
通過行業應用先行來帶動整體的突破。
文 | 華商韜略 王夢欣
年初以來,OpenAI以ChatGPT在全球掀起AI大模型熱潮。但美國的AI大模型,遠不止於OpenAI的ChatGPT。
【井噴式發展】
綜合各種數據,雖然中國發展勢頭迅猛,但美國依然是全球發布大模型最多的國家,到2023年5月,其10億級參數規模以上的基礎大模型就已突破100 個。
《經濟學人》報道,美國2022年大模型投資總額達474億美元,是第二名中國(134億美元)的約3.5倍,且仍保持激增態勢。高盛則進一步預測,美國2025年大模型相關投資可達千億美元,約全球的1/2。
高盛的調查顯示,羅素3000指數公司中有16%的公司在2023年的財報會議中提到了大模型,其經濟學家估計,大模型將在十年內提高1%的整體勞動生產率,並爲標普500指數帶來約14%的增長。
除了ChatGPT,美國如今具有代表性的通用大模型公司還包括:Anthropic、Cohere以及Google等。
其中,由OpenAI前高管Dario和Daniela Amodei等人於2021年自立門戶創辦的Anthropic,目前估值已達300億美元,是僅次於OpenAI(約860億美元估值)的通用大模型企業。
Anthropic擁有多位參與過GPT-2與GPT-3研發的前OpenAI核心員工,其大模型產品Claude2也被認爲是僅次於ChatGPT-4的經典力作,甚至有分析師認爲,Claude2的性能優於ChatGPT-4。
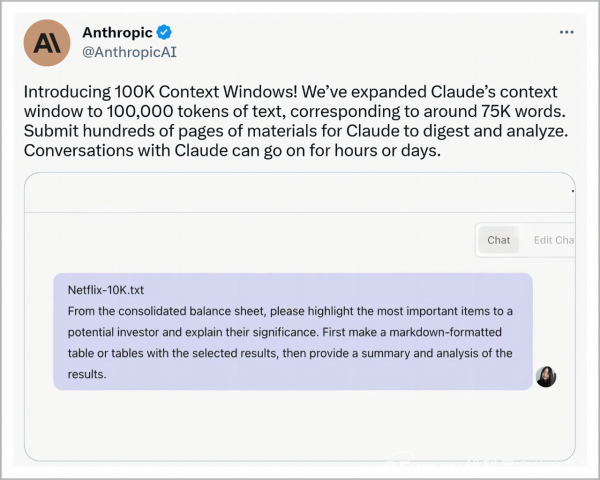
比如,Claude2可以處理多達約75000個單詞的數據集,而ChatGPT大約是3000個,這意味着它可以處理和輸出更復雜的內容,也被應用到更有挑战性的領域,比如生成數千字的長文內容。
更讓Claude2積攢人氣的是,它直接免費向公衆开放,而不是像GPT-4一樣需要付費使用。
優秀的創始團隊和強大的產品性能,讓Anthropic備受資本追捧,谷歌、韓國最大移動運營商之一SK Telecom(SKT)、亞馬遜都已成爲其投資者,其中僅亞馬遜的投資就高達40億美元。
在Anthropic之外,還有一家令人稱道的公司便是Cohere。
今年6月,2019年創立的Cohere獲得NVIDIA、Oracle、Salesforce Ventures等投資的2.7億美元,成爲估值20億美元的獨角獸,也是估值僅次於OpenAI和Anthropic的基礎大模型公司。
Cohere同樣以強大創始團隊備受業內矚目,其創始人之一Aidan Gomez是大語言模型領域开創性論文《Attention is All You Need》的最年輕作者,正是這篇文章首次提出了著名的Transformer架構,成爲通用大模型發展的基礎模型,ChatGPT就是在這一架構的基礎上誕生。
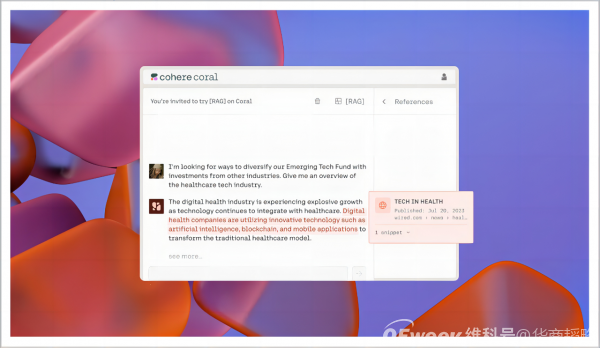
▲Cohere推出的第一個生成式AI應用Coral
Cohere與OpenAI提供的產品類似,但它看到了“數據隱私”這個市場機會,將自己與OpenAI的定位區分开來,選擇了ToB賽道,堅定地走商用大模型的路线。其產品基礎能力包括三大類:文本檢索,文本生成和文本分類,並且可針對客戶需求,強調安全性,隱私以及定制化服務。
Cohere的另一大賣點是,不受任何雲端平台限制,進而保障資料的私密安全性。它提供靈活性存儲和資料隱私保護路徑,可使用戶實現本地部署,以滿足客戶資料存儲不同位置的需求。
