
《教父》電影中有句話:“千萬不要讓外人知道你想幹什么”,這句話似乎也可以用在蘋果2023年前11個月的AI表現上。
今年5月,外媒報道蘋果擔心ChatGPT、Copilot等AI工具收集機密數據,禁止員工在工作中使用。
今年6月,在蘋果全球开發者大會上,庫克甚至都沒提AI,而是同義替換爲ML。
但如果說蘋果不在意AI,顯然不可能。畢竟追溯到2010年,蘋果就以2億美元的價格收購了Siri團隊,雖然這么多年過去了,它還是那么“弱智”。
今年7月,彭博社報道稱,蘋果內部研發了自己的AI框架Ajax和聊天機器人AppleGPT。其中Ajax基於Google Jax搭建,而AppleGPT則類似於ChatGPT。不過,二者看起來沒有什么創新之處。
今年10月,蘋果又掏出了开源多模態大模型Ferret,擁有70億和130億兩個參數版本。但因爲目前只對研究機構开放,也沒激起什么浪花。
同樣是10月,彭博社報道稱,蘋果非常“焦慮”,並已啓動一項龐大的追趕計劃。該計劃由機器學習和人工智能主管John Giannandrea和Craig Federighi領導,服務部門高級副總裁Eddy Cue也參與其中,預算爲每年10億美元。
有點諷刺的是,早在2020年,John Giannandrea就在訪談中肯定了蘋果的AI战略,並表示蘋果不會向外說太多自己的AI能力。
到底是不能說太多,還是其實沒有太多。總之,太多傳言吊足了大家的胃口。
雖然你可以說,作爲一家主打硬件的公司,蘋果今年至少發布了Vision Pro,其中數字分身、場景與動作識別等功能都和AI技術有關。
但驕傲止步於11月份AI Pin的刷屏。半個煙盒大小的“領夾”只通過“聽”和“看”就能理解用戶需求,並用AI軟件執行任務,被一些人視爲“天生的iPhone殺手”。更重要的是,AI Pin背後的金主爸爸包括微軟、OpenAI 等一系列讓蘋果“焦慮”的對象。
眼看狼群要全方位包抄了,蘋果終於在2023年即將結束之時,放出了兩篇論文。
其中一篇題爲《LLM in a flash:Efficient Large Language Model Inference with Limited Memory》的論文提出:蘋果通過一種創新的閃存利用技術,成功地在內存有限的 iPhone 和其他蘋果設備上部署了LLM,這一成果有望讓更強大的 Siri、實時語言翻譯以及融入攝影和AR的尖端 AI 功能登陸未來 iPhone。
在2024年,這條“大模型+硬件”路线或許會直接改變競爭格局。
01 打破內存牆,將大模型放在閃存裏
先放數據結論。論文顯示,在Flash-LLM技術的加持之下,兩個關鍵領域得到優化:1、減少閃存傳輸的數據量;2、讀取更大、更連續的數據塊。
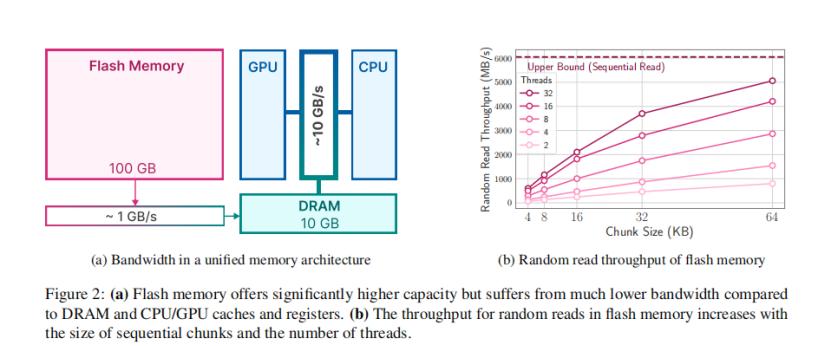
優化之後,設備能夠支持運行的模型大小達到了自身DRAM的2倍;LLM的推理速度在Apple M1 Max CPU上提高了4-5倍,在GPU上提高了20-25倍。
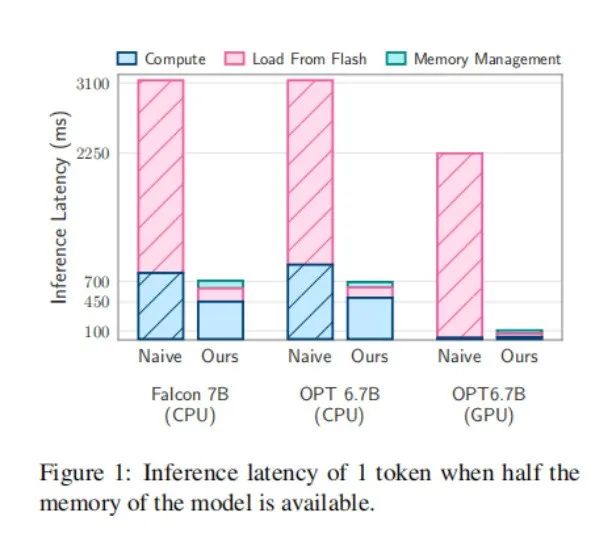
Flash-LLM是如何做到的呢?採用了兩種主要技術:
第一、 窗口化技術(windowing),通過重復使用先前激活的神經元來战略性地減少數據傳輸。大大減少了從存儲器(閃存)到處理器(DRAM)的數據傳輸量。
第二、行列捆綁技術(row-column bundling),根據閃存的時序數據的訪問強度量身定制,增加從閃存讀取的數據塊的大小,改變了數據的存儲方式。
舉個我們曾在《虧了幾個億, AI項目到底怎么投?看歐洲老牌風投Index如何押寶》中舉過的“圖書館”例子。
假設,你拿着列有20本書的書單去圖書館找書,但這家圖書館就像英劇《Black Books》一樣,書本擺放得雜亂無章。你幾乎要從頭走到尾,才能全部定位出你要找的所有書。
想象一下,你找書時,需要“眼睛”和“腦子”對账。按照常理,你不會每看到一本書,就從書單裏找對應。因爲你的大腦已經“閃存”了“重點書名”。
你要做的,只是從當下視线掃過的範圍內找出書單上的書。
窗口化技術(windowing)就是這樣,相當於先用一個算法稀疏化 LLM 的權重矩陣,只保留一部分重要的元素,從而減少計算量,提高計算效率。
同時,因爲你一共要找20本書,總不能像狗熊掰玉米拿一本扔一本,因此你需要一個小推車。行列捆綁技術(row-column bundling)就是這個小推車,幫助每次從閃存中讀取的數據塊更大,也提高了數據讀取效率。
