
▲ 圖片由AI生成
LLM強勢挺進端側,AI大語言模型端側部署如何影響超自動化?
端側部署對大語言模型落地有什么好處?對超自動化有什么影響?
產業上下遊齊發力LLM挺進端側,大語言模型加速落地利好超自動化
芯片、雲服務、終端廠商齊發力,LLM決勝端側,超自動化受益其中
從谷歌推出Gecko到高通引入Llama 2,端側部署成爲LLM落地重要方向
大語言模型端側部署+LLM超自動化,“賈維斯”智能管家照進現實
文/王吉偉
算力資源喫緊,成本居高不下,數據隱私泄露,用戶體驗不佳……
以OpenAI爲代表的大語言模型爆發後,多重因素影響之下本地化部署成爲LLM落地的主流模式。LLM迫切需要部署在本地設備上,圍繞LLM端側部署的研究與探索空前高漲。
5月份,Google推出了可以在旗艦手機上離线運行的PaLM2 輕量版Gecko。
從這一刻起,能夠在端側運行的大語言模型成了廠商們的重要任務。畢竟LLM要落地,移動終端是最好的載體之一,同時端側也有着巨大的市場空間。
於是,廠商們紛紛开啓狂飆模式,踏上LLM的壓縮、蒸餾及優化之路,要把自家的雲端大模型先行裝進手機。
也就是在此期間,高通提出了混合AI概念:AI處理必須分布在雲端和終端進行,才能實現AI的規模化擴展並發揮其最大潛能。

端側的市場規模,加上混合AI趨勢,就連微軟也與Meta結盟共同推出了可以部署在端側的开源大語言模型Llama 2。
被稱爲“GPT-4最強平替”的Llama 2,可以讓开發者以很低的成本爲客戶提供自主大模型,將爲开發者們帶來更多可能性和創新機遇。
由此开始,各家芯片廠商全力研發能夠適配各種大模型的芯片、技術以及解決方案。
雖然能夠支持LLM本地運行的芯片還沒有量產,但高通在世界人工智能大會期間於手機端使用SD十幾秒生成一張圖片的演示,迅速吸引多方眼球。
高通計劃2024年开始在搭載驍龍平台的終端上支持基於Llama 2的AI部署,聯發將在下半年發布的下一代旗艦SoC也將支持AI部署。

端側部署芯片蓄勢待發,智能終端廠商披星戴月。
尤其是手機廠商,都在全力進行面向LLM的研發與測試,目前基本都已發布基於雲端的自有大語言模型,更想全力爭奪LLM端側部署的先發時刻。
產業鏈上下遊雨點般的密集動作,彰顯LLM正在快速挺進端側。
關注王吉偉頻道的朋友知道,LLM也正在與超自動化高速融合,並爲超自動帶來了從技術架構到產品生態再到經營模式的轉變。
過去的LLM都在雲端部署,就已爲超自動化帶來了這么大變化。現在LLM即將實現端側部署,又將爲超自動化帶來哪些影響?