Cohere能迅速轉向,找到自己的差異化定位,離不开Aidan及其聯合創始人獨特的人才觀和創業哲學。
Aidan曾表示,Cohere尋找不同背景但對AI非常感興趣並富有雄心的人:他不一定有大公司的漂亮履歷,但是一定要對自己專注的領域有非常高的興趣和熱情,而且不光會寫論文,還要有實際動手的能力。
差異化的產品战略,與衆不同的團隊背景,讓Cohere成爲通用大模型領域的一股清流。
日前,Cohere發布了全球首個公开可用的多語言理解模型,該模型基於來自母語人士的真實數據進行訓練,能夠閱讀和理解全球超過100種最常用的語言。
再來看巨頭Google 。
12月6日,Google DeepMind重磅推出了多模態AI模型Gemini,可以同時橫跨文字、圖片、影音、程式碼等多模態進行學習與理解。
以客服機器人的應用爲例,使用Gemini作爲模型不僅能夠從對話的字面意思上理解客戶,更能同時從表情、聲調接收到客戶話語中的意圖,能處理包括音訊、程式碼、圖像、視訊等內容。
據實測結果,Gemini是第一個在大模型多任務語言理解上超越人類專家的模型,且在32項AI測試中,有30項測驗結果超過GPT-4。
憑借強大的性能,Gemini迅速出圈,並且爲其母公司Alphabet創造巨大聲量。12月7日,Google 母公司Alphabet股價漲幅5.31%,收於136.93美元,總市值達到1.72萬億美元。Google 則計劃逐步將這一模型融合進其搜索、廣告等其他服務中。
但談到美國大模型,更值得重視的還是其在產業中的應用進展以及未來想象。
【加速產業落地】
斯坦福大學發布的《2023年人工智能索引報告》中顯示,2022年,美國的35個大模型中,只有3個大模型來自於實驗室,32個都誕生於產業中。今年,也仍然保持着這一趨勢。
2023年3月30日,當外界還沉浸在通用大模型湧現的狂歡中,彭博社憑一己之力將衆人的注意力集中到行業新賽道。當天,它對外宣稱,自己已構建出迄今爲止最大的金融領域數據集,訓練了專門用於金融領域大語言模型的LLM,並开發了擁有500億參數的語言模型——BloombergGPT。

頂着全球首個金融大模型的光環,BloombergGPT依托彭博社大量的金融數據源,構建了一個3630億個標籤的數據集。高金智庫分析,它可極大提高金融機構的工作效率及穩定性,協助降本增效。
在降本層面,BloombergGPT可以在投研、研發編程、風險控制及流程管理等方面減少人員投入;增效層面,它既可以通過給定的主題和語境,自動生成高質量的金融報告、財務分析報告及招股書,同時輔助會計和審計方面的工作,還可提煉梳理財經新聞或者財務信息,釋放專業人力到更需要人工專業的領域。
天風證券則在報告中指出,由於BloombergGPT比ChatGPT擁有更專業的訓練語料,它將在金融場景中表現出強於通用大模型的能力,進而也標志着金融領域的GPT革命已經开始。
BloombergGPT只是一個典型案例,目前,美國金融大模型已呈現出明顯的三個“流派”:一是獨立全棧自研,強調自主可控;二是在他人的基礎上結合自身數據與場景微調,形成契合自身的金融大模型;三是從雲端調用,按需接入各類大模型API做私有化部署,科技基礎薄弱的中小型金融公司多採用這類方式。
據有關統計數據,美國金融AI約佔整體AI領域融資的6.7%。
醫療行業,是美國大模型落地應用的另一片熱土,谷歌、微軟等科技巨頭, Sensely、Enlitic等醫療科技公司,AbSci、Exscientia等生物醫藥初創企業,以及賽紐仕等CXO(醫藥外包)企業,都已參與其中。
