大模型在手機端的落地,不僅僅是AI進入人類生活的开始,也是行業發生顛覆,新老巨頭進行更替的時刻。
將大模型變小,再塞進手機,會給人們的生活帶來怎樣的影響?
最近,榮耀成爲了國內率先的破局者。
7月12日,榮耀了發布一款“革命性”的大模型手機Magic V2。成爲全球首個實現大模型與手機系統融合的廠商。

在榮耀的宣傳中,更加個性化、更注重隱私,並且具備多模態功能的大模型,將會給用戶帶來全新的體驗。
實際上,不只是榮耀,身爲手機芯片龍頭企業的高通,也在近期發布了自身的大模型。
在7月初召开的上海WAIC上,人們看到搭載高通第二代驍龍8芯片的安卓手機直接運行參數規模超過10億的Stable Diffusion,且只需要15秒左右就可以出圖。

更重要的是,這樣的運行,是完全本地化的,只依賴手機本身的算力。
從GPT-3.5到GPT-4.0,曾經需要高昂算力,或者只能跑在雲端的AI大模型,也开始在智能終端設備中落地。
不過,在興奮之余,冷靜的人總不免會問:我真的需要一個在部署在手機大模型么?還是說這只是手機廠商爲挽救疲軟的市場而制造的噱頭?
01 打破APP的壁壘
在人們討論“大模型手機”之前,一個不可忽略的事實是:當今的各類大模型AI,如chatGPT、新必應等,實際上早已推出了各自的手機版APP。
通過這一個個APP,在手機上運行大模型,早已不是什么難事,且與本地部署的方式相比,這些調用雲端算力的APP,並不會對手機配置造成額外負擔。
那既然如此,那人們爲什么還要費盡心機地开發一個專用的“手機版”大模型呢?

對於這個問題,谷歌之前的做法似乎給出了一個可能的答案。
今年5月,在ChatGPT 3.5發布半年後,Google終於公布了全新一代大語言模型PaLM2,用以對抗ChatGPT。作爲一種差異化競爭,PaLM2可以被部署在智能手機上。
當時,PaLM2包含四個大模型,按照參數規模從大到小,分別命名爲:獨角獸(Unicorn)、野牛(Bison)、水獺(Otter)和壁虎(Gecko)。
只有參數最小的“壁虎”可以在手機上運行,Google稱,它的運行速度足夠快,不聯網也能正常工作。

但問題是:人們爲什么要以犧牲參數、性能爲代價,在手機上使用這樣一個“縮水版”的小模型呢?
一個最重要的原因是:與那些以APP形態出現在手機上的大模型相比,一個融入手機系統中的大模型,可以打破各應用之間的壁壘,讓其他App也自帶大模型特性。
例如,融入手機中壁虎(Gecko),可以通過Gmail,實現自動寫郵件的功能。
用戶只需在Gmail的“Help me write”(幫我寫)中輸入需求,它就會結合此前郵件中的信息,寫出完整的郵件。

通過這樣與手機系統深入融合的大模型,人們不僅可以實現AI對各類APP的賦能,甚至還能將大模型作爲通用接口,像“膠水”一樣,將各類APP的能力實現組合,實現更多具有想象力的擴展。
例如,倘若人們在一個陌生的地點出行,想尋找某個罕見、偏僻,在地圖上並不顯眼的位置,這時,手機上的大模型,就可以調用語音+識圖+導航的多模態功能,十分接地氣地告訴你:“在前面的蘭州拉面往左拐,看到城市便捷酒店後再右拐300米”,而不是簡單地說出“直行”、“右拐”等機械的回答。

然而,要實現這樣的組合,一個難以繞开的問題,就是算力。
同樣的,开始在手機上部署大模型的高通,也意識到了這個問題。在高通日前發布的《混合AI是AI的未來》技術白皮書中,首次提出了混合AI架構的概念。
而這一概念,簡而言之,就是讓AI能夠在雲端和終端側進行分布式處理,並根據不同的模型和需求靈活分配負載。
02 改造現實的肢體
也許有人認爲,與在手機上部署大模型的做法相比,在雲端進行計算的方法,才是既省力又劃算的。
然而,實際上隨着日活用戶數量及其使用頻率的增長,雲端推理的成本會顯著增加,而這樣的高成本,也會讓生成式AI的規模化擴展陷入瓶頸。
畢竟,單個AI超算的服務器帶寬,以及消耗的電力,終歸是有上限的,而用戶的增長卻並沒有一個固定的上限。

這就是爲什么混合AI架構,即在雲端和終端側進行分布式處理的AI,會成爲AI的未來趨勢,因爲它能夠利用終端側的計算能力,降低雲端推理的依賴和成本。
而在混合A架構的基礎上,高通還提到,爲實現生成式AI的規模化擴展,AI處理的重心正在向邊緣轉移。
也就是說,將來會有越來越多的AI數據,會在手機、攝像頭、傳感器等終端側進行處理。
那這對大模型的發展來說意味着什么?
截至目前爲止,大部分大模型所能處理的任務,仍舊停留在文字生成、繪制圖片、編寫代碼這些工作上。
這樣的任務,本質上都是屬於出不了辦公室的“案頭工作”。
而AI如果要真正地走進社會,爲更多的行業、群體帶來改變,而不僅僅是一個存在於網頁中的“祕書”,那它就必須具有改造現實世界的“肢體”。

