
目標
在本文中,我們將對二手車定價做出預測。我們將使用不同的架構开發多種機器學習和深度學習模型。最後,我們將比較機器學習模型與深度學習模型的性能。
使用的數據
在這種情況下,我們使用了 kaggle 數據集。
有 17 個不同的變量:
IDPrice: 汽車價格(目標欄)LevyManufacturerModelProd. yearCategoryLeather interiorFuel typeEngine volumeMileageCylindersGear box typeDrive wheelsDoorsWheelColorAirbags
要獲取數據並將其用於你的調查,請單擊以下鏈接 -
https://www.kaggle.com/datasets/deepcontractor/car-price-prediction-challenge
數據檢查
我們將在這部分查看數據。首先,讓我們看看數據中的列及其數據類型,以及任何缺失值。
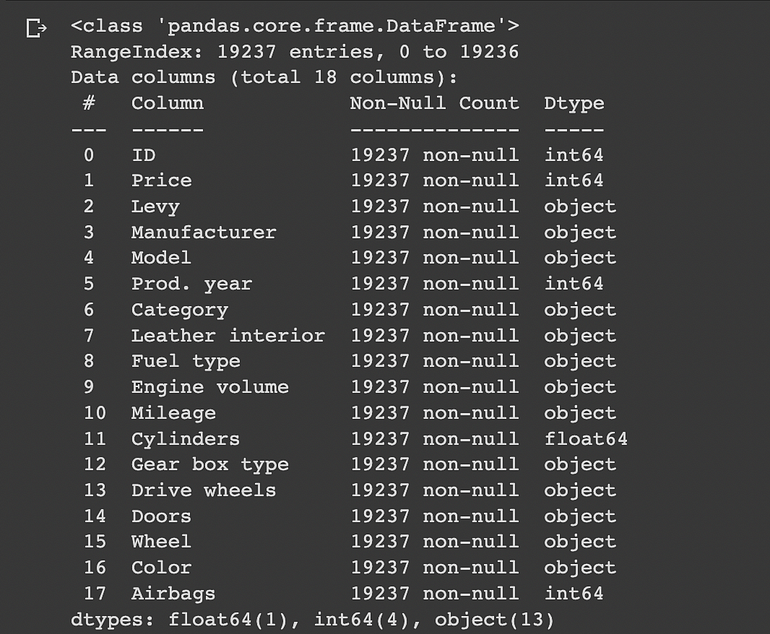
數據集的信息
我們可以看到數據集有 19237 行 18 列。
有五個數字列和十三個類別列。我們可以立即觀察到數據中沒有缺失數字。
“Price”列/特徵將是項目的目標列或相關特徵。
讓我們看看數據分布。
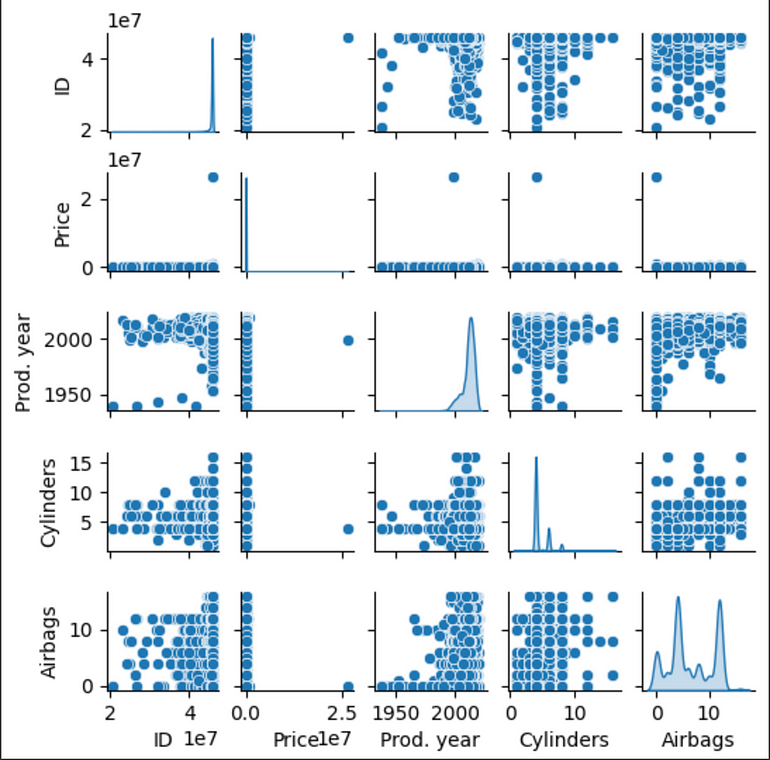
數據准備
在這裏,我們將清理數據並爲模型訓練做准備。
“ID”列
我們刪除“ID”列,因爲它與汽車價格預測無關。
Levy 列
檢查'Levy'列後,我們發現它確實包含缺失值,但它們在數據中表示爲'-',這就是爲什么我們無法在數據中更早地捕獲缺失值.