化合物合成、靶點發現等新藥研發業務,電子病歷、輔助問診等醫院診療業務,則是美國醫療大模型應用的常用場景,CT(電腦斷層掃描)、MRI(磁共振成像)等醫療器械在大模型賦能下進一步增強。
衆多醫療大模型中,谷歌的Med-PaLM2是被關注的重點。它是第一個在美國醫師執照考試(USMLE)的MEDQA數據集上達到“專家”考生水平的大模型,其准確率達85分以上;也是第一個在包括印度AIIMS和NEET醫學考試問題的MEDMCQA數據集上達到及格分數的人工智能系統,得分爲72.3分。
Med-PaLM2也正對行業帶來變革性影響。
通過Med-PaLM2,可以分析大規模的生物醫藥數據,發現與疾病相關的基因、蛋白質和代謝途徑,識別潛在的靶點,幫助篩選具有潛在活性的藥物分子,從而縮小候選藥物的範圍,並優先選擇具有較高活性的化合物進行後續實驗驗證。備受時間煎熬的新藥研發,則將因此縮短研發周期,降低研發成本。
Med-PaLM2的成功,還刺激谷歌在醫療大模型領域投入更多。
如:與醫療軟件公司Epic合作,开發了一種基於ChatGPT的,可向患者自動發送專業醫療信息的工具;谷歌的合作方、護理供應商Carbon Health也基於GPT-4推出了一種AI工具Carby,它可以根據醫生病人之間的對話,自動生成診斷記錄,大大提高醫生的效率和診斷體驗。目前Carby已經被130+家診所、超過600名醫療人員使用,舊金山的一家診所表示,使用了Carby後,其就診病人數量增加了30%。
在谷歌之外,AI芯片巨頭英偉達也在醫療大模型領域布局多年。
2021年,英偉達宣布與Schrodinger(美醫療資訊技術公司)建立战略合作關系,通過提升其計算平台的速度和精確度,實現快速、准確的評估,加速开發新的治療方法。
2022年9月,英偉達發布了用於訓練和部署超算規模的大型生物分子語言模型——BioNeMo,幫助科學家更好地了解疾病並尋找治療優解,BioNeMo還提供雲API服務支持預訓練AI模型。今年7月,英偉達又向生物技術公司Recursion投資5000萬美元,支持开發和訓練在生物和化學領域的AI基礎模型。
教育領域也是美國大模型應用落地的重要場景之一,其核心應用主要集中於語言學習、在线課程與輔助學習三個層面。其標志性案例是美國在线教育組織Khan Academy於4月發布的基於GPT-4模型,具有輔導教學、教案生成、寫作訓練、編程練習等功能的AI助教Khanmigo。
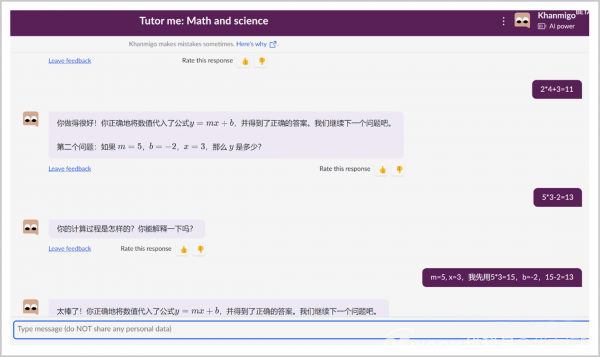
目前,Khan Academy已經實現商業化運作,付費標准爲9美元/月或者99美元/年。其中,輔導教學可以爲學生進行一對一輔導。Khanmigo會主動解釋答題思路,並引導學生進行答題的思維訓練,直至學生自己計算出正確答案;此外,Khanmigo還可以作爲寫作指導老師,根據人物特徵、故事背景等具體細節,提示和建議學生以不同的切入點進行寫作、辯論等,釋放學生的創造力。
強大的意圖理解和自然語言交流能力,以及文本和圖像生成能力,讓Khanmigo可以真正理解學生,有針對性地給學生提供個性化的學習建議,並且大幅提升教材的供給,包括寓教於樂的課件、豐富的課外資料等,這讓教育的“千人千面”有了實現的可能,也正對行業產生重要影響。
綜合來看,美國大模型還在加速與產業的融合發展,新的產業革命也正因此發生。
【中國優勢與機遇】
