金融大模型的難點在於,能否在產業中扎得更深;其顛覆性也更建立在,縱深到產業中去,賦能金融行業的長尾場景發展,以及重拾“金融信任”。?
作者|思杭?
編輯|皮爺?
出品|產業家?
“從經濟角度講,整個金融業的數字化進程並非勻速;從技術角度講,催化劑的出現會加速行業駛向數字化深水區。而大模型正是過去十年最強的‘催化劑’。”恆生電子首席科學家白碩告訴我們。
大模型正在成爲推進金融業數字化的第二波浪潮。
2013年,互聯網金融騰空出世。此後十年,金融產業共經歷過兩次由AI帶來的革命。
第一場革命的主角是辨別式AI,比如幫助金融機構更好地進行智能分析與決策。在當時,互聯網金融正處於浪潮之巔,金融無紙化、在线化、移動化、遠程化,都促進了金融產業鏈的變革與創新。
在第一波AI浪潮中,最爲顯著的改變是,以銀行爲代表的金融產業經歷了新舊範式的轉變。
然而,這一波金融產業革命進行得並不徹底。雖然“金融信任”的號角早已吹響,但在金融業,數字化接受程度不高。人工智能的利好,也並未充分得利用在金融業。
這其中,有技術問題,也有合規因素,更有行業壁壘等種種原因,都阻礙着金融產業革命的到來。直到2023年,大模型讓局面發生了些許變化。
客觀來看,生成式AI的到來,讓行業正在重拾“金融信任”。
一、大模型在金融業是剛需嗎?
當下,金融機構對數字化的接受程度普遍較低,全面實現數字化的難度也較大。但全流程的數字化,正是金融機構引入大模型的前提。如果仍僅停留在工具層應用,大模型無法更好地賦能產業發展,其顛覆性不大。
恆生電子告訴我們,“如果將金融機構的數字化轉型成熟度分爲0到5級,其中0級代表剛起步階段,而5級表示完全以數據驅動的商業模式。目前大多數金融機構處於2級和3級的水平,少量機構已經達到4級,甚至有一些局部達到5級。”
在所有金融機構中,“數字化轉型表現最優異的是銀行,尤其是頭部銀行,其次是券商。”
之所以銀行的數字化接受程度最高,是因爲銀行涉及到很多客戶服務和風險監控的場景。券商則不同,其更多的應用場景在智能決策方面。這兩類不同的場景恰恰是辨別式AI與生成式AI各自擅長的領域。
具體來看,辨別式AI是直接將輸入映射到輸出上,通過學習輸入數據的特徵來預測輸出標籤,而在輸入與輸出之間,並沒有生成式AI的增強學習的過程中。因此,辨別式AI更多用於分類、回歸等任務,比如圖像識別和語音識別。
生成式AI則有所不同。其最大的優勢就在於增強學習的過程。生成式AI可以從已有數據中學習樣本的統計特徵,並在此基礎上生成新的數據。因此,在金融場景下,更適合進行智能決策,通過大模型中輸入的金融知識和新聞等知識,從而給出業務營銷、風險投資等建議。
這意味着,在AI大模型的加持下,在金融行業裏會出現一些之前沒有的變化。
正如白碩所言,大模型是多年來對金融業影響最爲直觀的“催化劑”,相比於元宇宙、區塊鏈等技術,大模型更能深入到垂直領域,顛覆產業,帶來實際價值。其中,最爲直觀的影響是給原有的崗位帶來全新的工作方式。
“比如像數據分析師崗位的變化就很突出。在投資研究領域,數據分析師需要根據財務報表、公开資訊、研報等公开數據進行數據分析形成內容。大模型在這樣的數據處理能力上表現很好,可以替代一部分的崗位工作。”白碩這樣告訴產業家。
然而,由於大模型在精度、時效性、專業性等方面還有明顯缺陷,當前在金融業還很難實現更深的價值。目前,大模型更多能起到的還是提供一個人機非常友好的交互能力,在金融專業工作中還是需要專業人力完成。
可以說,想象力豐富之余,就當下而言,大模型對金融行業帶來的更爲實際價值,更多體現在一些交互性更強的場景。
已經有銀行开始行動。今年3月,工商銀行基於昇騰AI,發布了首個金融行業通用模型。在發布會上,工行宣布該模型已應用在客戶服務、風險防控、運營管理領域。比如,工行應用該模型支撐智能客服接聽客戶來電;再比如,利用金融大模型,對工業工程融資項目建設進行進度監測。
或者也可以說,大模型對金融行業的意義,在加速數智化和重拾“金融信任”之前,更鮮明的變化是長尾場景落地。
二、金融大模型走到哪了?
