昨天有讀者私信我,能否解釋一下AIGC和ChatGPT是什么樣的關系?
確實,在短短的6個月時間裏,AIGC、ChatGPT、大模型等新詞匯一下成爲媒體熱詞,加上所謂“人工智能將取代你的工作”之類的焦慮,張棟偉覺得有必要寫這樣一篇科普。

本文將力求簡單化的說明這次人工智能浪潮帶來的新詞匯和它的意義,帶你一文讀懂什么是AIGC、ChatGPT、大模型。
1、什么是AI
AI,人工智能(Artificial Intelligence)的英文縮寫。
AI是研究、开發用於模擬、延伸和擴展人的智能的理論、方法、技術及應用系統的一門新的技術科學。
人工智能是計算機科學的一個分支,它企圖了解智能的實質,並生產出一種新的能以人類智能相似的方式做出反應的智能機器,該領域的研究包括機器人、語言識別、圖像識別、自然語言處理和專家系統等。
工廠裏的自動生產线,小米公司的“鐵蛋”機器狗,火車站的人臉識別通道,科大訊飛的語音輸入法,都是屬於AI系統的應用。
2、什么是AIGC
AIGC,全名“AI Generated Content”,中文直譯就是“人工智能生成內容”,也可以稱爲“生成式AI” (Generative AI)。例如AI文本續寫,文字轉圖像的AI圖、AI數字化主持人等,都屬於AIGC的範疇。
3、什么是大模型
首先解釋,什么是GPT。
GPT的全稱,是Generative Pre-Trained Transformer(生成式預訓練轉換器)是一種基於互聯網的、可用數據來訓練的、文本生成的深度學習模型。
GPT是AIGC的一個種類。
在ChatGPT之前,被公衆關注的AI模型是用於單一任務的,比如全球所知的“阿爾法狗”(AlphaGo)可以基於全球圍棋棋譜的計算,打贏所有的人類圍棋大師。谷歌進一步开發的“AlphaZero”在圍棋、國際象棋和日本象棋等項目上,都是所向無敵。

這種專注於某個具體任務建立的AI數據模型,叫“小模型”。
ChatGPT與這種“小模型”不同,GPT大模型更像人類的大腦。它兼具“大規模”和“預訓練”兩種屬性,可以在海量通用數據上進行預先訓練,能大幅提升AI的泛化性、通用性、實用性。
基於GPT機制建立的AI數據模型,就叫“大模型”。
4、什么是ChatGPT
ChatGPT是由美國OpenAI公司發布的大模型。
由於ChatGPT 3.5展現了超出現實預期的智能數據能力,引發了一場新的全球人工智能競賽。2023年3月,ChatGPT -4進一步提高了AI的能力。
5、中國有ChatGPT嗎?
首先再次強調,ChatGPT是特指美國OpenAI公司的大模型。這是一個產品名稱。
