大模型巨頭“圍剿”Kimi的战役,已經進行了一段時間了。想必讀者們已經從Kimi帶來的震撼中冷靜下來,开始理性審視2024的大模型“新賽季”。
毫無疑問,“卷”長文本,是基礎通用大模型在新賽季的首個賽點。3月18日,月之暗面宣布Kimi智能助手支持200萬字超長無損上下文,並开啓內測。200萬字是什么概念呢?《紅樓夢》等古典名著、企業財報等專業文獻,Kimi都能“手拿把掐”,展現出了極強的理解分析能力。

打擂台容易守擂難。Kimi這位新秀的亮相固然驚豔,但其他更早問世的TOP級基礎大模型,也都不是喫素的,很快百度文心一言、阿裏通義千問,都宣布跟進長文本能力,直接卷到1000萬字。
Kimi突如其來的熱度、巨頭的積極反撲、長文本賽事的狂飆,無不說明基礎大模型已經進入了新賽段。
Kimi不是來終結比賽的,而是來加入這個家的。而去年倉促備战、緊跟ChatGPT的第一梯隊廠商,如今也對大模型的商業化前景、落地方向等,有了更成熟的思考。
Kimi掀起的“長文本之战”,只是大模型“新賽季”paly中的一環,接下來還會有哪些看點,我們來預測一下。
Kimi,終結不了比賽
月之暗面(Moonshot AI)是大模型賽道上,第一波獲得較大規模融資的明星創業公司。而相比同時期動作不斷的AI大廠如BAT、明星企業如百川,月之暗面直到去年10月才交出了第一份成績單Kimi,頗有種“謀定而後動”的味道。

從參數上看,Kimi的長文本能力超越了當時的谷歌gemini 1.5、Claude3,處於全球領先水平。
從市場動作看,Kimi的宣傳,也不像其他基礎通用大模型廠商那樣謹慎,而是大規模投流,廣告鋪天蓋地,在B站、抖音、小紅書等平台都有信息流投放。據媒體報道,Kimi每天獲客成本都在20萬,正在“燒錢換規模”。
從實際效果看,有大量個人用戶和企業开發者在使用Kimi後表示,其在中文上的理解、分析、問答能力,確實優於當時主流的國產大模型,上下文銜接更好,總結能力更強。
幾重因素疊加,升級後的Kimi引爆了資本市場的新一波熱情,甚至出現了“Kimi概念股”。
那么,Kimi能“亂拳打死老師傅”,一舉終結基礎大模型的比賽嗎?子彈飛了這么久,結果已經很明顯了,不能。
一方面,隨着用戶規模的增多、應用場景和用例的增加,Kimi的能力局限越來越多地暴露出來,比如有用戶提到,Kimi的編程能力跟ChatGPT、GLM4、文心一言有很大的差距,ToC場景下長文本處理的需求並不高頻,新鮮感過了之後,感覺沒有其他太大用處。
同時,Kimi視爲核心差異化優勢的長文本能力,並不構成真正的護城河。從其他巨頭很快就跟進並上线了相關能力,就可以看出,長文本處理技術的壁壘並沒有很高,能做基礎通用大模型的頭部廠商,都有相關技術和人才積累。
而過去一年AI大廠在多模態大模型、智算基礎設施、ToC應用、Tob客情關系等多個維度構築起的壁壘,則是月之暗面很難快速追趕的。比如,目前月之暗面還沒有發布多模態大模型,雲服務運維跟不上,難以保證B端用戶的體驗。
目前Kimi面向大衆免費試用,但其付費API的定價,有的版本幾乎達到了GPT-3.5等領先大模型的數倍,後續付費轉化也要打一個問號。
總的來說,Kimi是月之暗面在大模型技術上的一次成功“秀肌肉”,但別說直接終結比賽,要躋身“可規模落地大模型”這一賽道的TOP席位,恐怕爲時尚早。
新賽季,“遭遇战”告一段落
有讀者可能會問,既然大廠有做長文本處理的能力,爲什么去年不卷,非要Kimi火了之後才卷?
所以說,Kimi爆火是一個很好的契機,標志着中國大模型已經從倉促備战的“遭遇战”,進入到了步步爲營的“陣地战”。
簡單來說,2023年ChatGPT橫空出世,中國的AI大廠是在猝不及防的情況下,極短的時間內統籌資源、組織人馬,快速跟上OpenAI的技術進展,一度出現了“大模型日拋”的局面。這時候最重要的是爭取主動,避免中國AI在大模型浪潮中缺席。文心一言、訊飛星火、騰訊混元、華爲盤古、百川智能、智譜AI等一大批基礎大模型廠商和初創機構,確實讓中國在“遭遇战”中拿下一城。
狂奔一年,無論海內外都對大模型有了更清晰,也更務實的認知。中國的基礎大模型廠商,已經开始“高築牆、廣積糧”,逐步進入到充分准備、保障嚴密、战略穩定的“陣地战”了。
爲什么之前不卷長文本,Kimi出現又快速集體圍剿?恰恰是新賽季“陣地战”开始的信號。
信號一,不打沒意義的仗。
國內基礎大模型的競爭基本告一段落了。
隨着Sora、Claude3等开源或閉源大模型都越來越強大,基礎通用大模型的投入門檻也更加高昂,不能長期拿出天文數字來卷的都心生退意,轉而去挖掘垂直場景和細分行業的機會,這也讓頭部廠商的認知度和市場認可度更加穩固。
基礎大模型廠商也开始精打細算,關注如何從硬件中壓榨出更多算力、降低單位推理成本、構建可持續的國產算力、挖掘商業化項目潛力等。而長文本處理要消耗大量的硬件資源,平白無故瞎卷,燒錢費力還未必討好,確實沒必要。

