

成爲“中國版的Sora”遠不是這場AI視頻大模型競賽的終點,而恰恰只是起點。
@科技新知 原創
作者丨余寐 編輯丨賽柯
六個月前,由OpenAI研發的文生視頻大模型Sora橫空出世,給了科技圈一點大大的震撼。
用AI生成視頻並不是新鮮事,只不過此前一直無法突破合成10秒自然連貫視頻的瓶頸。而Sora在發布時就已經能合成1分鐘超長視頻,視頻質量畫面也效果驚人。
盡管Sora一直沒有开放公測供用戶體驗,但其底層架構還是被扒了個遍。被稱之爲“Sora路线”的DiT,全稱爲Diffusion Transformer,本質是把訓練大模型方法機制融入到了擴散模型之中。
自此,相關平台不甘落後,紛紛摸着Sora過河,你方唱罷我登場,競爭不可謂不激烈。有媒體統計,國內有至少超20家公司推出了自研AI視頻產品/模型。入局玩家紛雜。

在剛剛過去的7月,商湯推出最新AI視頻模型 Vimi,阿裏達摩院也發布AI視頻創作平台“尋光”,愛詩科技則發布PixVerse V2,快手可靈宣布基礎模型再次升級,並全面开放內測,智譜AI也宣布AI生成視頻模型清影(Ying)正式上线智譜清言。互聯網企業之間的賽場也有了新故事。字節跳動是第一批發布AI視頻模型的選手,3月率先發布剪映Dreamina(即夢),三個月後,快手可靈AI正式开放內測。
AI視頻大模型賽道如此之“卷”,究其原因,無疑是其背後蕴藏的商業空間與想象力。不過,用戶更關心的是產品本身。這也是行業必須要直面的問題:AI視頻大模型到了哪一步?Sora帶來的“光環”,究竟值不值得期待?
目前深度學習的框架,“數據是燃料、模型是引擎、算力是加速器”。在掌握模型搭建方法後,不斷投喂數據並提升算力和准確性是各平台採取的主要策略。而進展是有限的。普遍來看,大模型在生成具有連貫性和邏輯一致性的視頻方面仍然存在困難。
本次我們選取幾個國內頭部視頻生成模型進行實測,包括可靈、即夢、PixVerse、清影(智譜清言),具體直觀地測試不同的模型表現。
爲盡可能客觀地比較測試結果,我們採用如下設定:
1.使用統一的中文提示詞,包括簡易提示詞和復合提示詞;
2.測試包含圖生視頻和文生視頻兩種方式;
3.測試場景包括大模型對人物、動物、城市建築等的生成效果;
4.模擬新手用戶使用場景,統一採用各模型平台電腦端默認設置;
5.展示呈現採用一次生成結果,不進行二次調整優化。
以下是各模型的實際生成效果:
場景1:二次創作場景
提示詞:做出加油的動作後做出鬼臉,吐舌頭並眨右眼。
場景說明:使用梗圖《握拳寶寶》,模擬用戶二次創作,測試模型對於圖片的理解和生成能力。對於模型主要的難點在於需要理解“鬼臉”的含義,並能對“吐舌頭”和“眨眼”兩個動作做出反饋和生成。現階段,模型一般只能識別一個動詞。

網絡上曾經爆火的“握拳寶寶”

↑即夢:主體的手部、嘴部產生了明顯畸變,對於提示詞動作的理解沒有非常明顯。

↑可靈:主體動作流暢自然,具有真實感,對於提示詞動作理解不夠到位。

↑PixVerse:主體動作流暢自然,能夠做出提示詞相關的動作,這是幾個生成視頻中唯一一個做出“眨眼”動作的模型。

↑清影:不敢說話了,我怕說錯了一不小心被喫掉。
場景2:人物喫東西場景
提示詞:一個亞洲年輕男性在家裏用筷子津津有味地喫一碗面條,風格真實,類似於電影《天使愛美麗》,環境舒適溫馨,鏡頭逐漸拉近對准人物。
場景說明:對於模型來說,需要圍繞“亞洲年輕男性”“筷子”“面條”生成視頻,同時要理解電影風格和環境,並按照指示進行運鏡。更重要的是,通過喫飯這個場景可以更清晰地讓模型展示手部細節,並通過喫面條這個動作來展示模型對於物理世界的理解。