半年時間,互聯網大廠已全部入局;銀行、券商等金融機構也紛紛下場。
金融大模型之所以被稱爲“塔尖技術”,其難點不僅在於技術和合規,更在於數據和領域經驗。也就是說,金融大模型的搭建並非可以一蹴而就,而需要具備一定的條件。
以互聯網大廠爲例,百度、騰訊、阿裏和360憑借其多年對抗黑灰產的經驗和在AI領域的深耕,可以算得上最有條件做金融大模型的佼佼者。
最先有所動作的是度小滿。5月26日,度小滿正式开源中文金融大模型“軒轅”。與文心一言不同的是,軒轅大模型是度小滿在金融領域長期深耕的結果,並擁有更多高質量的可訓練數據。對金融大模型而言,金融領域的數據質量直接決定了軒轅大模型的各方面表現。
另外,從參數量來看,據官方介紹,軒轅大模型是在1760億參數的Bloom大模型基礎上訓練而來,且軒轅還融合了金融名詞理解、金融市場評論、金融數據分析和金融新聞理解等數據。
其次傳出風聲的是螞蟻集團。6月21日有消息稱,螞蟻集團的技術研發團隊正在自研語言和多模態大模型,內部命名爲“貞儀”。對此,螞蟻集團的回應是“消息屬實”。
螞蟻集團的底氣一方面來源於支付寶在金融領域的多年行業經驗;另一方面來源於從2015年螞蟻集團在可信AI技術研究的投入。2016年,螞蟻集團全面啓動AI智能風控防御战略,目前已在反欺詐、反洗錢、反盜用、企業聯合風控、數據隱私保護等多場景落地。近兩年,螞蟻集團更是加緊AI領域的布局。
早在2019年清華AI研究院基礎理論研究中心成立,該中心首席科學家朱軍及其團隊同期發布了第三代人工智能平台RealAI,並與金融、工業制造等行業應用深度結合。而就在螞蟻集團傳出自研“貞儀”的前兩日,由朱軍帶領的新團隊完成了近億級天使輪融資,由螞蟻集團領投。
最後,騰訊和360也在近日聯合信通院編制國內金融大模型標准。對於騰訊而言,過去20多年黑灰產對抗經驗加上上千個真實業務場景,這些都讓騰訊具備了最真實的行業數據。而向來有着“安全衛士”稱號的360也不例外。
除了互聯網廠商,在金融領域大模型方向布局的還有數據庫廠商,比如星環科技。
對於金融大模型的搭建,數據庫廠商與互聯網廠商走的是兩條完全不同的路线。星環科技的優勢有兩方面。
第一是工藝,即在模型訓練過程中涉及到的數據“清洗”等加工處理。作爲數據庫廠商,星環科技對於數據處理有着一套嚴密的方法論,尤其是針對金融領域特有的異構數據。
