懟人上沒輸過的馬斯克,其實也被打過臉。比如,在對OpenAI的輕視上。
2018年,作爲OpenAI的主要發起人之一,丟下“你們都是一群蠢貨 ”的謾罵後,馬斯克放棄了上億美金的投資承諾。
這次爽約,幾乎讓當時的OpenAI陷入絕境。
五年前看不上,五年後追不上。今年4月完成新一輪融資的OpenAI,估值達到了290億美元之巨。
馬斯克對OpenAI的輕視,以及投資大師巴菲特對蘋果、亞馬遜的一再錯過,都顯露了創新者的早期窘境——營收爆發滯後於技術成熟的時間錯位,導致其在大規模變現的奇點到來之前,逃不掉被低估、被誤讀的宿命和尷尬。
這種營收滯後技術的錯位,OpenAI也沒逃過。
爲了快速補上商業化短板,OpenAI首席執行官山姆·奧特曼定下了明年營收10億美元的硬指標。
OpenAI如此,國內頭部AI公司商湯同樣如此——商湯剛剛發布的2023年中期業績顯示,其生成式AI相關收入實現了670.4%的增長,對集團業務的貢獻提升至20.3%。
而在接下來的電話財報會議中,商湯管理層表示,生成式AI相關收入對營收的貢獻在2025年有望超過40%。
不過,其AI大模型的豐沛成果,暫時還未換來市值的重估。
如何從技術研發上的頂天立地,走向商業變現上的鋪天蓋地,盡快把變現能力與創新實力對齊,進而實現公司市值/估值的重估和回歸,已是商湯和OpenAI的必答題。
最像OpenAI的商湯,亮出AI大模型底牌
眼下,國內公司已經累計發布了上百個大模型,但炒概念的鍍金者多,高投入的煉金者少。
今年4月,商湯發布了“日日新SenseNova”大模型體系,可提供自然語言、內容生成、自動化數據標注、自定義模型訓練等多種大模型及能力。

在10000張GPU的高強度投入之上,依托於“日日新”大模型體系與商湯AI大裝置SenseCore的底座,商湯推出商量SenseChat1.0,成爲國內最早的基於千億參數的大語言模型產品之一。
到了6月,商湯聯合多家國內頂尖科研機構發布了國內第一個綜合性能全面超越GPT-3.5-turbo的基模型InternLM,兩個月後,新模型InternLM-123B完成訓練。
從縱向來看,InternLM-123B的進化速度堪稱“日新月異”,新模型參數量從1040億,提升至1230億,相比InternLM-104B參數量提升了18%。
而從橫向來看,InternLM-123B的表現也很硬核,在全球51個知名評測集共計30萬道問題集合上測試成績整體排名全球第二,超過GPT-3.5-turbo以及Meta新發布的LLaMA2-70B等模型,在主要評測中有12項成績排名第一。
值得一提的是,新模型InternLM-123B在工具調用上實現了重要升級,可使用python解釋器、API調用和搜索三類常用工具來解決復雜任務、靈活搭建AI智能體應用。事實上,能夠准確使用工具的大模型才是提升行業生產力的關鍵。
在大語言模型上,商湯選擇了閉源、开源並行的路线,各取所長。閉源可以保護公司的研發成果和技術專利,短期內商業化更具確定性。但开源也有其獨特優勢,吸引开發者和應用者蜂擁入場,加速推進大模型生態繁榮。
因此,閉源、开源長短互補,其實是當下的最優解——通過开源加快行業落地之後,商湯可以借勢提升行業Knowhow沉澱和數據配方,從而反哺於基模型的性能優化。
通過开源模式秀出實力之後,一旦這些嘗鮮的潛在用戶,需要更深度更多元的增值服務、定制服務,又會順勢轉化爲商湯的客戶。
商湯开源模式的InternLM-7B(70億參數)目前登頂多個模型測試榜單成爲性能最好的輕量級基模型。近期,商湯還將开源InternLM-20B模型(200億參數),其調用工具能力更強、運行成本較低、適合構建各類應用。
眼下,商湯的AI开源工具,已經覆蓋決策智能、大語言模型、數據平台、高性能訓練和推理框架、AI智能訓練框架等。
而在文生圖模型布局上,基於約2000張GPU的壓強式投入,商湯能力也在快速迭代。
商湯文生圖產品秒畫在今年1月开始內測,到了7月,迭代到3.0版本,基模型參數量由8億提升至70億參數,其3.0核心算法在COCO benchmark上,也超過了谷歌的Imagen與OpenAI的DALL·E 2,以及參數量更大的Meta旗下LLaMA2-13B(130億參數),出圖效果躋身全球前列。

秒畫1.0向3.0迭代
性能全面提升的秒畫4.0,則預計在今年三季度上线。
學OpenAI者衆,似OpenAI者少。堅守閉源路线的OpenAI,其實從未公开其實驗過程和數據配方,因此,要想通過臨時起意,跟上OpenAI的節奏,幾無可能。
商湯的先至,歸根結底,源於先知先發,早在5年前,商湯就通過發布計算機視覺框架模型入場,從10億參數規模的視覺模型到320億參數的視覺大模型,並以視覺爲突破口布局語言、文生圖等多模態模型。五年厚積,這是從量變到質變的漫長修煉。
“前店後廠”狂煉金,商湯大模型務遠又務實
AI大模型的競爭不在一時,而是一場考驗全棧能力的持久战。回到原點,生成式AI的智能湧現,到底取決於哪些關鍵變量和核心能力?