但是,領先的產品,往往會成爲行業代名詞,比如我們說搜索的時候,會簡單的說“百度一下”。但實際上,搜索引擎還有360、Bing、谷歌等其他方式。
目前,我們把與ChatGPT類似的產品,暫時叫“類ChatGPT”產品或者直接叫“大模型”產品。
在ChatGPT火爆以後,中國的科技企業紛紛“趕上潮流”,推出了自己的大模型產品。以下是《中國企業家》雜志統計出的一些知名公司的產品列表。
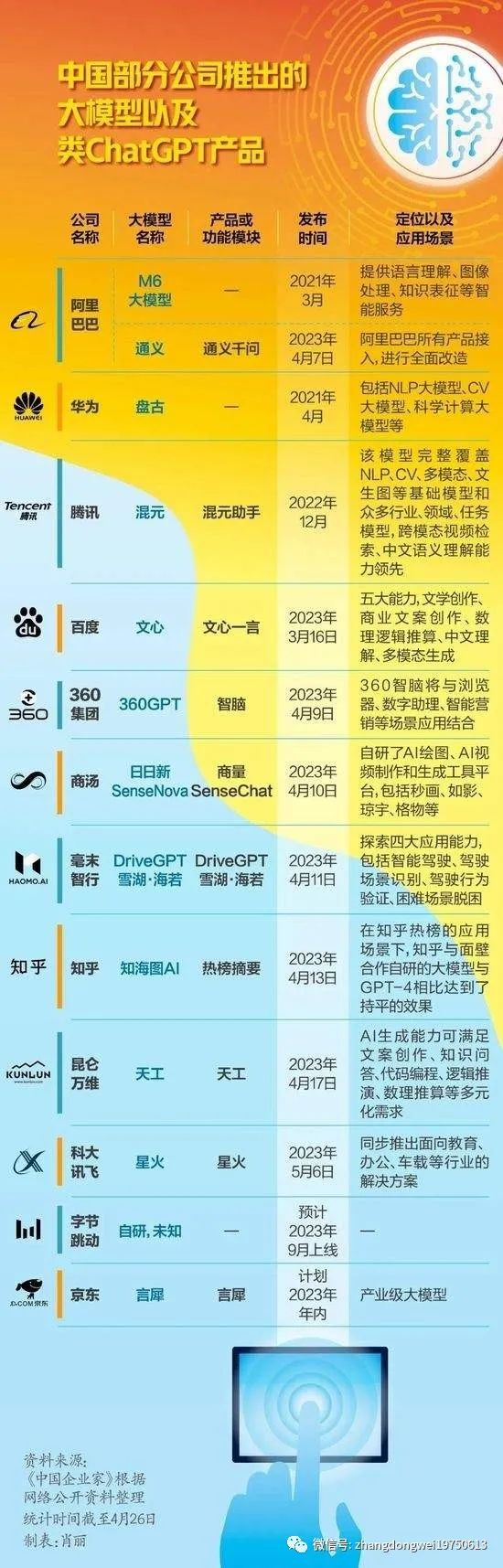
但是,這種復雜的技術模型,顯然不是一朝一夕就能實現。多個國內的大模型被國外技術人員質疑,是用ChatGPT進行“套殼”,用以提升品牌形象和股價。
中國的GPT大模型要成熟,還需要比較多的時間和機會,本文後面部分會繼續說明。
6、ChatGPT有什么用途
ChatGPT是一種能生成文本、圖像等內容的復雜系統。
OpenAI的战略夥伴微軟(Microsoft)已將該技術添加到其Office MS 365辦公套件及搜索引擎必應(Bing)等產品中。
微軟的競爭對手谷歌(Google)也推出了類似的搜索工具Bard。
ChatGPT可以進行從歷史到哲學等話題的對話,生成不同風格的文案、文章、歌詞、詩歌,甚至直接生成計算機代碼,或者對已有的計算機程序代碼提供修改建議。ChatGPT也能處理視覺信息,諸如回答關於照片內容的問題。
ChatGPT是基於從互聯網上搜羅的大量文章、圖像、網站和社交媒體內容,以及與OpenAI人類僱工的實時對話(主要是英語)進行訓練的。實際上,早在2014年微軟公司面向中國推出了AI聊天機器人小冰,目前不知道小冰的對話內容是否也是ChatGPT學習的數據來源之一。
ChatGPT學着模仿寫作的語法和結構,輸出常用表達。它還學習識別圖像中的形狀和圖案,如一只貓、一個孩子或一件襯衫的輪廓。它還可以將單詞和短語與這些形狀和圖案相匹配,允許用戶詢問圖像的內容,如貓在做什么或襯衫的顏色是什么。
因爲ChatGPT的原始數據來自於公开的互聯網,而互聯網上的信息並不總是准確的。因此,ChatGPT給出的答案結果,並沒有經過事實核查,不能100%保證准確,甚至有些完全是“一本正經的胡說八道”。
ChatGPT需要依靠人類員工的反饋來提高准確性。
其他類似的大模型,同樣如此,都需要非常海量的人工能力,來幫助大模型提升准確性。這就是類似於在中國,雖然大家覺得高德地圖、百度地圖、騰訊地圖很智能,但是實際上,它們不僅僅是在調用衛星數據、交通部門數據,還有數以萬計的人工“標記員”在幫助和輔助數據修正工作。
7、ChatGPT之類的大模型是如何工作的?