本文,王吉偉頻道就跟大家聊聊這些。
手機廠商推出大模型
7月下旬,外媒爆料蘋果公司正在悄悄开發人工智能工具,且已建立了自己的框架“Ajax”來創建大型語言模型。以“Ajax”爲基礎,蘋果還創建了一項聊天機器人服務,內部一些工程師將其稱爲“Apple GPT”。
一個月後,蘋果开始全面招聘工程師和研究人員以壓縮LLM,使其能在iPhone和iPad上高效運行。這一舉措標志着蘋果公司正積極推動人工智能的發展,並希望成爲首批开發出能在手機和設備上而非雲端有效運行的人工智能軟件的公司之一。
8月初,華爲在HDC 2023 开發者大會上表示手機小藝語音助手已升級支持大語言模型,可以像目前火熱的 AI 聊天機器人那樣輔助辦公和學習。
同時華爲在發布HarmonyOS 4時,也宣布已將AI大模型能力內置在了系統底層。HarmonyOS 4由華爲盤古大模型提供底層支持,希望給用戶帶來智慧終端交互、高階生產力效率、個性化服務的全新AI體驗變革。

小米公司此前並未“官宣”進入LLM賽道,但其大語言大模型MiLM-6B已經悄然現身 C-Eval、CMMLU 大模型評測榜單。截至當前,小米大模型在C-Eval總榜單排名第10、同參數量級排名第1。
在8月14日晚舉辦的小米年度演講中,雷軍表示小米AI大模型最新一個13億參數大模型已經成功在手機本地跑通,部分場景可以媲美60億參數模型在雲端運行結果。小米旗下人工智能助手小愛同學已开始升級AI大模型能力,在發布會當天开啓邀請測試。
OPPO已在8月13日宣布,基於AndesGPT打造的全新小布助手即將开啓大型體驗活動。升級後的小布助手將具備AI大模型能力,擁有更強的語義理解對話能力,可以根據需求的文案撰寫用戶需要的內容,歸納總結等AI能力也將大大增強。

AndesGPT是OPPO 安第斯智能雲團隊打造的基於混合雲架構的生成式大語言模型。該團隊在兩年前开始對預訓練語言模型進行探索和落地應用,自研了一億、三億和十億參數量的大模型OBERT。OBERT曾一度躍居中文語言理解測評基准CLUE1.1總榜第五名,大規模知識圖譜問答KgCLUE1.0排行榜第一名。
vivo也在今年5月研發了面向自然語言理解任務的文本預訓練模型3MP-Text,曾一舉奪得 CLUE 榜單(中文語言理解基准測評)1億參數模型效果排名第一。有消息透露,vivo將在今年10月左右推出新的OriginOS 4.0系統,新系統將內置AI大模型。
榮耀是最早布局AI的手機廠商之一,其AI能力的進階主要分爲三個階段:第一階段是從0到1提出概念,將需求場景化,比如相機可以直接識別綠植、天空,AI能夠對圖像進行對應的優化;第二階段,AI有了上下文理解與學習,基於位置、時間對消費者習慣進行整合式機器的決策;第三階段就是把AI引入端側。