↑即夢:第一幀很帥,光影也很自然。但依舊存在臉部和手部畸變的問題,以及模型明顯不能夠理解筷子的使用方式和面條的食用方式。

↑可靈:非常驚豔的視頻!環境的光线、人物的坐姿和使用筷子的手部姿勢都非常真實,甚至嘴部的油光反射都清晰可見,不愧是據說可靈最擅長的喫播領域。唯一是面條的運動軌跡有一些小暇疵。

↑PixVerse:慘不忍睹,甚至還被動卡出了一個不連貫的分鏡,也沒有理解運鏡。

↑清影:如果不看主體人物動作,其實還算過得去。光线、環境和氛圍都到位了。
場景3:動物擬人場景
提示詞(簡單版):一頭大熊貓戴着金邊眼鏡在教室黑板前講課。
提示詞(復雜版):電影膠片感風格的場景中,一頭大熊貓戴着金邊眼鏡,在教室黑板前講課。它的動作自然流暢,周圍是充滿質感的教室環境,學生們認真聽講。整個場景如同電影畫面,光影處理細膩,色彩飽滿。電影膠片感風格,氣氛溫馨,8K電影級。
場景說明:該場景通過設置兩版提示詞,來測試大模型對於想象力的理解。簡單版提示詞僅有大熊貓、金邊眼鏡、黑板,模型可以通過這三個關鍵詞生成具有可自主添加其他內容的視頻,來展現模型的想象力和細節搭建;復雜版提示詞按照清影內設的提示詞調試小程序生成,涉及場景、風格、人物、環境、色彩、氛圍和清晰度等,測試模型的細節刻畫。
先看簡單版提示詞生成的效果:

↑即夢:很不錯的視頻生成,除了“金邊眼鏡”外,要素齊全,神態動作也非常自然,光影非常優秀。黑板上的字甚至有些以假亂真。

↑可靈:各種素材都齊了,但是沒能特別理解講課和喫竹子的區別。爲了減少失誤,畫面整體相對單調,沒有添加更多細節。

↑PixVerse:要素都齊全,風格也不錯,就是眼鏡稍微有點出戲(也比沒有強)

↑清影:完全沒有領悟提示詞的意思表達
升級提示詞後的效果:

↑即夢:效果依然不錯,光影理解也在线,唯一小瑕疵還是眼鏡部分,有畸變,以及好像不太能理解“講課”這一場景的座位排列。

↑可靈:真·熊貓大師講課圖,沒得說,優秀!

↑PixVerse:模型自己添加了運鏡和細節成分,最後有一些扭曲,整體效果跟前一版差不多。

↑清影:有景深和運鏡,畫面質感還需要提升,相比前一版有了很大進步。
場景4:科技想象場景
提示詞(簡單版):充滿科技感的未來城市一角,仰視視角。
提示詞(復雜版):在充滿科技感的科幻風格未來城市中,使用推近鏡頭,展現建築和交通工具的細節,無人機在空中穿梭,天氣晴朗,陽光灑在高樓大廈的玻璃幕牆上陽光透過高樓的縫隙灑下,周圍環境充滿未來感,科幻風格,氣氛激昂明朗,HDR高動態。
場景說明:該場景同樣設置兩版關鍵詞,簡單版只給出科技感、城市和視角三個關鍵詞,由模型填充生成剩下的內容;復雜版提示詞同樣使用清影的提示詞調試程序生成,涉及風格、運鏡、場景、環境、色彩、氣氛和清晰度。一方面,該場景主要測試模型在不同顆粒度的提示詞下所生成的視頻內容豐富性;另一方面。“未來”是現實物理世界與想象世界的結合,可以測試模型對於建築、光影和科幻的理解。
同樣先看簡單版:

↑即夢:運鏡角度、色彩等方面做得都很好,突出了科技感,對於提示詞的理解是到位的。

↑可靈:不出錯的方案。建築有畸變,對於“未來”的想象力有一些欠缺,僅僅是城市建築的堆砌。不過能夠在建築外立面添加LED大屏,也算是一個亮點。

↑PixVerse:科幻感十足,交通工具、城市、環境都做得非常到位。不過好像沒有特別理解仰視視角。

↑清影:倒是對仰視視角非常有心得體會,但是色彩和“未來城市”對理解依然還是差一些。
再看復雜提示詞版生成效果:

↑即夢:很優秀的視頻了,除去無人機的物理運動方式不能完全理解以外,對於提示詞和風格的理解和把握非常到位。

↑可靈:依然是不會出錯的方案,有一些畸變,就是看起來好像是北京動物園公交樞紐的實拍是怎么回事。

↑PixVerse:有點抽象的科幻,不太知道該怎么評價。畸變有些嚴重,但科幻感還是很足的。

↑清影:陽光很好,以至於只能看見玻璃幕牆。
除了場景應用,我們還從另外四個維度對所選取的四個大模型進行了測評:
視頻生成質量和清晰度
內容生成准確性、一致性和豐富性
使用成本和價格
生成速度和交互界面
基於「科技新知」的測試情況,在視頻質量和清晰度方面,可靈大模型在四個模型中更勝一籌,例如在生成大熊貓視頻時,其能夠較爲清晰細膩地表現出大熊貓毛發的紋理、質感和色澤;對於物體的邊框勾勒也區分明確,畫面更真實,相對來說物體畸變也是最少的。清晰度方面,幾個大模型生成效果都還不錯,PixVerse效果相對落後。
從准確性和一致性比較,四個模型對於部分提示詞的忽略是普遍情況。對於兩個及以上動詞,通常模型只會關注其中一個,側重選擇哪些關鍵詞和關鍵信息也是考量模型理解能力的重要判斷方式。
從生成視頻的豐富性上,即夢和PixVerse表現較好。在一些除主體元素外的細節方面,二者都在盡量擴充內容,尤其是即夢對光线光影頗有理解。反觀可靈,在這部分則相對保守,主要以保證主體元素和動作不出差錯爲主要聚焦。