但Kimi的爆火,更多是讓ToB場景,尤其是金融、政務客戶,看到了大模型的應用價值,讀財報、讀合同、做客服,更長的文本確實能在這類知識密集型場景,發揮出更好的效果,減少幻覺問題。這代表了基礎模型的底層能力,所以Kimi的長文本之战,必須打。
信號二,競爭更加立體復雜
2023年末,大模型熱度已經开始降溫。應用側落地困難,所謂的殺手級AI應用似乎還是沒有出現,而投入成本持續加碼,基礎模型一升級就會覆蓋創業者的工作,導致投資市場態度也偏向謹慎。於是,很多人开始質疑這一波大模型只是自嗨,唯一賺錢的只有賣鏟子的英偉達,焦慮情緒开始彌漫。
這時候,Kimi作爲一款現象級產品,確實打破了僵局。

作爲一個有實際意義的應用層產品,Kimi讓大衆再一次感受並認可了大模型的價值。根據產業規律,應用爆發往往會在產業基礎平台條件具備之後的一兩年內出現,Kimi正處於這一時間軸的關節上,標志着AI應用爆發即將开始。
Kimi對大模型價值的再度確認,也會讓接下來的通用大模型競爭,從卷參數、卷benchmark等基礎項PK,進入到更加復雜、多元的能力角鬥。
信號三,跑馬圈地白熱化。
這一競爭階段,“遭遇战”時的靈活、機動、大幹快上,就不太管用了,而需要細致部署、步步爲營,跑馬圈地。
對Kimi的圍剿說明各家基礎大模型廠商的底層能力,會很快趨同。除非像OpenAI那樣,技術的飛輪效應極強,跟競爭對手的差距越拉越大,否則,技術天然會擴散,很難長期成爲商業祕密與護城河。
壞消息是,國內的基礎大模型,想要建立差異化優勢越來越難,沒有人能獲得壟斷地位;好消息是,政企客戶更希望構建“模型花園”,根據需要調用多個大模型,減少對單一供應商的依賴,所以市場仍在增長,仍然开放,大家都還有機會。
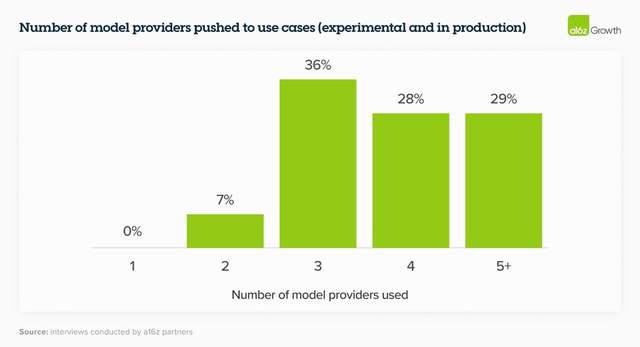
(企業希望引入的模型數量)
a16z調研了七十多位財富500強企業和頂級企業領袖,發現這些公司2024年在AI上的支出預算比2023年增加了2-5倍。國內市場的智能化速度也不會遜色,更增強了對基礎大模型的需求,所以接下來,會進入到白熱化的跑馬圈地階段。
大模型新賽季,正式拉开帷幕。
長文本,只是“陣地战”的一環