榮耀也曾公开對外表示,將率先將 AI 大模型引入端側。
芯片廠商的LLM動作
高通是LLM端側部署的堅定推動者。
6月初,高通發布了《混合AI是AI的未來》白皮書。高通認爲,隨着生成式 AI正以前所未有的速度發展以及計算需求的日益增長,AI 處理必須分布在雲端和終端進行,才能實現AI 的規模化擴展並發揮其最大潛能。
雲端和邊緣終端如智能手機、汽車、個人電腦和物聯網終端協同工作,能夠實現更強大、更高效且高度優化的 AI,混合AI將支持生成式AI應用开發者和提供商利用邊緣側終端的計算能力降低成本,因此混合AI才是AI的未來。(後台發消息 混合 ,獲取該白皮書)。在今年的世界人工智能大會上,高通展示了在終端側運行生成式AI模型Stable Diffusion的技術演示,和終端側語言-視覺模型(LVM)ControlNet的運行演示,參數量達到10億-15億,能夠在十幾秒內完成一系列推理。
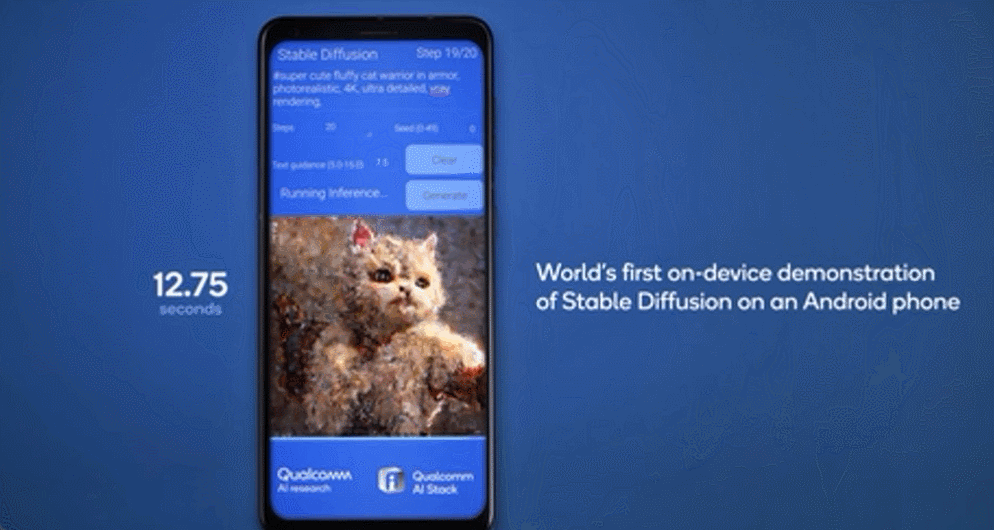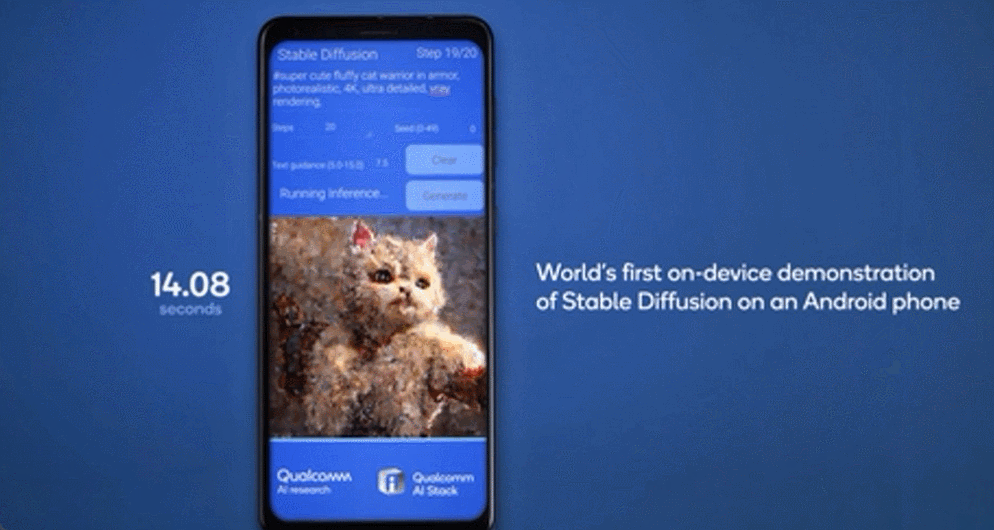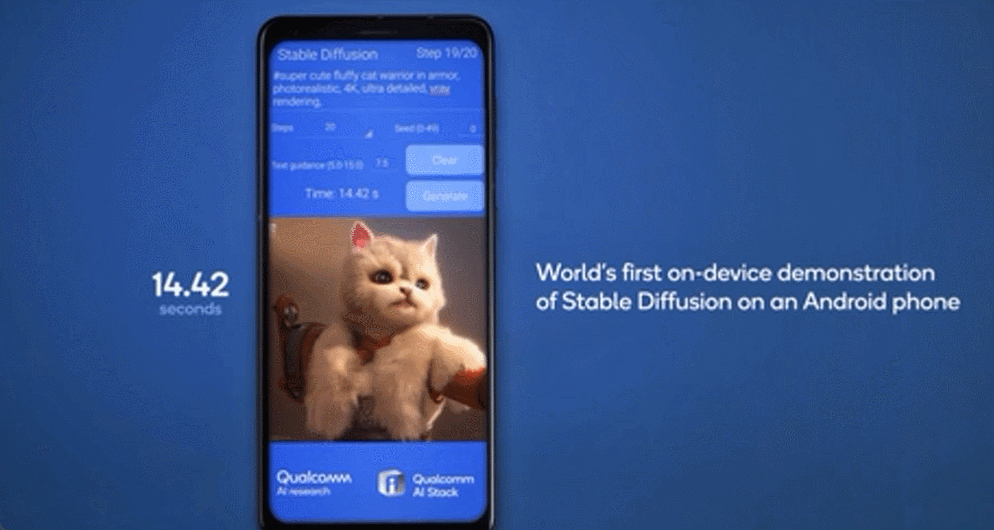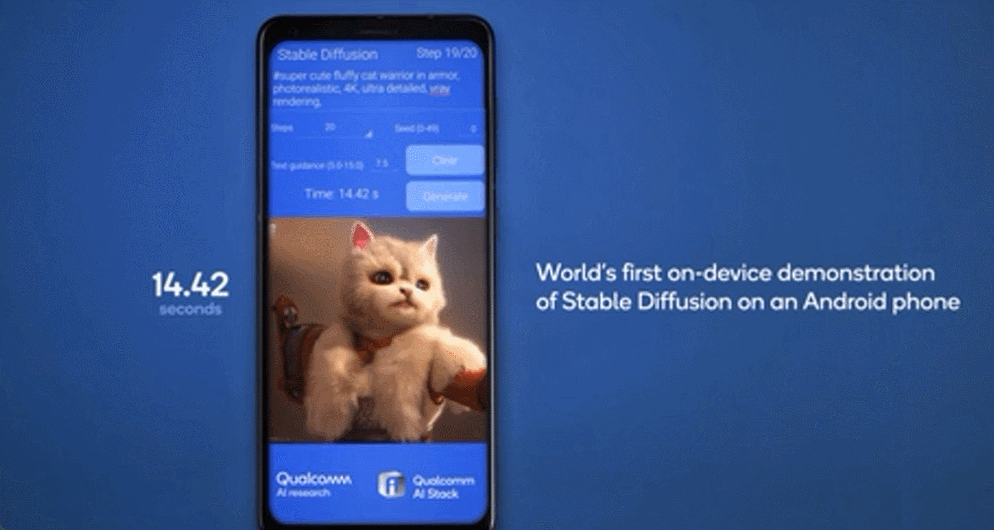
7月19日,Meta宣布與微軟合作共同推出开源大語言模型Llama 2之後,高通隨即官宣了與Meta公司的合作,將實現在高通驍龍芯片上可以不聯網的情況下,運行基於Llama 2模型的應用和服務。
雙方通過合作,可以在智能手機、PC、AR / VR 頭顯設備、汽車等設備上,運行Llama 2爲代表的生成式 AI 模型,幫助开發者減少雲端運行成本,爲用戶提供私密、更可靠和個性化的體驗。
高通計劃從2024年起,在搭載驍龍平台的終端上支持基於Llama 2的AI部署。目前,开發者已經可以开始使用高通AI軟件棧面向終端側AI進行應用優化。
聯發科在4月28日官宣發布了全球首個繁體中文AI大型語言模型BLOOM-zh,該模型於2月份开始內測,至發布時在大多數繁體中文基准測試中優於其前身,同時保持其英語能力。
與高通一樣,聯發科也在積極擁抱Llama 2。
8月24日,聯發科宣布將運用Meta最新一代大型語言模型Llama2以及聯發科最先進的人工智能處理單元(APU)和完整的AI开發平台(NeuroPilot),建立完整的終端運算生態系統,加速智能手機、汽車、智慧家庭、物聯網等終端裝置上的AI應用开發。