今年4月,商湯拋出了一個清晰的公式:計算量(GPU數量 x 運行時間 x 並行效率 )= 模型參數量 x 處理數據量。
換句話說,唯有在算法、算力、數據三個層面,面面俱長,不留短板,才能在百模大战中脫穎而出。
在算力基礎設施建設上,商湯2018年籌備落子,並在2022年投用的全國最大算力中心上海臨港AIDC持續迭代,推動SenseCore AI大裝置持續升級,上线GPU數量提升到約30000塊,算力規模從5 ExaFLOPS提升至6 ExaFLOPS。這爲日益增長的大模型訓練及推理需求提供了充沛的算力。

僅僅2023年以來,就有超過1000個參數量在數10億至上千億的大模型,在AI大裝置上完成了訓練,支持了數十款生成式AI應用。
與此同時,商湯積累的原始語料數據總體量位居行業領先。目前商湯每月產出約2萬億token的高質量數據,預計年底高質量數據儲備將突破10萬億token。
獲取高質量數據的路徑,則源於過去幾年,商湯覆蓋To B、To C 、To G多個行業和場景的服務的長期積澱。
打深基,砌高樓,扎實搭建的基礎設施,疊加深扎行業的knowhow沉澱,才能支持大模型成果的持續湧現。
而AI大模型能力,也在全面賦能商湯各業務板塊。
當下,商湯已經推出了六大生成式AI產品矩陣:AI聊天助手商量,已經陸續落地多個行業,比如,服務於醫療場景的「 商量 • 大醫 」,已經用於導診、問診、健康咨詢、輔助診療等環節;真實世界三維重建大模型「瓊宇」, 賦能於影視制作、建築設計、商品營銷、數字孿生管理運營等行業;「明眸」作爲商湯自研大模型的數據標准平台,相比人工標注,效果好效率高成本低。
換句話說,當很多公司還在產出大模型單品時,商湯直接來了“一技通殺”,前店——生成式AI應用專賣店,後廠——“AI大模型”生產线。
業務落地,也體現在業績增長上。
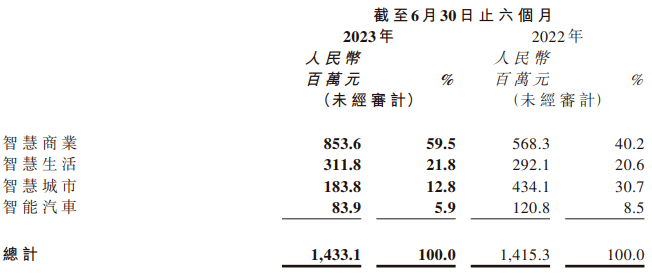
2023年上半年,商湯智慧商業板塊營收爲8.5億元,同比增長50.2%,單客戶收入提高了59.9%,AI大模型功不可沒——商湯深入數10個垂直行業,爲其深度定制行業大模型、包括能源、金融、地產、人力資源、傳媒、工業制造、咨詢等等。
比如爲Top3保險公司提供的基於AI遙感大模型的農作物承保服務,助攻其效率提升了60倍。
來源:商湯財報
同期,智慧生活板塊收入同比增長 6.7%至 3.1億元,收入貢獻比例提升至21.8%。
目前,商湯已經與電商、媒體、社區平台等20多個領域的上百個客戶合作,通過B2B2C模式,爲其定制行業大模型,其中,數字人視頻生成平台「如影」已服務於央視、廣電、工商銀行等標杆客戶。
而在智能汽車領域, 2023年上半年,商湯絕影的量產業務實現了573%的同比增長,量產交付數量達到39萬台車,規模量產也帶動了單車毛利提高29%。基於大語言模型產品「商量」,商湯首發了多款車艙中文交互產品,包括健康問診、旅遊規劃、兒童伴讀等。
不過,上述收入,其實遠遠未能徹底釋放商湯的技術紅利。在財報後的電話會上,商湯高管們預判,2026年前後,生成式AI將會成爲最大的收入來源。
這種預判並非過度樂觀。
其一,商湯的生成式AI營收規模雖然不大,但已經在多個行業、多個領域得到驗證,後續可復制性可推廣性極強。2023年H1,商湯生成式AI相關收入的增速,要遠遠高於營收大盤。
其二,行業頭部客戶的認可帶來了強大的品牌背書,後續可以持續推進行業內中腰部客戶轉化,商湯的开源AI模型,也能爲後者提供性價比更高的服務。
其三,生成式AI一旦渡過技術的奇點,則將迎來商業變現的大爆發。
