
文|白 鴿
編|王一粟
AIGC狂飆一年,算法進步和應用落地的爆發,讓中國雲計算廠商感受着切實的變化。
“今年一季度,大模型企業在雲存儲的消耗同比在增加。”
4月8日,在騰訊雲AIGC雲存儲解決方案升級發布會上,騰訊雲存儲總經理馬文霜同時預計,今年AIGC對於雲端的調用量一定是爆發式的增長。
馬文霜還开半玩笑地說,“可能這些企業拿到的投資更多了”。
隨着多模態技術的進化和落地應用的逐漸爆發,讓大模型的訓練和推理迎來了一些新的挑战。
事實上,從語言和圖像爲主的GPT,到視頻生成模型Sora,大模型參數正在指數級增長。比如ChatGPT在GPT-2時是10億參數量,到現在GPT-4已經有1.8萬億參數。Sora爲主的多模態技術,更會讓需要處理的數據量急劇增加,而這才剛剛是視頻生成模型的GPT-1.0時代。
參數越大,對雲存儲的需求就會越高,包括雲存儲的數據量以及吞吐量等,如果雲存儲能力不能夠滿足大模型的需求,則會直接影響到大模型的訓練速度和推理效率。
在大模型加速發展的階段,大模型企業也越來越重視雲存儲這一重要的底層基礎設施能力。但AIGC時代,究竟需要什么樣的雲存儲技術?
AIGC數據訓練的新需求
雲存儲的新挑战
“內卷”之下,大模型企業开始拼算力、拼參數,更拼大模型的更新速度。
如百川智能,前期平均一個月發布升級一款大模型,百度文心一言在發布之初,甚至一個月內就完成了4次技術版本的升級。
想要保持大模型的更新頻率和速度,就要保證整個大模型數據訓練過程的高效,其中某一個環節出現問題,就可能會拉長整個訓練時長,增加訓練成本。
因此,作爲整個大模型數據訓練的底座,雲存儲的重要性日益凸顯。那么,AIGC時代到底需要什么樣的雲存儲技術?
存儲作爲數據的載體,現如今已經不僅僅只承擔“存”的作用,更需要打通數據從“存”到“用”的最後一公裏。
始於19年前QQ空間的騰訊雲存儲,如今在國內雲廠商中存儲能力一直處於領導者象限(沙利文報告),他們的做法對行業頗有借鑑意義。
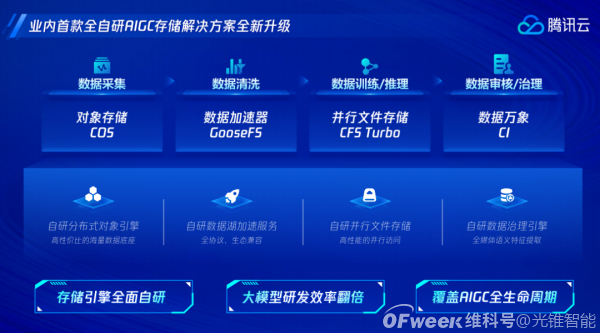
馬文霜向光錐智能提到,在AIGC數據訓練的4個環節中,存儲需要提供的具體能力,包括:
數據採集階段,需要一個大容量、低成本、高可靠的數據存儲底座;
數據清洗階段,需要提供更多協議的支持,以及至少GB甚至TB級的數據訪問性能;
數據訓練階段,作爲大模型訓練的關鍵環節,則需要一個TB級的帶寬存儲保證訓練過程中Checkpoint能夠快速保存,以便於保障訓練的連續性和提升CPU的有效使用時長,也需要存儲提供百萬級IOPS能力,來保證訓練時海量小樣本讀取不會成爲訓練瓶頸;
數據應用階段,則需要存儲提供比較豐富的數據審核能力,來滿足鑑黃、鑑暴等安全合規的訴求,保證大模型生成的內容以合法、合規的方式使用;
在這4個環節中,騰訊雲AIGC雲存儲解決方案,分別由4款產品提供專屬服務,包括對象存儲COS、高性能並行文件存儲CFS Turbo、數據加速器GooseFS和數據萬象CI。
而這次騰訊雲存儲面向AIGC場景的升級,就是基於上述4款產品將大模型的數據清洗和訓練效率提升1倍,整體訓練時長縮短一半。
首先,在數據採集環節,基於自研的對象存儲引擎YottaStore,騰訊雲對象存儲COS可支持單集群管理百EB級別存儲規模,多種協議和不同數據公網接入能力,可以讓採集的原始數據便捷入湖。
數據清洗環節,COS訪問鏈路比較長,數據讀取效率並不高,所以騰訊雲在這中間添加了一層自研的數據加速器GooseFS。
COS通過自研數據加速器GooseFS提升數據訪問性能,可實現高達數TBps的讀取帶寬,提供亞毫秒級的數據訪問延遲、百萬級的IOPS和TBps級別的吞吐能力。
“這讓單次數據清洗任務耗時減少一半。”馬文霜說道。