預計運用Llama 2模型开發的AI應用,將在年底最新旗艦產品上亮相。
聯發科透露,其下一代旗艦SoC天機9300將於下半年推出,常規的性能提升之外,還將整合最新的APU,在手機等終端設備上帶來更強的AI能力,類似ChatGPT的服務體驗。
6月上旬,也有消息透露三星電子已在开發自己的大型語言模型(LLM)以供內部使用。
除了手機等端側設備,PC仍舊是重要的個人與企業生產力工具,英特爾也在不遺余力的對大語言模型進行支持。
英特爾在6月份官宣了用Aurora超級計算機开發的生成式AI模型Aurora genAI,參數量將多達1萬億”。
英特爾提供了一系列AI解決方案,爲AI社區开發和運行Llama 2等模型提供了極具競爭力和極具吸引力的選擇。豐富的AI硬件產品組合與優化开放的軟件相結合,爲用戶應對算力挑战提供了可行的方案。

英特爾還通過軟件生態的構建和模型優化,進一步推動新興的生成式AI場景在個人電腦的落地,廣泛覆蓋輕薄本、全能本、遊戲本等。目前,英特爾正與PC產業衆多合作夥伴通力合作,致力於讓廣大用戶在日常生活和工作中,通過AI的輔助來提高效率,帶來革新性的PC體驗。
AMD在6月中旬發布了最新款數據中心GPU——MI300X,但似乎並不被市場看好,大客戶並不买單。
倒是近期陳天奇TVM團隊出品的優化算法,實現在最新Llama2 7B 和13B模型中,用一塊 AMD Radeon RX 7900 XTX 速度可以達到英偉達 RTX 4090的80%,或是3090Ti的94%。
這個優化算法,讓更多人开始關注AMD的GPU顯卡,也讓更多AMD個人玩家看到了用AMD芯片訓練LLM的希望。目前,已經有一些开源LLM模型能夠支持A卡。

衆所周知,目前英偉達GPU是全球算力的主要構建者。當前想要玩轉大語言模型,從B端到C端都離不开英偉達,相關數據預測英偉達將佔據AI芯片市場至少90%的市場份額。
Jon Peddie Research(JPR)最新GPU市場數據統計報告顯示,2023年第一季度桌面獨立顯卡的銷量約爲630萬塊,英偉達以84%的市場份額繼續佔據主導地位,大約銷售了529萬張桌面獨立顯卡;AMD以12%的市場份額排在第二,出貨量大概爲76萬張。
作爲當前最大的算力供應商,英偉達在大語言模型以及生成式AI方面以及發布了很多战略、解決方案及產品。
限於篇幅關於英偉達這裏不做贅述,大家可以自行搜索了解。
LLM端側部署有什么好處?
從芯片廠商到終端廠商,都在搶灘登陸部署大語言模型。現在,他們又將目光聚焦到了LLM的端側部署,這其中的邏輯是什么呢?
在討論這個問題之前,不妨先看看端側部署LLM有哪些好處。