在這種情況下,如果沒有“Levy”,我們會將“Levy”列中的“-”替換爲“0”。我們也可以用“均值”或“中值”來推斷它,但你必須做出該決定。
Mileage 列
這裏的“Mileage”列表示汽車行駛了多少公裏。每次閱讀後,“公裏”都寫在列中。我們將刪除它。
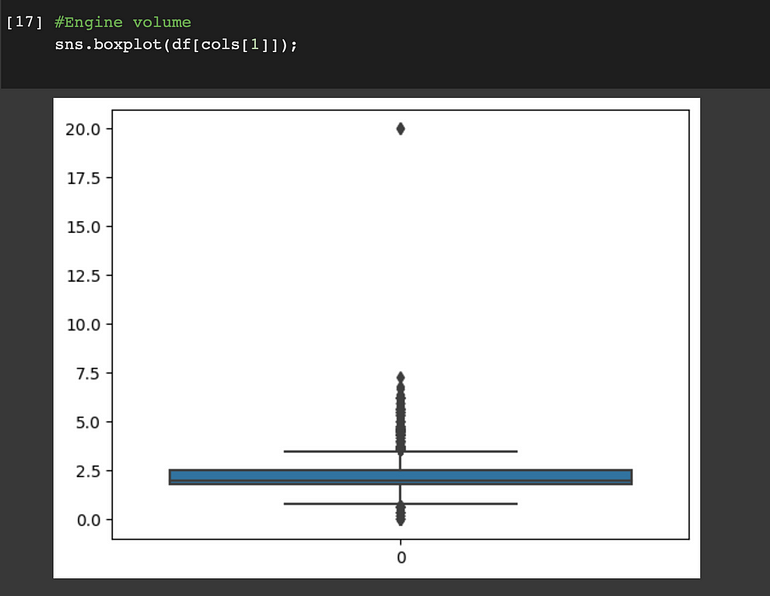
**“Engine Volume”列 **
與“Engine Volume”列一起,還寫入了發動機的“種類”(渦輪增壓或非渦輪增壓)。我們將添加一個新列來顯示“引擎”的“類型”。
處理“離群值”
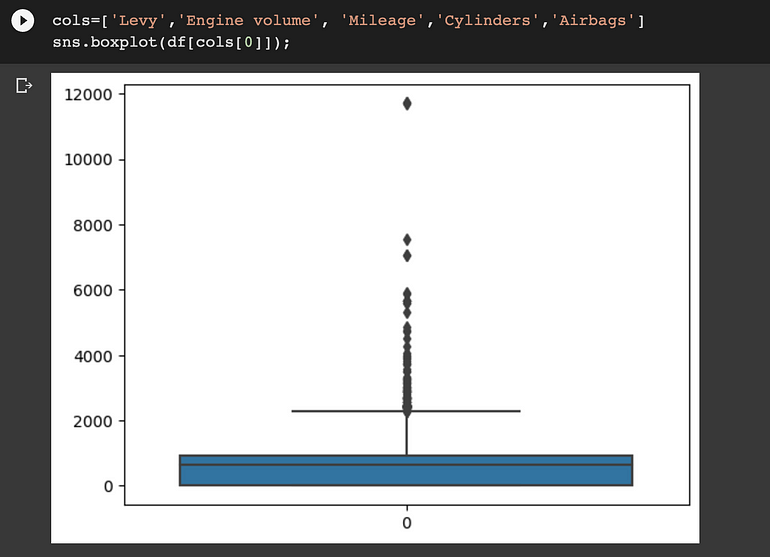
我們將檢查數值特徵。以下是確定異常值的每個數值特徵的快照
Levy:
Engine volume:
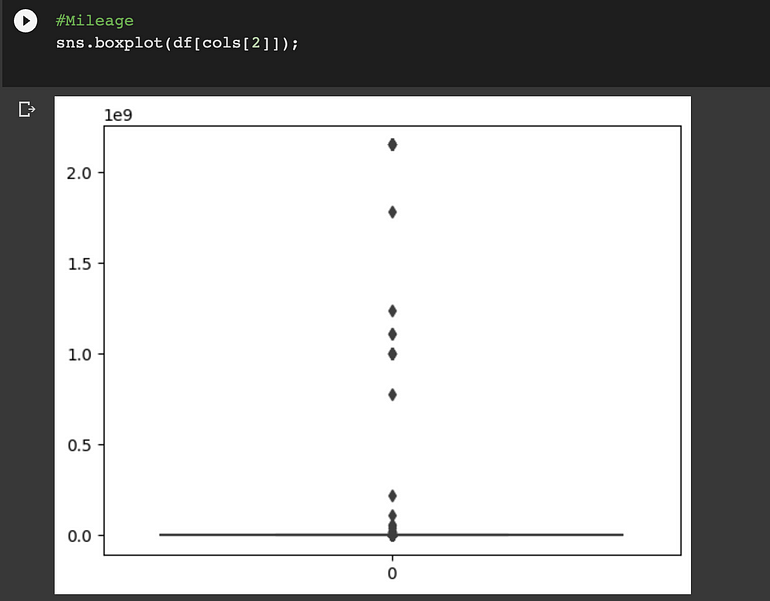
Mileage:
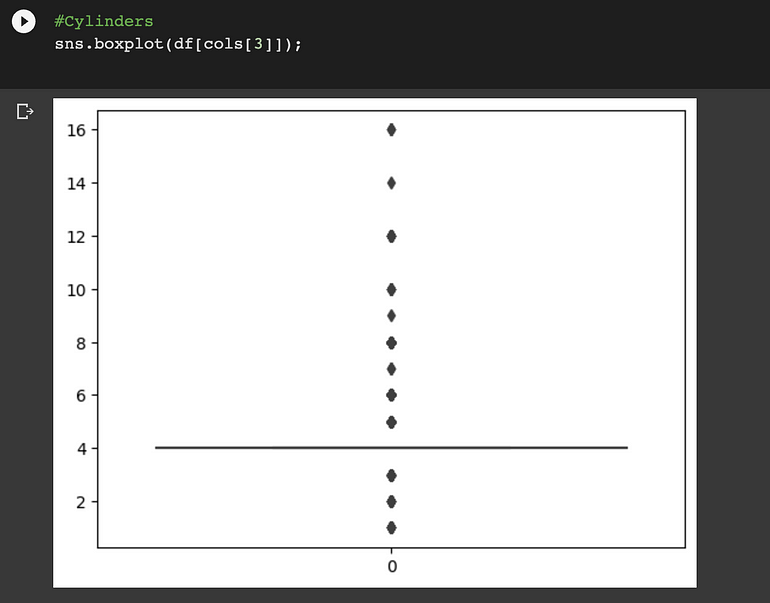