而這樣的“肢體”,正是一個個嵌入各個行業的邊緣端設備。
舉例來說,在醫療領域,AI可以通過智能攝像頭,評估帕金森患者的狀態;
在工業行業,邊緣化的AI可以提高生產過程的智能化和自動化,高效地完成零部件瑕疵檢測等任務。
在農業領域,邊緣化的AI可以通過智能傳感器或無人機,實現對農作物的精准種植和管理,如實現農業病蟲害識別、農作物品質評估等任務。
所有這一切,都是僅存在於網頁中的大模型所無法完成的。
也正因如此,大模型“邊緣化”所帶來的顯著後果,就是AI橫向應用範圍的極大擴展。

如何讓GPT助力農業,已經成爲人們思考的方向之一
而隨着邊緣化的到來,聯邦計算等與之匹配的模型訓練方式,也將打破原本數據中心化的格局。
因爲到了那時,數據並不總是在某一個雲端服務器完成計算,而是由多個參與方在本地訓練機器學習模型,之後再將模型參數或梯度上傳到中心服務器進行聚合。
但詭異的是,依據科技行業發展的邏輯,這樣一種去中心化的、可以實現跨行業或跨領域數據共享的技術,非但不會弱化原有的壟斷行爲,甚至還會進一步將其強化。
03 新巨頭的崛起
在前網絡時代,人們認爲個人網站可以消解大傳統媒體的信息壟斷,但後來互聯網霸主的規模,早已傳統媒體的市值的天花板。
如果將這些科技巨頭的市值,換算成國家的GDP,那么在2022年,微軟的市值就超過了五常之一的俄羅斯(1.7萬億),全球能與之匹敵的經濟體屈指可數。
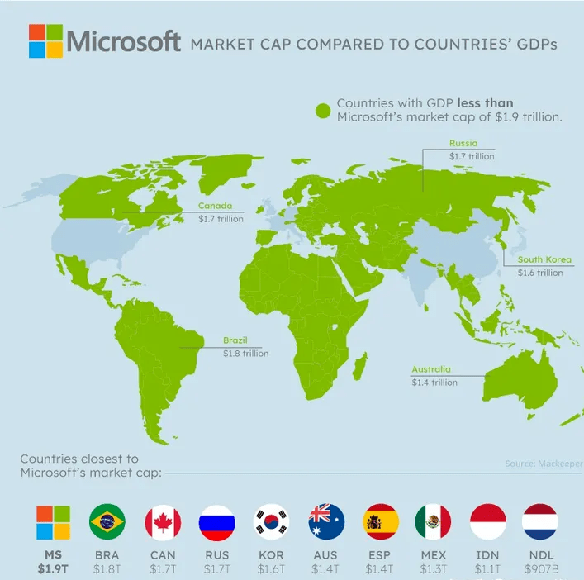
圖中綠色部分,就是GDP低於微軟市值(1.9萬億)的國家
究其原因,是因爲任何“技術平權”的進行,在讓科技變得更加低廉化、平民化的同時,都會反向地催生出一批技術壁壘更高,集中性更強的超級巨頭。
因爲正是有了這些“高壁壘”的技術進行支撐,巨頭們的規模擴張才成爲可能。
例如Meta正是通過一系列數據、算法的優勢,才能對衆多用戶投其所好,並構築了Facebook和Twitter等龐大的社交帝國。
而英偉達也正是通過自身核心的GPU技術,和壁壘頗高的CUDA生態,才讓今天的大模型得以完成海量的計算,才得以讓AI成爲人人觸手可及的技術。

而同樣的,當混合計算的AI,通過雲端與終端側相結合的方式,降低了大模型的推理的成本後,其造成的“技術平權”,至少會造就兩個方向上的巨頭。
其一,就是邊緣化芯片的提供者。
因爲芯片層的AI運算處理能力,是AI落地終端的必要條件。
雖然在邊緣化時代,AI的算力場景是多樣化的,例如工業、醫療、娛樂等,但其中最重要的“七寸”,仍然是在用戶量最多的手機端。
誰若是能圍繞手機端的大模型,形成一套從設計、生產、到軟件生態一體化的完整體系,誰就將成爲新一代的巨頭。
在這方面,身爲行業龍頭的高通,早已开始了提前布局。

目前,搭載驍龍平台的已發布XR終端已經超過65款,其中Meta、PICO等頭部廠商的旗艦產品均採用的是高通芯片。
第二個方向的巨頭,就是能爲行業提供全套解決方案的玩家。
畢竟AI在終端側的落地,需要的不僅是硬件,還有軟件端的優化。
在同樣的硬件基礎上,誰的AI引擎能比其他競品具有更高的效能,能更快地完成計算,誰就將在軟件棧方面更具優勢。
而要想實現這點,就必須在大模型的量化、壓縮、條件計算、神經網絡架構搜索和編譯方面進行突破,在不犧牲太多精度的前提下對AI模型進行縮減。

手機上10億參數大模型生成的圖片
因此,誰能在大模型的壓縮、小型化技術上取得突破,誰就能率先構建起自身基於終端的軟件生態。
綜上所述,大模型在手機端的落地,不僅僅是AI真正具備“肢體”,進入人類生活的开始,也是行業發生顛覆,新老巨頭進行更替的時刻。
在這樣的時代,變革的風暴遠比我們想象的要猛烈。
原文標題 : AI大模型會如何顛覆手機?
標題:AI大模型會如何顛覆手機?
地址:https://www.utechfun.com/post/242207.html