近幾年LLM取得了長足的進展,卻面臨着一些挑战,比如計算資源限制、數據隱私保護以及模型的可解釋性等問題,都是制約LLM走進千行百業的重要因素。

LLM端側部署是指將大語言模型運行在用戶的智能設備上,相對於LLM運行雲端服務器上,在端側運行LLM有以下幾個好處:
首先,提高用戶體驗。可以大幅減少網絡延遲,提高響應速度,節省流量和電量。這對於一些實時性要求高的應用場景比如語音識別、機器翻譯、智能對話等,是非常重要的。
其次,保障數據安全。能夠有效避免用戶的數據被上傳到雲端,從而降低數據泄露的風險,增強用戶的信任和滿意度。對於健康咨詢,法律咨詢,個人助理等涉及敏感信息的應用場景,非常必要。
第三,增加模型靈活性。在端側部署LLM可以讓用戶根據自己的需求和喜好,定制和調整模型的參數和功能。這對於一些需要個性化和多樣化的應用場景,有益於內容創作、教育輔導、娛樂遊戲等場景的業務與工作开展。
AI 部署本地化具有必要性,優勢包括更低的延遲、更小的帶寬、提高數據安全、保護數據隱私、高可靠性等。完整的大模型僅參數權重就能佔滿一張80G的GPU,但是通過量化、知識蒸餾、剪枝等優化,大模型可以在手機本地實現推理。
高通在其AI白皮書《混合AI是AI的未來》中已經預測了LLM的未來發展方向,大語言模型挺進端側已是大勢所趨。包括手機廠商等在內的終端廠商對此需求巨大,產業鏈上遊的芯片廠商自然要不遺余力地基於大語言模型做各種探索。
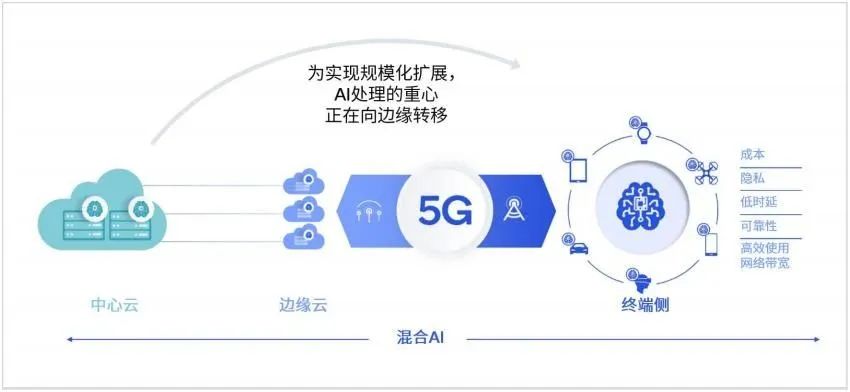
雖然高通、聯發科、Intel等芯片廠商已經與Metad Llama 2展开合作,但距離支持LLM端側運行的移動端芯片還沒有規模化量產還有一段時間。
混合AI的趨勢下,LLM的本地化與網絡化運行都是必需。因此在當前這個空檔期,廣大終端廠商正在通過雲端將大語言模型能力融合到語音助手輸入法等工具軟件上,以此讓用戶先行體驗生成式AI帶來的諸多好處。
雲端配合端側雙管齊下部署LLM,以本地終端算力支持大部分生成式AI應用,必要時聯動雲端算力解決復雜應用問題,在將手機體驗提升一大截的同時,也能將算力成本降低更多。
由此,先由雲端LLM提升用戶體驗,後面再通過端側部署LLM加強體驗,將會持續爲用戶帶來更多的驚喜。如果LLM能夠在手機端部署,自然也能在其他終端上部署。
這意味着,在手機之外,包括筆記本電腦、智能家居、VR(Visual Reality,虛擬現實)/AR(Augmented Reality,增強現實)設備、汽車和其他物聯網終端,未來都會搭載能夠支持LLM的芯片,AIOT將會迎來AIOT大換血,可以想象這是一個多大量級的市場。