從使用成本上,目前四個模型均可以免費或付費使用。具體來看,截至測評日,清影可以無限量使用,可靈、即夢和PicVerse則採用每日贈送積分點數的方式供用戶體驗。除此之外,每家的付費機制各有側重。
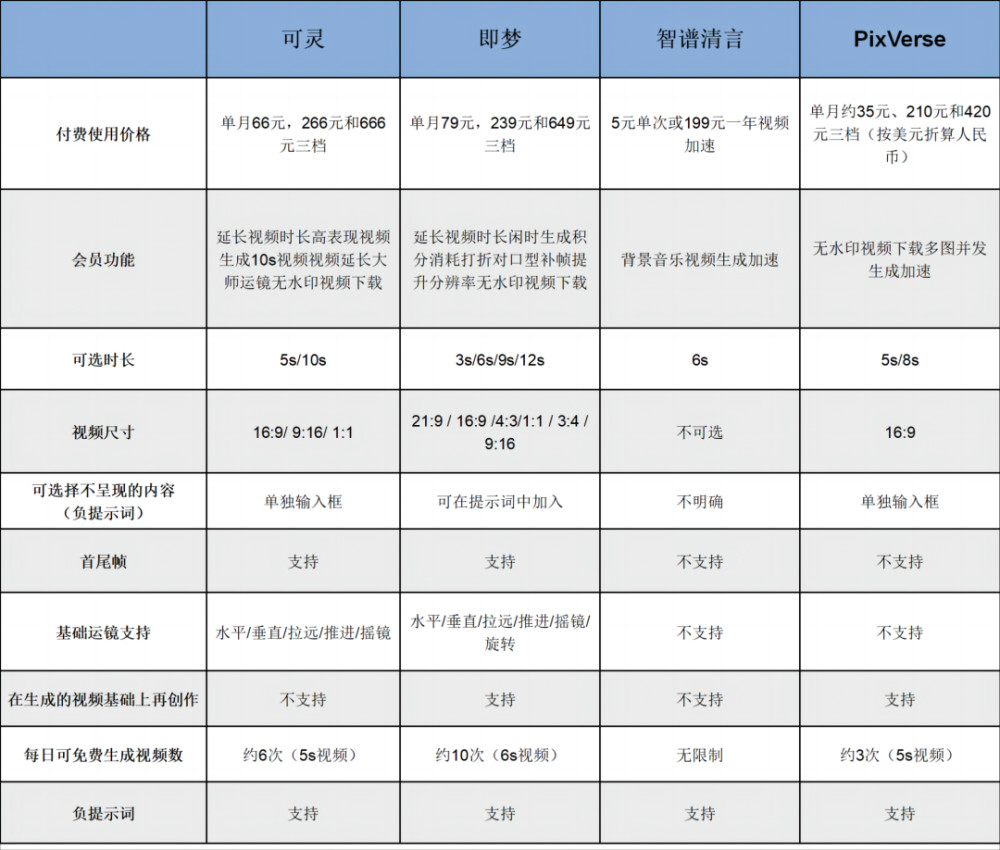
四個頭部AI視頻生成模型對比表
從生成速度上,我們同步實測了幾個模型的生成速度,得到如下結果:
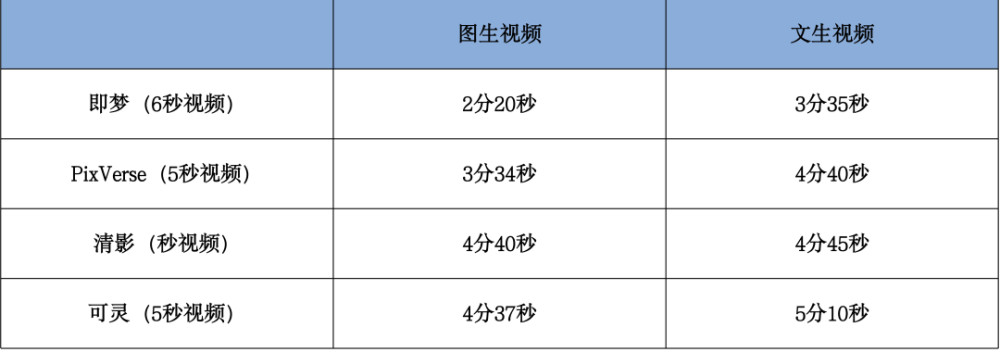
四個頭部AI視頻生成模型生成速度對比表(數據測試時間爲8月3日上午11時)
從交互來看,在注冊登錄門檻上,清影僅採用手機驗證碼注冊登錄,相對簡單;可靈支持手機驗證碼和快手账號兩種登錄方式,默認使用手機驗證碼;PixVerse則遵循海外主流產品的登錄方式,提供谷歌、Discord綁定和郵箱三種登錄方式;即夢帶有一貫的字節系產品特色,比如在電腦端使用產品之前,需要先下載抖音才能掃碼登錄,當然也可以選擇使用手機驗證碼登錄,但又必須授權抖音驗證。
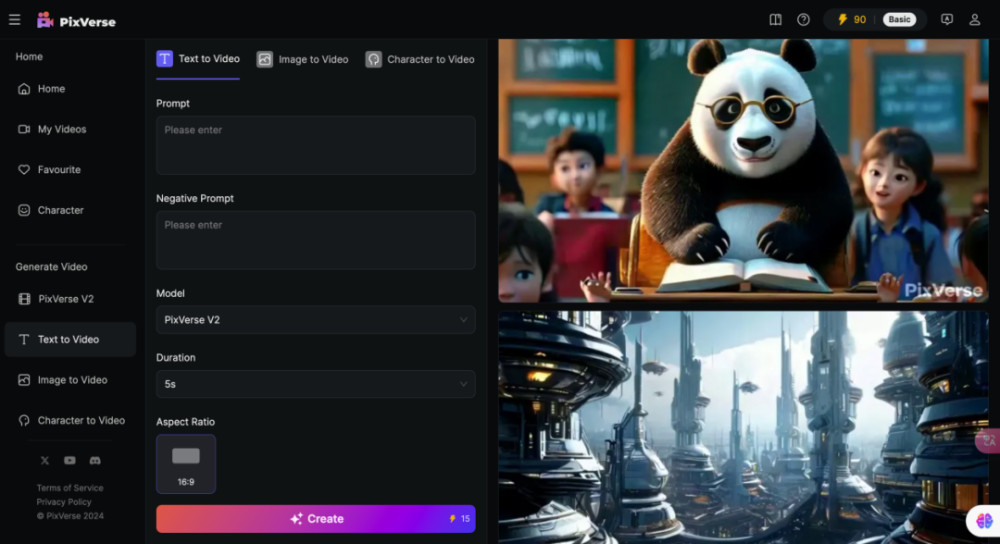
