思路錯了,路走不通。

圖片|Bohdan Kit
©?象限原創
文丨羅輯
編丨程心
AI原生應用,“難產”了。
百模大战後,一衆精疲力竭的創業者們逐漸反應過來:中國真正的機會在應用層,AI原生應用才是下一輪最肥沃的土壤。

▲ 圖片來源於網絡
李彥宏、王小川、周鴻禕、傅盛,盤點過去幾個月的大佬發言,無一不在着重強調應用層的巨大機遇。
互聯網巨頭們把AI原生掛在嘴邊:百度一口氣發布超20款AI原生應用;字節跳動成立了新團隊,主攻應用層;騰訊將大模型嵌入了小程序;阿裏也要用通義千問將所有應用重新做一遍;Wps瘋狂贈送AI體驗卡..
創業公司更是狂熱,一場黑客馬拉松下來,近乎200個AI原生項目。今年以來,包括奇績創壇、百度、Founder Park大大小小加起來,數十場活動,上千個項目,最後卻沒有一個跑出來。
不得不正視的是,盡管我們意識到了應用層的巨大機遇,但大模型並沒有顛覆所有應用,所有產品都在不痛不癢地改造。盡管,中國有最優秀的產品經理,但他們這回也“失靈”了。
從4月份Midjourney爆火,到現在,9個月的時間,匯集了“全村人希望”的國產AI原生應用,究竟爲何難產?
選擇比努力更重要,在當下,或許我們更需要冷靜回望,尋找正確打开AI原生應用的“姿勢”。
做AI原生,不能端到端
原生應用爲何難產?我們或許可以從原生應用的“生產”過程中找到一些答案。
“我們通常會同時跑四五個模型,哪個性能更優就選擇哪個。”硅谷的一位大模型創業者在與「自象限」交流時提到,他們基於基礎大模型开發AI應用,但前期並不綁定某一個大模型,而是讓每一個模型都上來跑一跑,最終選擇最合適的那個。
簡單來說,賽馬機制如今也卷到了大模型身上。
但這種方式其實仍存在一些弊端,因爲它雖然選擇了不同大模型進行嘗試,但最終還是會與其中某一個大模型進行深度耦合,這還是一種“端到端”的研發思路,即一個應用對應一個大模型。
但與應用不同,作爲底層大模型,它同時又卻會對應多個應用,這就導致了同一個場景下的不同應用之間,最後的差異十分有限。而更大的問題在於,目前市場上的基礎大模型都各有所長的同時也各有所短,還沒有某個大模型成爲六邊形战士,在所有領域遙遙領先,所以這導致基於一個大模型开發的應用最終難以在各個功能上實現平衡。
在這樣的背景下,大模型與應用解耦就成了一種新的思路。
所謂“解耦”其實分爲兩個環節。
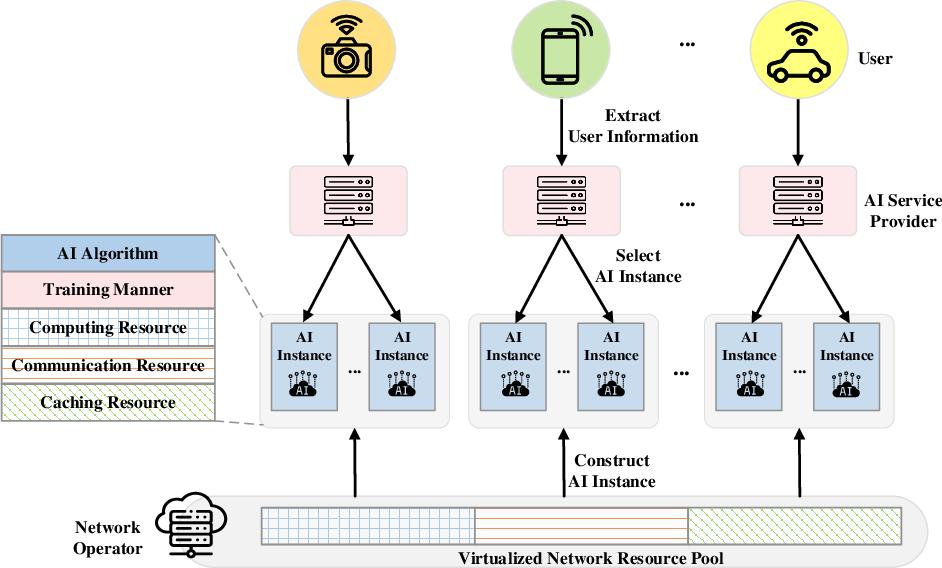
首先是大模型與應用解耦。作爲AI原生應用的底層驅動力,大模型和原生應用之間的關系其實可以和汽車行業進行類比。
▲ 圖片來源於網絡
對於AI原生應用來說,大模型就像是汽車的發動機。同樣一款發動機可以適配不同的車型,同一款車型也可以匹配不同的發動機,通過不同的調教,可以實現從微型車到豪華車的不同定位。
所以對於整車來說,發動機只是整體配置的一個部分,而不能成爲定義整輛汽車的核心。
類比到AI原生應用,基礎大模型是驅動應用的關鍵,但基礎大模型並不應該與應用實現完全綁定。一個大模型可以驅動不同的應用,同一個應用也應該可以由不同的大模型進行驅動。
這樣的例子其實在目前的案例中已經有了體現,比如國內的飛書、釘釘,國外的Slack,都可以適配不同的基礎大模型,用戶可以根據自身需要進行選擇。
其次是在具體的應用當中,大模型與不同的應用環節應該層層解耦。
一個典型的例子是HeyGen,這是一家在國外爆火的AI視頻公司,它的年度經常性收入在今年3月份就達到了 100萬美元,並在今年11月達到1800 萬美元。
HeyGen 目前擁有 25 名員工,但它已經建立了自己的視頻 AI 模型,並同時集成了 OpenAI 和 Anthropic 的大型語言模型 和 Eleven Labs 的音頻產品。基於不同的大模型,HeyGen制作一個視頻就會在創作、腳本生成(文本)、聲音等不同的環節用上不同的模型。
▲圖源HeyGen官網