長文本,是“秀肌肉”的必爭之地,但解決政企客戶的切實需求,長文本卻未必那么實用。從Kimi的長短板,我們可以看到目前市場更需要怎樣的大模型。
首先說說短板。前面提到了,Kimi的長文本在很多場景下屬於低頻需求,再長的token只會帶來更大的計算量、更高的資源成本,對用戶來說性價比不高。對此,吳恩達也認爲,快速生成token,可能比使用更強的模型更重要。長文本處理導致的硬件資源需求、GPU短缺和雲服務能力,也是Kimi面臨的現實挑战。
而Kimi的長板在於,在文本摘要和知識管理等任務中,發揮出了極高的生產力效能,對企業的吸引力很大。應用更友好,企業不需要從頭开始訓練自己的LLM。
所以,長文本之战引發的連鎖反應,會讓一些能力,成爲battle重點:

1.與雲的深度融合。Maas服務會成爲模型購买決策的首要原因之一,繼續深化、細化。
2.對Agent开發的支撐。基礎大模型很難提供所有端到端的解決方案,長文本處理是應用層公司的舞台,通過基礎大模型+Agent式工作流,去解決客戶的專有問題。而Agent式推理拼的是token生成速度,而非文本有多長。試想一下,如果一個金融客服助手半天憋不出一段話,即使生成的效果再好,用戶也不會有耐心等待。所以,長文本能力並非應用型企業選擇基座模型的唯一標准,甚至不是最重要的標准。
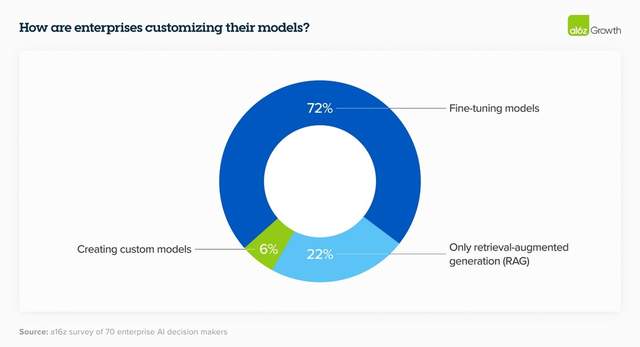
3.生態規模。Kimi的爆火說明,大廠不可能壟斷所有應用方向。利用新的技術能力(如長文本處理)來解決新的問題,創業公司和個人开發者更具備貼近客戶、深入場景的優勢,爲各類行業用戶的特定需求進行微調、定制。大模型的商業城池,必須由衆多生態夥伴一起來守,誰能在2024奠定生態的規模優勢,是接下來博弈的關鍵點。
總的來說,大模型落地,是一個復雜的系統工程。2024進入“陣地战”的大模型市場,准備更加充分,作战更有條理,商業化战略也日益清晰。基礎模型廠商,將在一次又一次的迎敵與防御中,構築起系統性的攻防能力。
一個平台級的大模型公司,一定會是萬億級別,也一定會誕生在中國。讓我們拭目以待。
原文標題 : 圍剿Kimi,只是大模型“新賽季”play的一環
標題:圍剿Kimi,只是大模型“新賽季”play的一環
地址:https://www.utechfun.com/post/354107.html