在頁面布局上,PixVerse採用純英文界面,右上角爲账戶等個人信息,左側爲功能性按鈕,界面交互非常簡單,可調節參數也並不多,主要是正向提示詞、負提示詞,模型選擇,時長,畫面比例等。
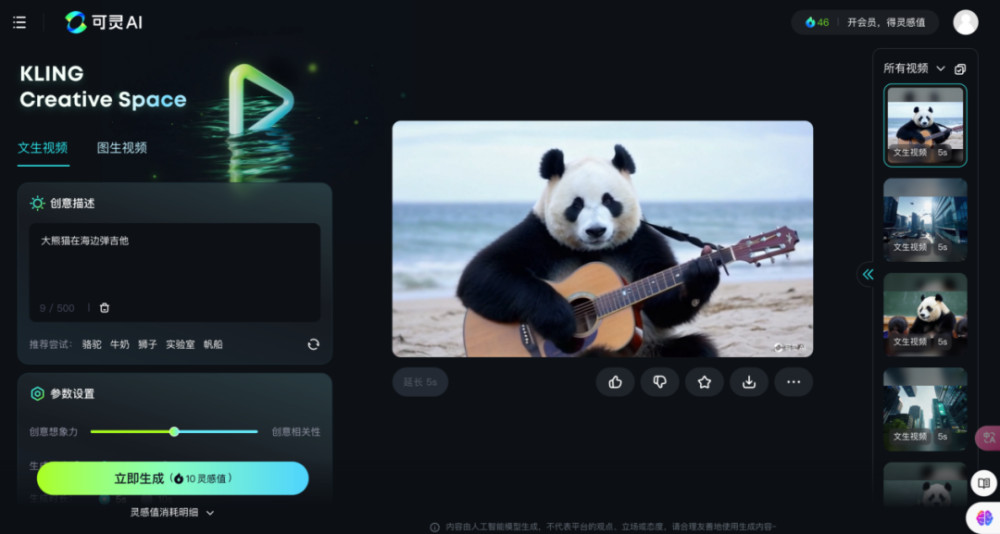
可靈的頁面布局也類似,使用傳統操作台界面,右上角爲账戶信息,左側爲調試台,中間爲預覽窗口,右側爲歷史記錄,動线流暢。可調節等參數包括正向提示詞、創意想象力/創意相關性,生成模式、時長、視頻比例、運鏡、負提示詞等。
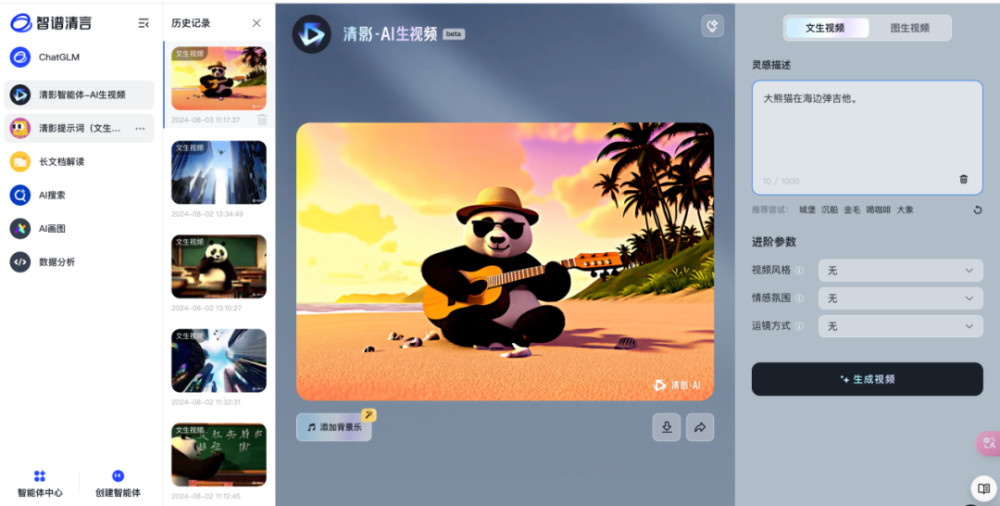
智譜清言將AI生成視頻作爲整個平台的一個子功能,嵌入到平台看板中,因此在界面布局上稍顯雜亂。界面共分爲四個部分,最左側是平台的功能模塊,再到歷史記錄、視頻預覽,對於生成視頻可操作性不高。最右側才是控制台,僅有提示詞輸入,視頻風格、情感氛圍和運鏡方式可以選擇,需要用戶自行探索部分隱性功能,有一定學習門檻。
即夢模型主界面簡潔,總體色調和布局承襲剪映的風格,分爲左側調試和右側預覽兩部分,調試部分與其他模型大同小異。在右側預覽部分,對生成的視頻可以實現延長時長、對口型、補幀、提升分辨率等會員功能,用於對生成視頻的調整,也符合用戶工作流習慣。