對此,星環科技在自研金融大模型“無涯Infinity”的同時,還提供了一站式的企業自建大語言模型工具鏈。該工具鏈了包含了與大語言模型應用落地緊密相連的向量數據庫Hippo,以及一系列針對數據庫底層處理技術。其中,最值得注意的是向量數據庫Hippo。
在金融領域,數據時效性是大模型落地挑战之一。如何將突發事件和金融資訊等實時數據輸入到大模型中,直接關乎着金融大模型能否准確地進行分析決策。而向量數據庫正是解決該問題的關鍵。
星環科技的第二大優勢則是其長期深耕於金融領域沉澱下來的領域數據和行業know-how。
盡管互聯網廠商與數據庫廠商各佔據行業經驗和模型工藝的優勢,但最具備搭建金融大模型的應該非垂直類廠商莫屬。因爲這類廠商有着較高的訓練模型的數據,比如致力於提供金融數字化解決方案的廠商「恆生電子」。
6月28日,恆生電子對外發布金融行業大模型LightGPT。據了解,該模型使用了超4000億tokens的金融領域數據(包括資訊、公告、研報、結構化數據等)和超過400億tokens的語種強化數據(包括金融教材、金融百科、政府報告、法規條例等),並支持超過80+金融專屬任務指令微調,從而加強LightGPT在專業領域的理解能力。
白碩表示,對於金融大模型,最爲重要的是數據質量,即大模型訓練的數據量大小和數據質量,因爲這關系到大模型能夠輸出什么。在底層技術相差無幾的情況下,數據質量才是關鍵。其次是工程化能力和行業經驗。其中,工程化能力包括對數據的選擇、清洗和改造等工作,比如當大模型表現不盡如人意或出現問題時,廠商知道如何判斷缺哪些數據,需要補充哪些數據,從而提高大模型數據質量。
然而,在金融大模型落地過程中,最不容忽視的挑战是安全問題,即公有雲與本地部署之間取舍。
在金融領域,很多數據涉及合規、隱私安全,甚至監管問題,無法公开,因此很難上雲。比如工商銀行、農業銀行、郵儲銀行、中信銀行、興業銀行、江蘇銀行、蘇州銀行等多家銀行和券商都已選擇接入通用大模型,即以本地部署方式構建專屬領域的大模型。
既選擇了本地部署的方式,就必然會面臨一些難點,如算力挑战、參數量問題等。選擇本地部署的金融機構是否有足夠的算力是一方面,另一方面是參數量是否夠大,如果參數量不夠,即使輸入高質量數據,大模型也無法“湧現”。
種種原因,讓入局金融大模型的廠商面臨重重阻礙。
三、向產業縱深處探尋價值
但問題仍然很多,即使在金融業較爲發達的海外,大模型的落地仍是一大挑战。
