過去幾天,作爲新一輪 AI 浪潮的領頭羊,OpenAI 面臨一次的分崩離析的重大危機,從董事會宣布辭退創始人兼 CEO Sam Altman,到回歸又被否,期間還經歷了多次反轉,包括 Altman 加入微軟、員工逼宮、與 Anthropic(Claude)合並等。
到了北京時間 11 月 22 日下午,OpenAI 又表示原則上同意 Altman 重返 OpenAI 擔任 CEO,並組建新一屆董事會,具體細節還在敲定中。
在事情還沒有正式敲定前就公开披露,可見現任董事會也明白 OpenAI 急需「穩定軍心」,否則競爭對手還會繼續「掏空」OpenAI。緊隨官方之後,Sam Altman 以及之前剛辭任的總裁 Greg Brockman 也都發布了一條暗示回歸 OpenAI 的推文,不管初衷如何,實質上也確實起到了「穩定軍心」的作用。
OpenAI 總裁 Greg Brockman,圖/ X
根據此前公开報道,包括 X(Twitter)、微軟、谷歌、Anthropic 以及一大批有志於這一輪 AI 浪潮的公司都在重金挖角 OpenAI 員工,而很多 OpenAI 員工也在考慮跳槽事宜,這顯然也會嚴重影響到 OpenAI 原定的一系列計劃。
與此同時,競爭對手們也不只是「圍觀看戲」,還希望抓住 OpenAI 犯錯的機會,加快推陳出新的節奏,加速趕超 OpenAI。
Token翻倍、「幻覺」減弱,Claude 2.1終於來了
就在同一天,從 OpenAI 分化出來又背靠谷歌的 Anthropic 發布了新的聊天機器人——Claude 2.1。
作爲 ChatGPT 最有力的競爭者之一,Claude 2 原本就在上下文長度和語言理解上有一定的優勢,同時還較早支持了鏈接和文檔讀取能力。在 Claude 2.1 上,更是將最大支持 Token 數量從 10 萬個增加到了 20 萬個,遠高於 ChatGPT 的最大 3.2 萬個 Token。
Token 相當於機器視角的「字數」。
經常使用 ChatGPT 或者類似聊天機器人的讀者應該都知道,如果在上下文窗口內,一旦對話長度超過了 Token 限制,上下文窗口就會發生變化,聊天機器人會丟失早期對話的內容,等於忘記了之前的對話背景,會直接影響到後面的回答。
甚至不需要超出 Token 限制,只要對話長度到一定階段,機器就會开始遺忘早先的一些背景和要求,需要重復提醒。
圖/ Anthropic
而 20 萬個 Token 的長度,意味着將近 270 頁文檔的上下文和更強的「記憶容量」。換言之,Claude 2.1 用戶現在可以上傳整個代碼庫等技術文檔、S-1 等財務報表,甚至是《伊利亞特》或《奧德賽》等長篇文學作品。
通過能夠與大量內容或數據進行交互,理論上 Claude 2.1 可以更好地進行總結、執行問答、預測趨勢以及對比多個文檔等。AI 創業者兼开發者 Greg Kamradt 在測試中,確實發現了 Claude 2.1 在性能上的進步。
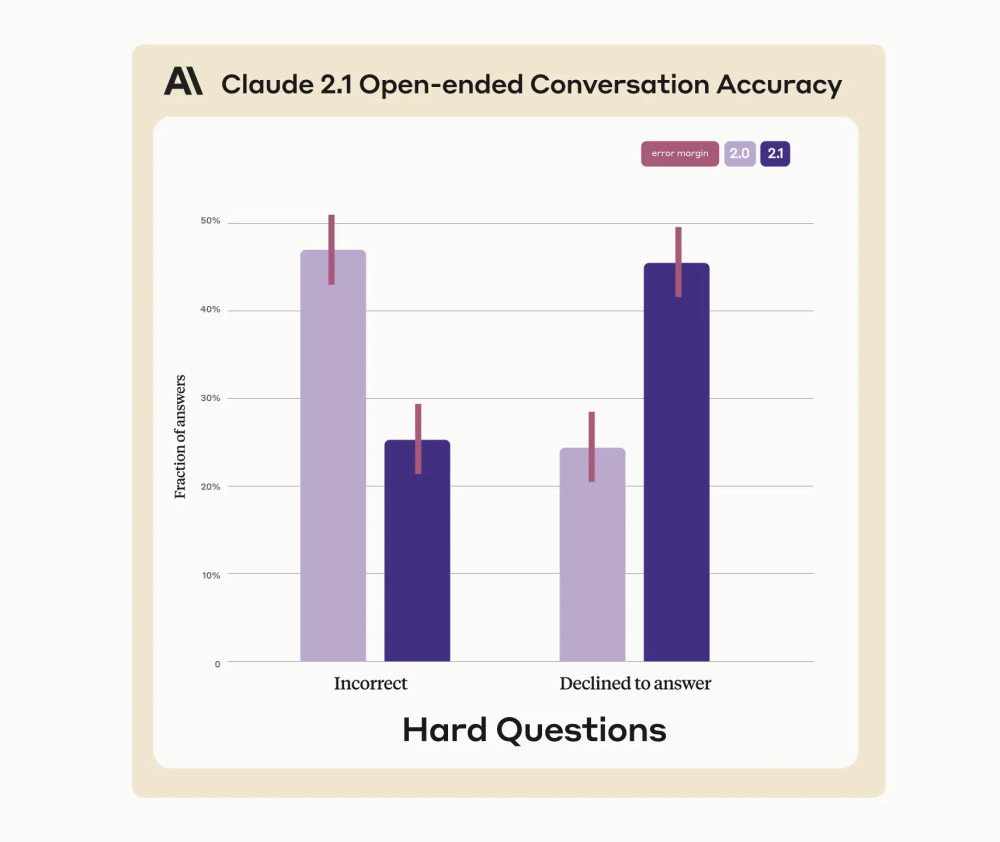
此外,Claude 2.1 在對抗大模型「幻覺」方面也取得了一定進步。與之前的 Claude 2.0 模型相比,Claude 2.1 虛假陳述的概率降低了 2 倍。
圖/ Anthropic
根據 Anthropic 的說法,他們設置了大量復雜的事實問題進行測試,測試顯示 Claude 2.1 在面對錯誤信息以及不確定信息時更可能提出異議,而不是提供不正確的信息。比如反駁用戶給出的「玻利維亞人口第五多的城市是蒙特(錯誤信息)」,或是承認「我不確定玻利維亞人口第五多的城市是什么」。
這使企業能夠構建高性能的人工智能應用程序,解決具體的業務問題,並以更高的信任度和可靠性在其運營中部署人工智能。
視頻版Stable Diffusion發布即开源,再一次改變視頻生成?
文本生成領域有 ChatGPT 和 Claude,圖像生成領域有 Midjourney 和 Stable Diffusion,但在視頻生成領域始終沒有一個模型可以跑出。