而這些產品,幾乎所有手機廠商都在做。
此外,手機端運行LLM對硬件有一定的需求,CPU主頻越高算力也就越大。
IDC數據顯示,2023年一季度全球手機銷量中主處理器頻率超過2.8GHz 的佔比36%,價格在1000 美金以上的佔比13%,即旗艦機型佔比較低。隨着LLM在手機端落地,加上廠商們的大語言模型、生成式AI等的噱頭營銷,有望推動新一輪換機潮。
面向未來數十億美元的市場規模,所有智能終端廠商都將受益其中。
這對於從2019年就开始持續下行並且用戶換機周期延長的手機市場來說,着實是一場及時雨。而貼上AIGC標籤的終端產品,也有望帶領消費電子產業走出長期的低迷而進入一個新的經濟周期。
端側部署對超自動化有什么影響
超自動化是一個以交付工作爲目的的集合體,是RPA、流程挖掘、智能業務流程管理等多種技術能力與軟件工具的組合,也是智能流程自動化、集成自動化等概念的進一步延伸。
超自動化本身涉及到的關鍵步驟即發現、分析、設計、自動化、測量、監視和重新評估等均囊括在內,突出以人爲中心,實現人、應用、服務之間的關聯、組合以及協調的重要性。
自生成式AI爆發以後,超自動化領域所轄的RPA、低/無代碼、流程挖掘、BPM、iPaaS等技術所涉及的廠商都在積極探索LLM自身的融合應用,目前基本都已通過引入LLM以及基於开源技術研發了自有領域模型。這些大模型正在與各種產品進行深度交融,進而變革產品形態與創新商業模式。

超自動化是LLM落地的一個重要方向,畢竟自動化是企業優先考慮的增效降本工具及技術。尤其是端到端流程自動化,已是廣大組織進行數字化轉型的主要途徑。
引入生成式AI以後,超自動化將從內容生成自動化和業務流程自動化兩個方面同時賦能組織的長效運營。生成式AI將會進一步提升組織的業務流程自動化效率,進而實現更徹底的降本、提質與增效。
LLM對超自動化的影響,可以簡單概括爲提高效率和質量、增強智能和靈活性、支持決策自動化、拓展領域和範圍、增加創新和價值等幾個方面。
之前王吉偉頻道與大家討論的LLM與超自動化融合,更多的集中於兩者在技術架構融合後所造就的新產品、模式如何提升生產力及創造更多商業價值,沒有在LLM部署方面做更多探討,這裏我們可以簡單聊一聊這個話題。
大語言模型實現端側部署,相較於部署在雲端的LLM,必然會讓超自動化的實施與運行達到更好的效果。

RPA作爲企業管理軟件,因爲一些客戶的私有化需求,很多時候都要將RPA部署在本地機房或者私有雲環境。在大語言模型的引入上,一些對數據隱私要求比較高的客戶只能選擇本地化部署LLM,但部署在本地算力成本就成了首要問題。