Cylinders:
Airbags:
離群值可以在 ‘Levy’, ‘Engine volume’, ‘Mileage’和“Cylinders”列中找到。我們將使用分位數間距 (IQR) 方法來消除這些異常值。
在統計學中,四分位數間距 (IQR) 是基於將數據集劃分爲四分位數的可變性度量。IQR 是上四分位數和下四分位數之間的差值。它是一種不受異常值影響的穩健的傳播度量。IQR 通常用於識別數據集中的異常值。
要計算 IQR,首先需要計算數據集的第 25 個和第 75 個百分位數,然後通過從第 75 個百分位減去第 25 個百分位來計算 IQR。
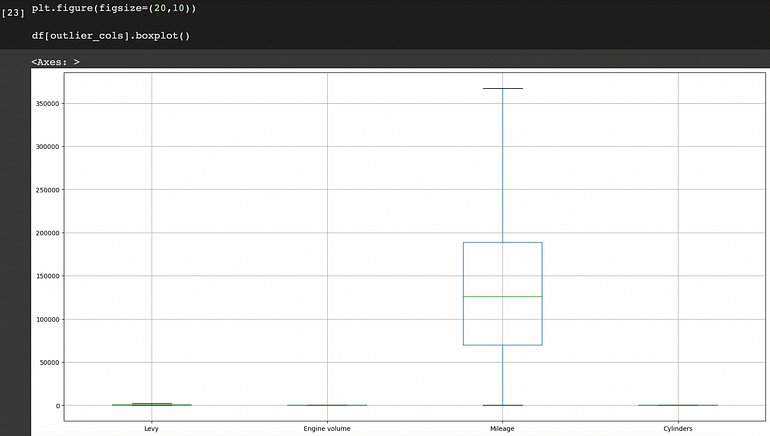
使用 IQR 方法去除異常值後
我們可以觀察到現在特徵中沒有異常值。
开發額外的特徵
“Mileage”和“Engine Volume”都是連續變量。在運行回歸時,我發現對這些變量進行分箱有助於提高模型的性能。因此,我正在爲這些特徵/列开發“Bin”特徵。

用於开發額外特徵的代碼截圖