AI 生成視頻(動圖經過壓縮),圖/ Meta
這不是說沒有公司嘗試,谷歌、Meta 很早就有公布 AI 生成視頻的 Demo,還有大量初創團隊都在「掘金」視頻生成領域,比如 Runway 就接連發布了 Gen-1、Gen-2 兩代,實現了真正的從零开始生成視頻。當然,Gen-2 仍然存在細節模糊、形態扭曲等等品質問題,所以始終沒能破圈。
Stable Video Diffusion 會改變一切嗎?
還是北京時間 11 月 22 日,Stable Diffusion 背後的公司 Stability AI 發布了旗下首個視頻生成模型——Stable Video Diffusion。
在很多人的意料之中,Stable Video Diffusion 基於圖片生成模型 Stable Diffusion 進行开發而成,Stability AI 已經在 Github 上开源了全部代碼,同時也上线了 Hugging Face 社區。
圖/ Github
要指出的是,目前 Stable Video Diffusion 有兩種輸出形式,能以每秒 3 到 30 幀的可定制幀速生成 14 和 25 幀。換句話說,Stable Video Diffusion 目前最多也只能生成 8 秒左右的低幀率視頻。

圖/ AssemblyAI
但不要低估开源迭代的力量。Stable Diffusion 模型 2022 年最开始發布的時候,圖片生成質量也比不上 OpenAI 的 DALL·E-2。然而由於开源的策略,Stable Diffusion 被各路初創公司、开發者、玩家頻繁應用與改進,最終讓 AI 生成圖片徹底火出圈外,引發了一系列的變化。
同時在开源力量的幫助下,不到半年內 Stable Diffusion 模型就迭代到了 2.1 版本。
誠然,Stable Diffusion 的成功未必能夠復刻,但可以肯定的是,不同於 Gen-2 這類私有模型,Stable Video Diffusion 可以聚集开源社區更多的开發力量,加速視頻生成模型的迭代改進。
生成式 AI,從來不只是 OpenAI
11 月 15 日,Sam Altman 在還沒有被董事會辭退之前就在 X(Twitter)上表示,OpenAI 將暫停新的 ChatGPT Plus(付費)用戶注冊,原因是使用量的激增已經超出了自身的承受能力。直到 11 月 22 日,OpenAI 依然還沒有开放 Plus 用戶注冊。
但與此同時,AI 時代的浪潮還在滾滾向前,Claude 2.1 和 Stable Video Diffusion 的發布之外:
- 谷歌 DeepMind 在最新發布的音樂生成模型中採用了人耳聽不見的「水印」;
- 微軟發布僅 130 億參數規模的「大」模型,官方宣稱其性能比起 700 億參數的 Meta Llama-2 Chat 還要好;
- 在下個月舉行的 re:Invent 大會上,亞馬遜雲(AWS)預計也會重點介紹旗下 Olympus 大模型的能力。

圖/谷歌
今年還有一個可能是最值得期待的大模型——谷歌 Gemini。根據此前半導體研究機構 SemiAnalysis 的報道,谷歌下一代大模型 Gemini 的算力高達 GPT-4 的 5 倍,同時谷歌手握自研 TPUv5 的數量比 OpenAI、Meta、Coreweave、甲骨文以及亞馬遜擁有的 GPU 加起來還多。
在此基礎上,Gemini 還整合使用了強化學習和樹搜索的 AlphaGO,以及機器人、神經科學等領域的技術,擁有語言和視覺兩大能力。OpenAI 的首席科學家 Ilya Sutskever 在 2020 年就表示,僅文字就可以表達關於世界的大量信息,但它是不完整的,因爲我們也生活在視覺世界中。
說到底,生成式 AI 從來不只是 OpenAI 一家公司,不論圍繞 OpenAI 的「大戲」結局會走向何處,都擋不住 AI 大潮的來勢洶洶。
來源:雷科技
原文標題 : OpenAI內鬥這幾天,競爭對手一刻也沒闲着
標題:OpenAI內鬥這幾天,競爭對手一刻也沒闲着
地址:https://www.utechfun.com/post/294893.html