從全球範圍來看,中美兩國引領着大模型的發展。
根據《中國人工智能大模型地圖研究報告》,目前全球累計發布大模型202個,其中中美兩國大模型數量佔全球大模型總數量的近80%。全球大模型之爭實際上是中美兩國的競賽。
中國大模型的參與者同樣衆多,頭部科技企業(阿裏、百度、騰訊、華爲等)、新創公司(智譜AI、百川智能等)、傳統AI企業(科大訊飛、商湯科技等)以及高校研究院(清華、復旦、中科院等)均已深度布局,並正逐漸形成互聯網巨頭通用模型領跑、AI廠商、創業公司及科研院所百花齊放的格局。
雖然目前美國在大模型領域呈現出領跑態勢,而且對中國採取了諸如禁止美國企業向中國提供雲計算以及大模型訓練服務等打壓措施,中國大模型依然有着巨大發展機遇,並具備超越美國的基礎。
首先是,中國從政府到業界都在力推大模型的發展與趕超。據《金融時報》報道,中國已在全球前十的大模型研發機構中佔據四席,分別是百度、BAAI智源研究院、清華大學以及阿裏巴巴研究院。百度的“文心一言”、阿裏巴巴的“通義千問”等都是我國自研的大模型,其性能足以與美國的大模型一較高下。
Leonis Capital報告分析表示,相較於美國企業更加重視底層研發能力,中國百度、阿裏等領先巨頭之外的絕大多數企業,更偏框架、行業應用層面的研發,而這種差異將爲中國帶來巨大機會,讓中國在生成式AI應用和大模型行業解決方案應用領域超越美國,最終以應用領先倒逼或支持基礎端的趕超。
因爲,中國雖然在底層研發技術上相較於美國略顯遜色,但卻具有超大的市場規模以及豐富的應用場景,可以爲大模型的落地應用提供廣闊的空間和條件,進而通過行業應用先行來帶動整體的突破。
大模型一個很重要的特徵是,應用和技術的雙輪驅動。也就是說,消費者在使用大模型的時候,並不僅僅是貢獻利潤,還可以通過數據回環,使大模型獲得更多的反饋,從而提升神經網絡的能力。豐富的場景可以讓大模型更加突出實用性,並匹配需求取得更好的效果,也帶動更快的技術發展。
基於這一特徵,中國若能依托巨大的市場規模以及豐富的場景,把握住應用這個關鍵,尊重市場規律,持續從市場應用中獲得利潤,再反饋給資金和人才的積累,最終在底層技術上突破將是水到渠成的事。
作爲國內AI大模型領軍者的李彥宏近日也在極客公園創新大會2024上表示,“大模型時代的來臨,真正的價值在於原生應用。”
李彥宏認爲,大模型本身並不是大多數人的創新和創業機會,原生應用才是。無論對於大廠,還是中小企業,創業者,原生應用都是很大的機會。
李彥宏說,看到媒體、社會、公衆主要的興奮點還在基礎模型上,沒有轉到AI原生應用上,“我多多少少有點着急。”最近幾次公开發言,也括公司內部講話,他也都是在不停的強調。“我們一定要去卷AI的原生應用,要把這個東西做出來了,你的模型才有價值。”
事實上,中國已經在互聯網與移動互聯網領域,通過豐富的場景以及應用創新取得領先的發展,並最終帶動整個科技產業的進步,在大模型領域,這一趨勢也正在繼續。但對比中美在互聯網領域的發展,有一點倒是值得中國大模型企業現在就高度重視:更早地在海外布局,朝向全球化發展。
如今的中國企業,也更有基礎出海,在全球市場找到更加廣闊的發展空間。
——END——
歡迎關注【華商韜略】,識風雲人物,讀韜略傳奇。
版權所有,禁止私自轉載
部分圖片來源於網絡
如涉及侵權,請聯系刪除
原文標題 : ChatGPT之外,美國大模型搞到什么程度了?
標題:ChatGPT之外,美國大模型搞到什么程度了?
地址:https://www.utechfun.com/post/309835.html