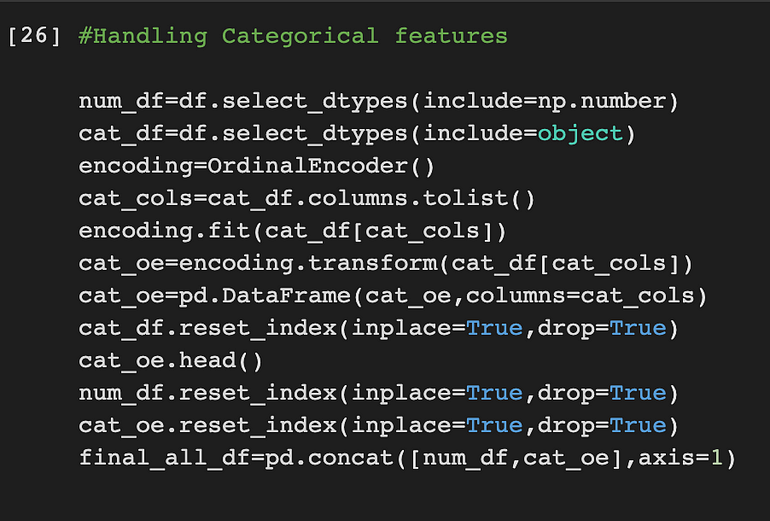
處理分類特徵
處理機器學習中的分類特徵是一項重要任務,因爲大多數機器學習算法都是爲處理數值數據而設計的。分類特徵是表示爲字符串的非數值數據,例如顏色、國家或食物類型。爲了在機器學習模型中使用這些特徵,需要將它們轉化爲數值數據。
有幾種方法可以處理 ML 中的分類特徵。我使用 Ordinal Encoder 來處理分類列
檢查相關性
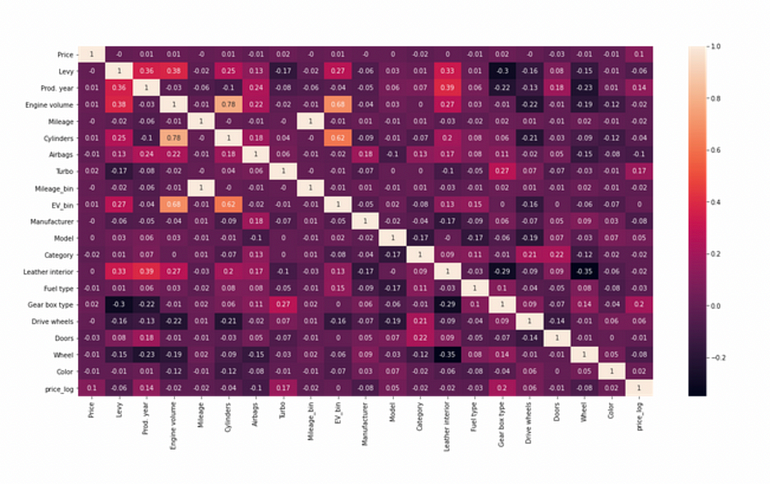
數據顯示,特徵沒有高度關聯。然而,我們可以看到,在對“價格”列進行對數轉換後,與一些屬性的相關性上升了,這是一個積極的事情。我們將利用對數轉換的“價格”來訓練模型。
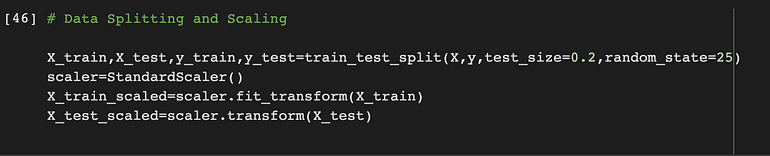
數據拆分和縮放
在數據上,我們將其分爲 80-20。80% 的數據將用於訓練,其余 20% 將用於測試。
我們將另外縮放數據,因爲並非數據中的所有特徵值都具有相同的比例,並且具有不同的比例可能會導致模型性能不佳。