測評觀察
總體使用下來,「科技新知」個人的感受是產品使用不及預期,頗有雷聲大雨點小之意。就「科技新知」的測試體驗而言,幾款模型中體驗最好的是可靈,不論是文生視頻還是圖生視頻,相對來說都比較絲滑。對新手用戶來說,不需要掌握非常復雜的提示詞技巧,僅按照模型操作界面的提示,使用純自然語言就能夠達到相對滿意的效果。另一方面,生成的視頻在細節(比如手部)方面處理得較平滑,失誤率較少。對於現階段生成視頻通常需要“抽卡”(碰運氣)的賽道常態來說,減少失誤率就意味着提升質量。
在本次測試場景的反饋中,即夢和PixVerse生成的視頻質量相對不穩定,一定程度上表現出了模型穩定性還有待提升。而清影模型,不知是否因爲訓練素材的原因,生成的視頻總是帶有濃鬱的色彩和卡通風格,讓人不由想起B站“學了五年動畫的朋友”系列。
技術的發展固然鼓舞人心。除了速度提升以外,不少AI視頻生成模型已經初步具備了“理解”世界的能力。即在視頻生成時可以理解物體運動過程中的物理世界,也能預測視頻下一步可能發生什么。
但在實際應用層面,這類大模型的局限也很顯然。5到10秒的可選視頻長度對於用戶來說稍顯尷尬,很難進行任何故事性創作。目前最匹配的領域,或許只能是制作一些表情包或梗圖二次創作。企業並非沒有意識到問題,只是現實很骨感——長度限制是由开發成本導致的。現階段在AI視頻生成賽道上,玩家比的不只是技術,還有資金。爲了“回血”,平台紛紛設計了會員機制,怎奈花的比掙的多得多。
據調查機構 Factorial Funds 的數據,以 Sora 爲例,它 30 億參數(主流猜測 )的訓練成本,比 1.8 萬億參數的 GPT-4 還要多。這還只是訓練,實際使用的推理成本要更多。國內有 AI 企業做過一個折算,生成一個差不多兩分鐘的視頻,企業的成本是 180 元。收取的會員制費用相對於其研發成本來說簡直是九牛一毛。
從這個層面看,像抖音、快手這類擁有短視頻平台的玩家自帶天然優勢。一方面,其訓練數據並不缺乏,另一方面,自身的海量用戶也使企業更容易實現商業化路徑的閉環。但變現門檻也無法忽視。設想一下,如果只是一名普通的C端用戶,除了一开始的新鮮勁兒,如何保證其付費率和付費意愿?
因此,成爲“中國版的Sora”遠不是這場AI視頻大模型競賽的終點,而恰恰只是起點。產品問世之後,誰能找到可持續的商業化之路,落地產業化應用,才是國產AI賽道的終極玩家。
原文標題 : 實測4款國產頭部AI視頻大模型:不及預期、差異明顯
標題:實測4款國產頭部AI視頻大模型:不及預期、差異明顯
地址:https://www.utechfun.com/post/406934.html