相比採集和清潔,大模型的訓練則更加耗時,短則數周、長則數月,這期間如果任何一個CPU/GPU的節點掉线,都會導致整個訓練前功盡棄。
業內通常會採用2~4個小時保存一次訓練成果,即Checkpoint(檢查點),以便能在GPU故障時能回滾。
此時則需要將保存的Checkpoint時間縮短到越短越好,但數千上萬個節點都需要保存Checkpoint,這就對文件存儲的讀寫吞吐提出了非常高的要求。
馬文霜表示:“兩年前我們發布高性能並行文件存儲CFS Turbo第一個版本,是100GB的讀寫吞吐,當時覺得這個讀寫吞吐已經足夠大,很多業務用不到。但去年大模型出來以後,用CFS Turbo再去寫Checkpoint,我們發現100G還遠遠不夠。”

CFS Turbo底層技術來自於騰訊雲自研的引擎Histor。此次升級,騰訊雲將CFS Turbo的讀寫吞吐能力從100GB直接升級至TiB/s級別,讓3TB checkpoint 寫入時間從10分鐘,縮短至10秒內,時間降低90%,大幅提升大模型訓練效率。
針對數據訪問延遲問題,騰訊雲引擎Histor可支持單個節點GPU與所有存儲節點進行通信,進行並行數據訪問。“另外,我們通過RDMA(遠程直接地址訪問)等技術不斷優化數據訪問延遲,縮短IO路徑,最終可做到亞毫秒級訪問延遲。”馬文霜說道。
同時,騰訊雲Histor還可以將元數據目錄打散至所有存儲節點上,提供线性擴張能力,從而實現文件打开、讀取、刪除的百萬級IOPS能力。
應用階段,大模型推理場景則對數據安全與可追溯性提出更高要求。騰訊雲數據萬象CI是一站式內容治理服務平台,它可以對AI生成的內容進行一站式管理,可以提供圖片隱式水印、AIGC內容審核、智能數據檢索MetaInsight等能力。
此次升級,騰訊雲重點講述了智能數據檢索MetaInsight,其能夠基於大模型和向量數據庫進行跨模態搜索服務,也就是可以文搜圖、文搜視頻、圖搜圖、視頻搜視頻,並憑借95%以上的召回率,可以幫助用戶快速鎖定目標內容,提升審核效率。
基於這套AIGC雲存儲技術底座,騰訊雲存儲總經理陳崢表示,騰訊自研項目(比如混元大模型)的整體效率至少提升了2倍以上。
目前,除騰訊自己的混元大模型,數據顯示,已有80%的頭部大模型企業使用了這套AIGC雲存儲解決方案,包括百川智能、智譜、元象等明星大模型企業。
而針對解決方案升級後的產品價格,馬文霜則表示,“不會有變化”。在阿裏雲和京東雲都宣布降價時,騰訊雲並沒有選擇降價,而是“加量不加價”。
“穩定性、高性能,以及性價比,是大模型時代雲存儲的核心。”騰訊雲智能存儲總監葉嘉梁說道。
當然,在AIGC時代,雲廠商都想抓住這一次用雲需求爆發的機會。除了騰訊雲外,阿裏雲、華爲雲等其他雲廠商在AIGC雲存儲領域也都有相應的布局。
比如2023年,華爲雲針對大模型時代的雲存儲發布了OceanStor A310 深度學習數據湖存儲和FusionCube A3000 訓/推超融合一體機兩款產品。

阿裏雲面向AI時代的雲存儲解決方案,也覆蓋了底層對象存儲 OSS數據湖、高性能文件存儲、並行文件存儲 CPFS、PAI-靈駿智算服務以及智能媒體管理IMM平台等產品。
可以看到,圍繞AIGC的需求,雲廠商在雲存儲領域迅速更新換代。阿裏雲的思路與騰訊雲非常接近,而華爲雲則加入了自己在硬件方面的優勢。
雲存儲技術僅是雲計算衆多底層核心技術之一,隨着大模型深度發展,雲廠商們已經开始在整個PaaS層、IaaS層、MaaS層,都在圍繞AIGC進行迭代升級,爲行業提供全鏈路大模型雲服務。
雲廠商狂飆
爭做“最適合大模型”的雲
雲已經成爲大模型的最佳載體,大模型也正在重塑雲服務的形態。
馬文霜認爲,雲上豐富的資源、計算、存儲、網絡、容器技術和PaaS,都能夠解決AIGC在各個環節上對資源的訴求。雲還能夠給AIGC提供成熟的方案和豐富的生態支持,讓客戶可以聚焦在自己產品競爭力的方向進行开發,加速整體研發效率以及應用落地的速度。