速度和大小的雙重突破,或許很快可以讓大模型在iPhone、iPad和其他移動設備上流暢運行。
盡管這種方法也存在一些局限性,包括主要針對文本生成任務,對其他類型任務的適用性還需進一步驗證,以及處理超大規模模型的能力有限等等。
02 迎接 Vision Pro 上市,30分鐘生成“數字人分身
第二篇論文《HUGS: Human Gaussian Splats》雖然不比上一篇驚豔,但也足夠讓人眼前一亮。
這篇論文詳細介紹了一項名爲 HUGS(Human Gaussian Splats)的生成式 AI 技術,蘋果研究員兼HUGS論文作者之一的Anurag Ranjan介紹:HUGS僅僅需要一個約50-100幀的原始視頻,相當於2到4秒24fps的視頻,就能在30分鐘內生成一個“數字人分身”。
據悉,這比包含NeuMan、Vid2Avatar在內的其他方式要快約100倍。
根據Ranjan在X上發布的視頻,畫面右方的三個數字人分身正在草坪上快樂跳舞,頗爲魔性。
蘋果表示,雖然當前的神經渲染技術比早期有了顯著的進步,但依然最適合用在靜態場景中,而不是在動態場景中自由移動的人類。
HUGS則是建立在3DGS(3D Gaussian Splatting)和SMPL身體模型技術的基礎上,創建數字人分身。當然,目前HUGS技術無法捕捉每個細節,但對於未能捕捉並建模的細節元素,HUGS會自動填充。
而3D虛擬數字人是VR頭顯進一步發展的必然要求。
例如,在去年Meta發布了Codec Avatar 2.0版本,比1.0進一步完成了逼真的數字人效果。
今年,蘋果發布Vision Pro,可以通過前置攝像頭掃描用戶面部信息,基於機器學習和編碼神經網絡,爲用戶生成一個數字分身。當用戶使用FaceTime通話時,數字分身就可以動態模仿用戶的面部及手部動作,並保留數字人分身的體積感和深度。
根據彭博報道,蘋果正在爲Vision Pro上市做最後的准備,發售有望提前至2024年1月下旬。
據蘋果資深分析師 Mark Gurman 爆料,2024年蘋果的精力會重點放在可穿戴產品上(Vision Pro、AirPods、Apple Watch),一向佔據大頭的 iPhone 或將讓位。
這篇論文或許就是迎接Vision Pro上市的准備動作。
03 結語
根據集邦咨詢,從2018年开始,蘋果就悄悄收購了20 多家AI公司,只有少數公开了交易價格。
也就是說,當你以爲蘋果終於慢半拍時,大佬正在觀察、努力,悄悄布局生態,然後像以前無數次那樣,突然一鳴驚人,驚豔所有人。
更可怕的是,此前蘋果所表現的“落後一步”似乎是“以退爲進”,有兩個信息值得注意。
1、外媒報道,最近蘋果正討論“價值至少5000萬美元的多年期合作協議”,並與康泰納仕、NBC新聞和IAC等媒體接洽,以獲取他們過往新聞文章的使用授權。
跟別的科技公司拿了數據直接訓練不同,蘋果是先取得授權,才會拿數據來進行訓練。
這讓人不由聯想到,最近紐約時報指控OpenAI和微軟,未經授權就使用紐約時報內容訓練人工智能模型。而此案可能是人工智能使用知識版權糾紛的分水嶺。
同樣的還有近期Midjourney V6的版權麻煩——利用人類創作者的作品進行AI訓練是否合法?司法如何保護創作者的權益主張?
2、在“談AI安全色變”的氣候下,今年10月,蘋果供應鏈的香港海通國際證券分析師Jeff Pu發布報告顯示:蘋果可能在2023年已經建造了幾百台AI服務器,而2024年將會顯著增加。
他認爲,蘋果在推出生成式AI時前在謹慎考慮如何使用和處理個人數據,以符合其對客戶隱私的承諾。
也就是說,此前蘋果的“慢半拍”似乎是思考如何在尊重客戶隱私的前提下,使用和處理個人數據。在沒有完美的解決方案之前,蘋果則始終保持謹慎。
此外,Jeff Pu在報告中指出:蘋果計劃最早在2024年末开始在iPhone和iPad上實施生成式AI技術。如果計劃得以實現,2024年末的時間表將意味着蘋果可能會從iOS 18和iPadOS 18开始推出生成式AI功能。
至此,這兩篇論文的發布似乎啓動了蘋果王者歸來的時鐘,2024年,群雄逐鹿的人工智能賽道將會更加精彩。
原文標題 : 蘋果AI“圖窮匕見”:將大模型塞進iPhone裏
標題:蘋果AI“圖窮匕見”:將大模型塞進iPhone裏
地址:https://www.utechfun.com/post/312596.html