另一個更直接的案例是ChatGPT的插件生態,最近國內剪輯應用剪映加入了ChatGPT的生態池,在這之後,用戶在ChatGPT上要求調用剪映的插件制作視頻,剪映就能在ChatGPT的驅動下自動生成一個視頻。
也就是說,大模型與應用的多對多匹配,可以精細到在每一個環節選擇一個最適配的大模型進行支持。即一個應用不是由一個大模型進行驅動,而是由數個,甚至一組大模型進行聯合驅動。
多個大模型對應一個應用,集百家之長。在這樣的模式下,AI產業鏈的分工也將被重新定義。
如同當下的汽車產業鏈,發動機、電池、配件、機身每一個環節都有專門的廠商負責各司其職,而主機廠只需要進行選擇和組裝,形成差異化的產品,同時推向市場。
重新分工,打破重組,不破不立。
新生態的雛形
多模型多應用的模式下,將會催生一個新的生態。
按圖索驥,我們試圖根據互聯網的經驗來設想一下新生態的架構。
小程序誕生伊始,所有人對小程序的能力、架構、應用在哪些場景都十分迷茫,前期靠一個個企業從頭开始學習小程序的能力與玩法,小程序的發展速度十分緩慢,數量始終無法突飛猛進。
直到微信服務商的出現,服務商們一手對接微信生態,熟悉小程序的底層架構和格局,一手對接企業客戶,幫助客戶根據需求打造專屬小程序,同時配合整個微信生態的玩法,通過小程序進行獲客和留存。服務商群體,也跑出了微盟和有贊。
也就是說,市場可能不需要垂類大模型,但需要大模型服務商。
同理,每一個大模型需要真正使用和操盤後才能真的了解相關的特性以及如何發揮,服務商在中間層,既可以向下兼容多個大模型,又能夠與企業共創,打造一個良性的生態。
按照以往的經驗,我們可以把服務商粗略地分爲三大類:
第一類經驗型服務商,即了解和掌握每一個大模型的特點和應用場景,配合行業的細分場景,通過服務團隊打开局面;
第二類資源型服務商,如同彼時的微盟能夠拿到微信內的低價廣告位再外包出去的商業模式,未來大模型的开放權限並不是普世化的,能夠拿到足夠權限的服務商,將鑄就前期壁壘;
第三類技術型服務商,當一個應用的底層同時嵌入不同大模型,如何將多模型進行調用和串聯,同時保證穩定性,保證安全性,以及各類技術難題都需要技術服務商解決。
據「自象限」觀察,近半年已經有大模型服務商的雛形开始出現,不過是以企業服務的形式,向企業進行各類大模型如何應用的教學。而做應用的方式也在慢慢形成WorkFlow。
“我現在做一個視頻,先跟Claud提出一個劇本的想法讓它幫我寫成一段故事,再復制粘貼進ChatGPT裏,利用它的邏輯能力分解成腳本,接入剪映插件文轉視頻直接生成視頻,中間的一些圖片如果不精准,用Midjourney重新生成,最後完成一個視頻。如果一個應用能夠同時調用這些能力,那就是一個真正原生的應用了。”一位創業者對我們講到。
當然,多模型多應用的生態真正落實有很多難題需要解決,比如多個模型之間如何互通?如何通過算法實現模型調用的最大化?怎么配合才是最佳的解決方案,這些既是挑战,也是機遇。
從過往的經驗來看,AI應用的發展趨勢,可能會是,分散、點狀的出現,然後逐漸被統一,集成。
比如,我們需要問答、做圖、做PPT,現階段可能是許多個單獨的應用,但未來可能會被集成爲一個整體的產品。向平台化靠攏。比如此前的打車、外賣、訂票等多個業態,現在逐漸集中成一個超級APP裏,不同的需求也會對模型能力提出進一步多元化的挑战。
除此之外,AI原生更會顛覆當下的商業模式,產業鏈上的熱錢將進行重新分配,百度變成了知識的貨架,阿裏變成商品的貨架,所有的商業模式回歸到最本質的部分,滿足消費者的真實需求,冗余的流程就被取代了。
在此基礎上,價值創造是一方面,如何重新構建商業模式,成爲投資人和創業者需要思考的更重要的問題。
當下,我們仍處在AI原生應用的爆發前夜,當逐漸形成了底層是基礎大模型,中層是大模型服務商,上層是各類創業公司。如此層層分工分明,良性協作,AI原生應用才能批量到來。
? 文中配圖來源於網絡
原文標題 : AI原生應用,爲什么難產?
標題:AI原生應用,爲什么難產?
地址:https://www.utechfun.com/post/300905.html