面對AIGC帶來的大模型發展浪潮,騰訊集團副總裁、騰訊雲與智慧產業事業群COO兼騰訊雲總裁邱躍鵬曾表示,大模型將开創下一代雲服務,騰訊雲要打造“最適合大模型的雲”。
自從大模型熱潮爆發以來,騰訊雲在大模型業務推出上不是最快的一個,但卻是最扎實的一個。
在2023年9月的騰訊全球數字生態大會上,騰訊雲面向AIGC場景推出了基於星脈網絡的大模型訓練集群HCC、向量數據庫以及行業大模型的MaaS服務。
也就是說,騰訊雲從底層智算能力,到中間件,再到上層MaaS,已經實現了全鏈路大模型雲化能力升級迭代,每個業務都很務實。
比如,針對大模型對算力的迫切需求,騰訊雲高性能計算集群HCC爲大模型訓練提供高性能、高帶寬、低延遲的智能算力支撐。通過自研星脈網絡,能提升40%GPU利用率,節省30%~60%模型訓練成本,提升AI大模型10倍通信性能。利用星星海自研服務器的6U超高密度設計和並行計算理念,確保高性能計算。
針對在中間層對數據調度應用的需求,騰訊雲向量數據庫,可爲多維向量數據提供高效存儲、檢索和分析能力。客戶可將私有數據經過文本處理和向量化後,存儲至騰訊雲向量數據庫,從而創建一個定制化外部知識庫。在後續查詢任務中,這個知識庫也能爲大模型提供必要的提示,輔助AIGC應用產生更精確的輸出。
而針對行業大模型开發與落地應用服務,騰訊雲則在整個雲底座之上推出了MaaS服務解決方案,爲企業客戶提供涵蓋模型預訓練、模型精調、智能應用开發等一站式行業大模型解決方案。
其中,值得一提的是騰訊雲是業界最早提出走“向量數據庫”路线的雲廠商,在大家對大模型部署還尚有技術路线爭議之初,騰訊就做了這個選擇。目前,向量數據庫+RAG(檢索增強)也已經成爲業內使用頻率最多的大模型部署路线。
可以看到,在回歸“產品優先”战略後,騰訊雲在大模型時代的打法也逐漸清晰——不盲目追隨行業,而是基於對AIGC的理解,做自己的產品迭代。
不過,面對十年一遇的大模型機會,華爲雲、阿裏雲、百度雲等雲廠商也都在2023年爭先恐後地布局,騰訊雲的壓力並不小。
過去一年,華爲雲構建了包括以華爲雲昇騰AI雲服務爲算力底座、行業首個大模型混合雲Stack 8.3,在MaaS層用盤古大模型在千行百業中落地。華爲雲還上线了昇騰AI雲服務百模千態專區,收錄了業界主流开源大模型。可以看到,華爲雲集成了算力、政企、行業、生態等多方面的優勢,可謂火力全开。
阿裏雲則是國內大廠中唯一做开源大模型的公司,說明心態最爲开放、做平台的決心最強。阿裏雲在智能算力底座之上,打造了以機器學習平台PAI爲核心的PaaS服務,以及上層MaaS服務。其中,在开發者生態層,截至2023年11月1日,阿裏雲發起的AI模型社區魔搭已經有超過2300個模型,开發者超過280萬,模型下載次數也超過了1億多次。

雲廠商們掀起了新一輪廝殺,是因爲大模型的紅利。
AI的發展正在帶動用雲需求的增長,並已成爲雲計算產業發展的第二增長曲线。畢竟,大模型的算力使用幾乎可以說是“無底洞”,此前業界曾預測OpenAI訓練GPT-4可能使用了大約10000-25000張GPU,以及微軟的雲上算力支撐。
因此,在AIGC時代,各大雲廠商都在探索如何基於AI重塑雲計算技術和服務體系,开闢全新的服務場景和服務內容,從而能夠抓住這輪AI大模型升級發展所帶來的機會。
大趨勢下,Cloud for AI不僅是雲廠商的新機會,也是必答題。陳崢也表示,雲廠商現階段所能夠做的就是提前進行技術產品布局,並將整個數據價值开放給客戶,從而讓客戶更好的利用數據。
原文標題 : AIGC時代,需要什么樣的雲存儲?
標題:AIGC時代,需要什么樣的雲存儲?
地址:https://www.utechfun.com/post/356905.html