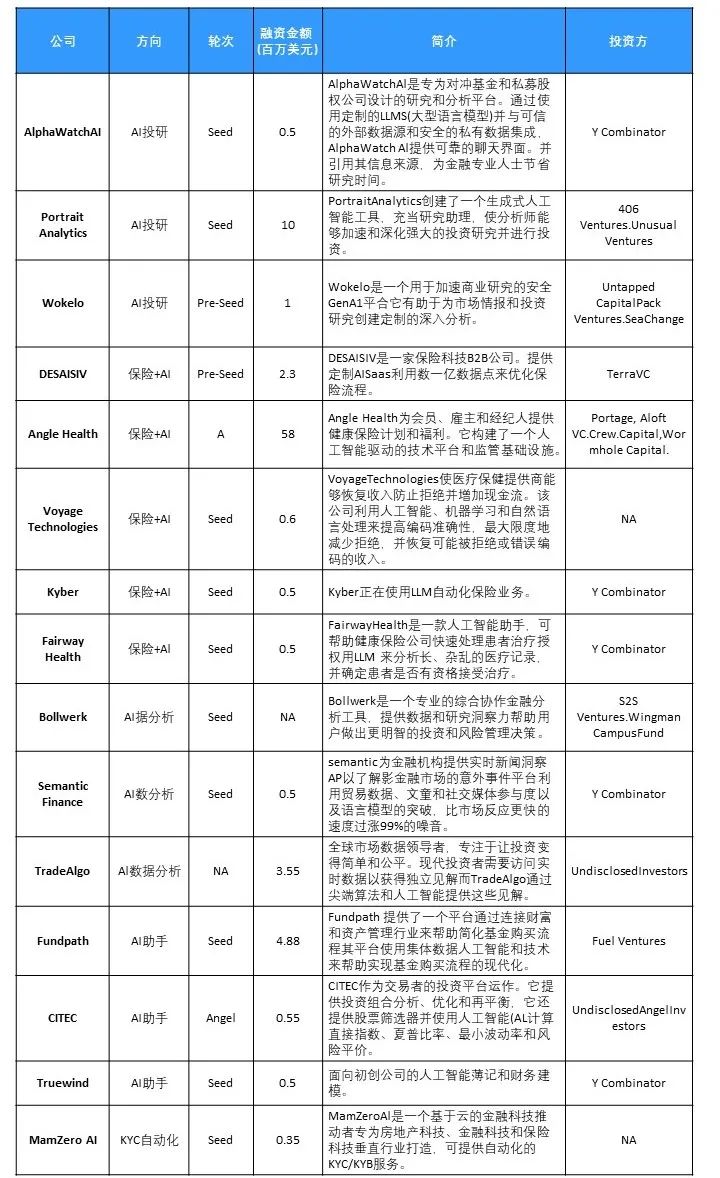
來源:Atom Capital
從上圖不難看出,創業公司融資金額普遍較小;且除了較爲知名的YC,明星資本不多。
在國內,至少目前來看,精准度、時效性和安全性是金融大模型在落地過程中面臨的三大挑战。
從精准度來講,大模型在專業領域,尤其涉及到民生經濟的問題時,還無法給出專家級的答案。白碩向產業家說道,“從技術原理上,我們不認爲AGI能長出某個領域的專業能力,專業的事情還需要交給專家。但大模型能提供的是人機對接能力,如果兩者相結合就可以發揮出更大的作用。”
另一大挑战在時效性上。數據產生的過程本身是流動的,市場上的數據講精准、講質量,也講時效。“從數據時效性方面來講,大模型的訓練周期本身就決定了不可能具有時效性,所以補充時效性很強的數據則是金融大模型的必備條件。”現在很多自研金融大模型的廠商都使用了向量數據庫的手段來實現這一難題。
最後,也是當前領域大模型所面臨的最重要的挑战,即數據安全問題。由於大模型所收集的數據來源於公开數據,行業大模型需要的是領域數據,甚至是一些不在公开渠道上的研究報告、論文等專有數據。
對此,部分企業、機構的做法是將數據選擇公开出來,但更多的則是選擇將大模型部署在本地。而這就引出了另一個問題,算力挑战、參數量問題、工程算法等方面的技術問題能否得到解決。
在白碩的觀察中,一些語言能力的差距,在2~3年內可以得到解決,不同大模型能力之間的差距也可以拉齊。剩下的問題則要看大模型能否扎在更深的產業中去提供價值。
從當前金融大模型的應用場景來看,提供的價值更多停留在工具層。具體而言,金融大模型在傳統AI模型的基礎上更進一步,利用高質量的知識數據和智能屬性,應用於交互性強的場景。
但從更大的視角來看,隨着金融大模型標准的落地,數據合規、隱私安全和訓練工藝等問題一一得到解決,金融大模型會撬動更多的崗位,也會提升人的價值。在精准度、時效性和安全性等挑战被消除後,金融大模型會與“專家”一起,解決當下無法解決的問題,帶來更大的產業價值。
金融大模型的難點在於,能否在產業中扎得更深;其顛覆性也更建立在,縱深到產業中去,賦能金融行業的數字化發展。
原文標題 : 大模型落地金融業,想象力在哪?
標題:大模型落地金融業,想象力在哪?
地址:https://www.utechfun.com/post/248627.html