前面已經說過,GPT的意思是“生成式預訓練轉換器(Generative Pre-trained Transformer),這是大模型的核心技術。
轉換器是在數據序列中尋找長程模式的專門算法。轉換器不僅能學會預測一個句子中的下一個詞,還能學會預測一個段落中的下一個句子以及一篇文章中的下一個段落。這就是爲什么它能夠在長文本中緊扣主題。
由於轉換器需要大量的數據,它的訓練分爲兩個階段:首先,它用通用數據進行預訓練,這種數據更容易大量收集;然後,根據它要執行的具體任務,再利用定制的數據進行微調。
張棟偉在最近的兩篇文章中多次強調,大模型的核心取決於三個因素:數據、算力和場景。
所有的大模型都要受制於該公司所能合法獲得的數據量,還要具備能支撐這些數據的算力。最後,還需要有可以商業化的場景,形成投資-產出的正循環。
8、ChatGPT這樣的大模型收費嗎?
目前,包括美國的ChatGPT,以及國內的各種大模型,都是免費的。需要個人去官網注冊申請。
大模型產品都會提供一個API(應用程序編程接口),允許各公司將該技術整合到自家產品或後端解決方案中。這種企業定制版本,以及面向個人的高級版本,會收費。
需要再次提示的是,上文已經說過,目前大模型都還需要人工進行優化,因此你在大模型輸入的內容,以及大模型給你輸出的答案結果,這些信息都會被开發者公司閱讀到。
所以,請不要輸入隱私數據或敏感的公司信息。
9、政府對AIGC的態度
世界各國政府正在探索規範生成式AI工具的方式,擔心它們可能被濫用於犯罪、傳播虛假信息或威脅國家安全等情況。
4月11日,國家互聯網信息辦公室(簡稱“網信辦”)發布通知,就《生成式人工智能服務管理辦法(徵求意見稿)》向社會公开徵求意見,意見反饋截止時間爲5月10日。
網信辦表示, “國家支持人工智能算法、框架等基礎技術的自主創新、推廣應用、國際合作,鼓勵優先採用安全可信的軟件、工具、計算和數據資源”。
網信辦定義,所謂“生成式人工智能”,是指基於算法、模型、規則生成文本、圖片、聲音、視頻、代碼等內容的技術。網信辦明確研發、利用生成式人工智能產品,面向中華人民共和國境內公衆提供服務的,適用本辦法。
在服務提供者的准入資格方面,《意見徵求稿》要求利用生成式人工智能產品向公衆提供服務前,應當按照《具有輿論屬性或社會動員能力的互聯網信息服務安全評估規定》(2018年11月發布)向國家網信部門申報安全評估,並按照《互聯網信息服務算法推薦管理規定》(2021年12月發布)履行算法備案和變更、注銷備案手續。
《意見徵求稿》詳細地分別對提供生成式人工智能產品或服務,對用於生成式人工智能產品的預訓練、優化訓練數據提出明確要求。
10、AI會搶人類飯碗嗎?
任何最新發明的技術,都會對當下的崗位和未來的工作產生重大影響。
在此前的計算機、互聯網、移動互聯網的技術浪潮中,都會藍領階層產生了重大影響。
當前業內普遍認爲,AIGC將對白領職業產生較大影響。
但是,回首往事,會發現計算機、互聯網、移動互聯網三大革命性的新技術,使得社會經濟變得更加生機勃勃。
這是因爲,經濟學家已經發現,新技術的相關影響往往包含三個方面:
(1)一些勞動者提高了生產力;
(2)部分崗位實現自動化或被合並;
(3)產生出以前不存在的新崗位。
由於新崗位的生產效率,要優於被取代崗位的生產效率,所以實際上整個社會的生產效率是提升的。
但是具體到個人,只能說是:
“最先掌握AI的人,將會比較晚掌握AI的人有競爭優勢”。
這句話,放在計算機、互聯網、移動互聯網的开局時期,都是一樣的道理。
如果你也想盡早掌握AI技術,請關注我。
作者:張棟偉 (資深互聯網人士、市場營銷專家、大學生就業創業導師)
原文標題 : 張棟偉:一文讀懂什么是AIGC、ChatGPT、大模型
標題:一文讀懂什么是AIGC、ChatGPT、大模型
地址:https://www.utechfun.com/post/213388.html