被誤讀、被低估,創新者的共同窘境
盡管大模型成果可圈可點,但商湯卻不可避免地陷入了創新者的共同窘境——技術絕對領先,變現相對滯後,市值遭遇低估。
歷史不會重復,卻常常押韻——類似的遭遇,其實蘋果、亞馬遜,甚至風頭正勁的OpenAI,都曾親歷過。
這種低估,一方面,源於客觀規律——任何顛覆創新者,都需要長周期高強度的投入研發。
不過,一旦熬過“漫長的季節”,紅利的爆發也足夠豐厚,比如亞馬遜的AWS(亞馬遜雲科技),在熬過漫長的虧損期後,如今已經成爲了利潤奶牛,僅2022年,就貢獻了228億美元的營業利潤。
因此,對這類顛覆性創新者的估值邏輯,如果套用適合线性增長的成熟公司的的市盈率、市淨率、市銷率等估值法,其實是對其未來爆發性紅利的忽視。
另一方面,源於大衆和投資者對顛覆式創新者的主觀認知錯位。
面對一個顛覆式的創新玩家,投資者通常會基於過去行之有效的固有經驗,和一以貫之的线性邏輯,對其進行評估,導致估值體系的錯亂。
回看商湯,目前其低估值,其實源於業內把其劃歸於傳統的AI軟件供應商。其實,AI軟件售賣,只是商湯的過渡性業務之一,遠遠不能圈定其未來業務的邊界。
這種對商湯的誤讀,IPhone也曾遭遇過,剛剛上市時,曾被諾基亞高管嗤之以鼻,“這個手機一摔就壞”。
用耐用度這一指標去評估手機,顯然是功能機時代的思路,也是對其商業模式的曲解和偏見。眼下,蘋果除了靠硬件賺錢,也靠服務生態氪金,在今年Q2,蘋果一枝獨秀,狂攬全球智能手機利潤的85%。
如蘋果多元化變現一樣,未來商湯有望在AI大模型的基礎設施層、終端應用層,以及To B、To C、To G 多個領域,構建立體化的營收體系。
從蘋果、亞馬遜到商湯,如何把顛覆式創新者從誤讀和低估的泥潭中拖拉出來,對其進行合理的價值重估?其實有着清晰的方法論。
其一,先判斷其所在賽道的前景和潛力。
今年7月,麥肯錫在分析跟蹤了63種生成式AI應用之後,得出了結論——如果將上述AI應用落地於各行各業,將爲全球經濟每年帶來高達4.4萬億美元的增長。
無獨有偶,另據高盛預測,生成式AI可以推動全球GDP增長7%,達到近7萬億美元。
不難看出,生成式AI高達數萬億美元的賽道價值,已成共識。

其二,再研判公司在賽道的排位如何,到底是徒有虛名的鍍金者,還是真材實料的煉金者。
以商湯爲例,根據弗若斯特沙利文發布的《AI大模型市場研究報告(2 0 2 3 ) 》,商湯在產品技術、战略愿景、生態开放度等綜合能力上排名第一。商湯的大算力基礎設施布局和全棧大模型研發能力優勢,也奠定了其作爲大模型廠商的領先地位。
其三,也要判斷公司的安全度,在漫長的盈利期到來前,能不能熬下去,這是區分先鋒與先烈的關鍵。
截止2023年6月30日,商湯持有的銀行存款、在手現金、結構性存款及債券和其他固定收益產品共計148.2億元。根據商湯2023年中報,其營收增速由負轉正,期內虧損連續兩年收窄。
據此來看,手握過百億資金的商湯,仍處於安全水位。
從上述三個指標,去稱重具體標的的價值,誤解和偏見的幾率就有望減少,如今,OpenAI的價值已經得到重估。有着AI布道師之稱的陸奇更是斷言,OpenAI未來的價值肯定會超越谷歌,“可能是谷歌的5倍,也可能是10倍”。
歸根結底,公司的市值和估值,短期是投票器,取決於市場當下的認知,長期來看必然是稱重機,市值和價值趨向一致。
現在,和商湯一樣處於估值尷尬期的創新者們,或許無需辯白自證,只需靜等時間的糾偏和饋贈。
原文標題 : 重估“大模型公司”商湯科技
標題:重估“大模型公司”商湯科技
地址:https://www.utechfun.com/post/255519.html