模型搭建
作爲機器學習模型,我們創建了 LinearRegression、XGBoost 和 RandomForest,以及兩種深度學習模型,一種是小網絡,另一種是大網絡。
我們开發了 LinearRegression、XGBoost 和 RandomForest 基礎模型,所以就不多說了,但是我們可以看到模型總結以及它們如何與我們構建的深度學習模型收斂。
深度學習模型——小網絡模型總結
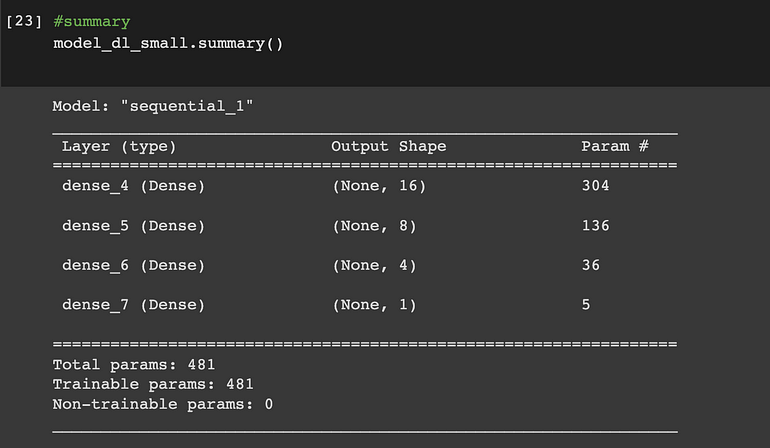
深度學習——小型網絡模型摘要快照
深度學習模型——小型網絡訓練和驗證損失
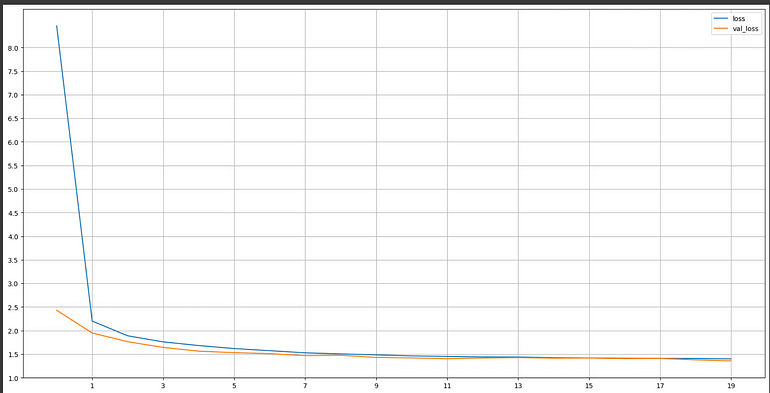
深度學習模型——大型網絡
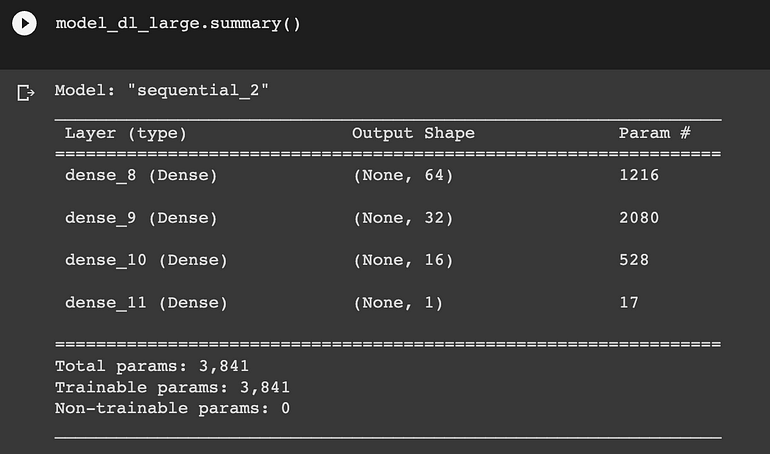
深度學習大網絡模型總結
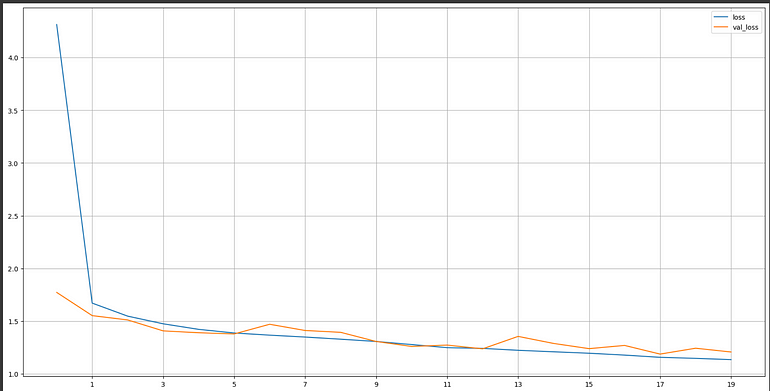
深度學習——大型網絡訓練和驗證損失