將來LLM能夠部署在端側,這些客戶在算力資源上就獲得很大的釋放,PC端以及移動端都能夠承擔一部分算力,可以極大降低算力成本。
因此LLM運行在用戶的設備上,可以有效降低超自動化運行的網絡延遲,減少雲端計算資源的消耗。
在成效方面,LLM的端側部署可以使超自動化更加靈活和可定制,用戶能夠根據需求和場景選擇合適的AI模型,並且可以隨時更新和調整模型。端側部署也可以使超自動化更加安全和可靠,畢竟用戶的數據不需要上傳到雲端,從而避免了數據泄露或被篡改的風險。

當然,LLM端側部署也面臨一些挑战,比如計算需求量大、對實時性要求高,受限於運行環境、內存、存儲空間等,這些正是LLM網絡側部署要解決的問題。
由此,高通所倡導的多種部署方式相結合的混合AI就派上了大用場,這也是LLM的端側部署爲何會成爲當前大熱門的主要原因。
後記:LLM端側部署+超自動化將“賈維斯”照進現實
LLM在端側運行,可以讓手機等終端設備在不聯網的情況下與用戶進行更好的交互,並聯動其他移動端比如各種智能家居,以更好的服務用戶。
超自動化產品架構中早已引入了對話機器人(Chatbot),目的是通過語音口令自動創建業務流程。但之前的機器人反應不夠靈敏,無法與人更好的交互,也無法全面調動RPA進行流程創建,且只能構建或者執行簡單的預制業務流程。
將LLM構建於手機等移動終端,基於大語言模型生成能力、語義理解能力和邏輯推理能力,用戶就可以通過多輪對話進行業務流程的實時創建,進而構建更多復雜的業務流程,以更智能地處理多項業務。

這意味着,通過手機等終端以語音對話的方式構建並執行工作、生活及學習中的各項業務流程已經成爲可能,通過終端調用所在場景中的所有智能終端爲個體服務也將成爲現實。
目前市面已經出現了類似的產品,比如實在智能的TARS-RPA-Agent模式CahtRPA,就已經做到通過對話實現如生成文本一樣流暢地生成並執行業務流程。接下來,將會有更多類似產品出現,這將極大地豐富各領域多場景的超自動化應用。
說到這裏,大家腦海中是不是已經有一個機器人管家的形象了?
沒錯,以大語言模型爲核心,以語言爲接口,控制多AI模型系統,構建《鋼鐵俠》中“賈維斯”式的綜合智能管家,可以說是每個人的夢想。
而現在來看,將大語言模型進一步構建於端側,雲端與端側雙管齊下,再加上能夠生成各種復雜流程的超自動化,使得這個夢想已然照進現實。
全文完
原文標題 : 從谷歌推出Gecko到高通引入Llama 2,端側部署成爲LLM落地重要方向
標題:從谷歌推出Gecko到高通引入Llama 2,端側部署成爲LLM落地重要方向
地址:https://www.utechfun.com/post/256065.html