模型效率:
我們使用性能矩陣 Mean_Squared_Error、Mean_Absolute_Error、Mean_Absolute_Percentage_Error 和 Mean_Squared_Log_Error 評估模型,結果如下所示。
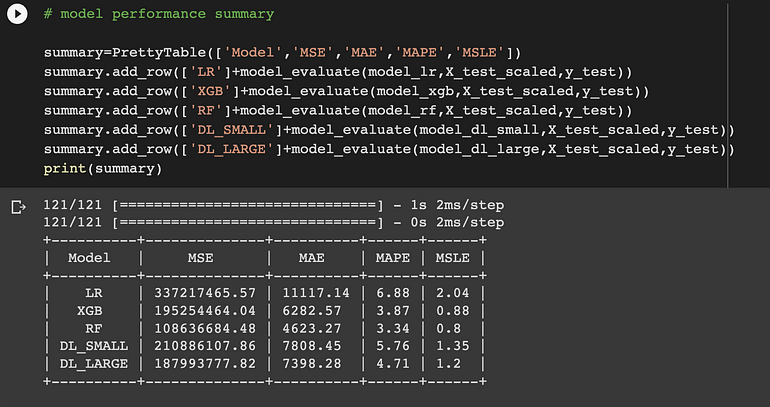
我們應用於數據集的所有模型的摘要
我們可以看到深度學習模型優於機器學習模型。RandomForest 優於所有機器學習模型。
結果
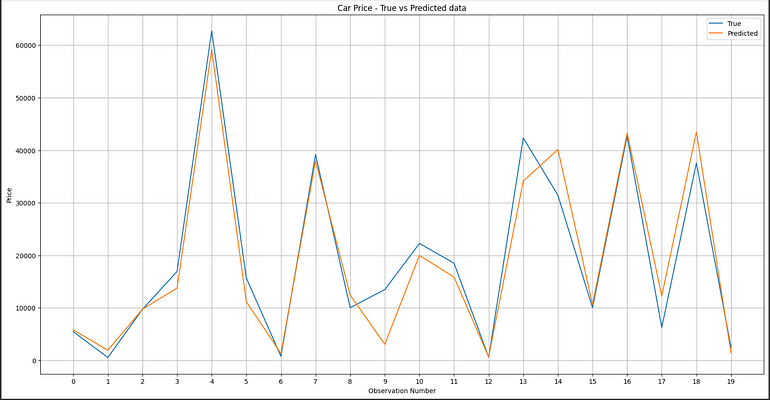
隨機森林模型的可視化
從圖中可以看出,模型的性能非常好,性能矩陣證明了這一點。
特徵重要性
特徵重要性是機器學習 (ML) 中的一個重要概念,因爲它有助於識別數據集中最相關的特徵以預測目標變量。它允許建模者了解每個特徵在預測目標變量中的貢獻,並有助於識別對模型性能無用甚至有害的特徵。
下面我們使用 SHAP 繪制了隨機森林模型的特徵重要性:
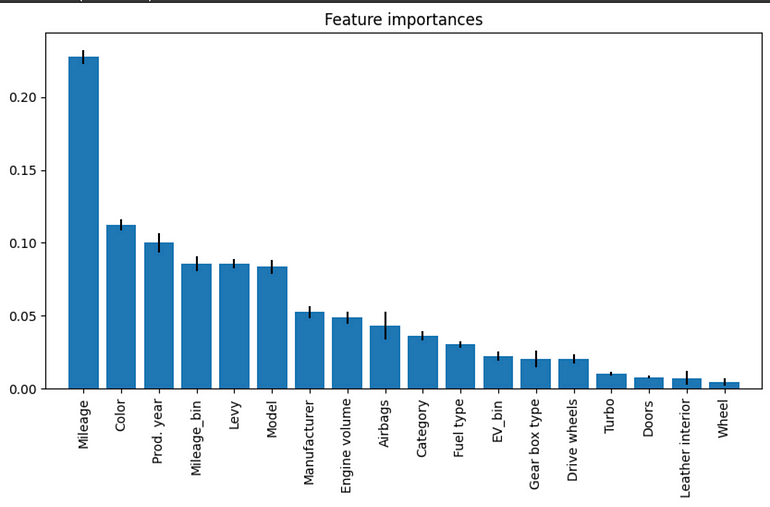
所有變量的特徵重要性快照
結論
在本文中,我們嘗試使用汽車數據中提供的衆多參數來預測汽車價格。我們構建了機器學習和深度學習模型來預測汽車價格,並發現基於機器學習的模型在這些數據上的表現優於基於深度學習的模型。
筆記本參考和代碼:
https://colab.research.google.com/drive/1-ivt7AjvEXMXdglMn5AHlTAMfW5oKT3J#scrollTo=J-2Z03_7_8iq
參考文章:
https://www.obviously.ai/post/data-cleaning-in-machine-learning
https://shap.readthedocs.io/en/latest/index.html
原文標題 : 使用機器學習和深度學習模型預測汽車價格
標題:使用機器學習和深度學習模型預測汽車價格
地址:https://www.utechfun.com/post/221944.html