
AMD 自行開發開源模型,客戶能夠使用 AMD 硬體部署模型。透過 AMD 的開源資料、權重、訓練方法、程式碼,讓開發者不僅能夠複製模型,且在模型基礎上進行創新開發。
AMD 近日發表一系列完全開源的 10 億參數(1B)語言模型 OLMo,這款在 AMD Instinct MI250 GPU 從頭開始訓練,可應用於各種應用程式。OLMo 除資料中心使用外,更支援配備 NPU(Neural Processing Unit,神經處理單元)的 AMD Ryzen AI PC 能夠部署模型,使開發者能在個人裝置提供 AI 功能。
OLMo 在 16 個節點上使用 1.3 兆 token 進行預訓練,每個節點配備 4 個 AMD Instinct MI250 GPU(總共 64 個處理器),以三階段完成 OLMo 訓練。
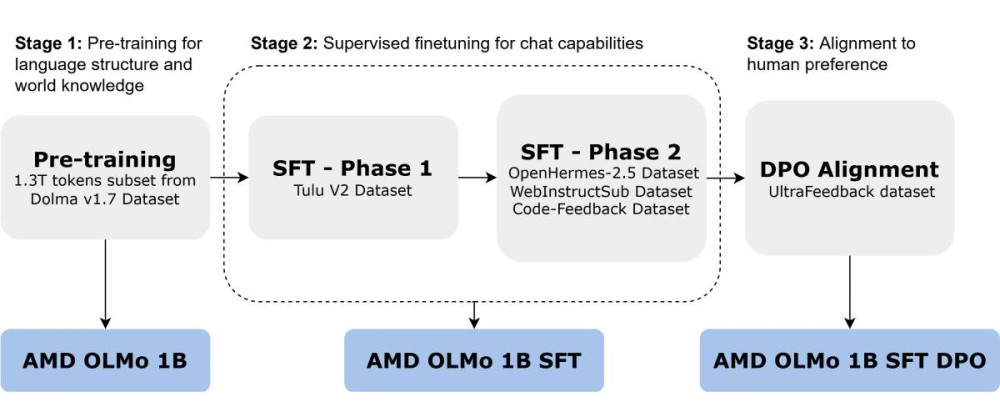
▲ AMD OLMo 訓練三階段。(Source:)
AMD 測試下,OLMo 在一般推理能力和多任務理解的基準測試中,與類似大小的開源模型(如 TinyLlama-1.1B、MobiLLaMA-1B、OpenELM-1_1B 等)相比,表現出令人印象深刻的性能。
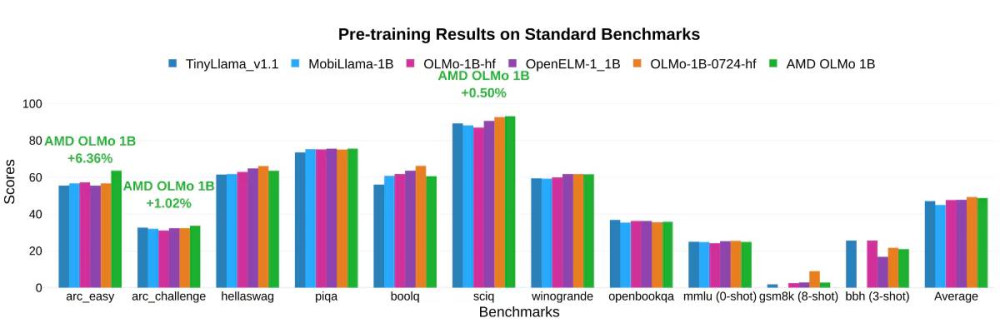
▲ 針對一般推理能力和多任務理解的基準測試結果。(Source:)
兩階段 SFT(Supervised Fine-tuning)模型的準確性顯著提升,MMLU 分數提高 5.09%,GSM8k 分數提高 15.32%,顯示 AMD 訓練方法帶來的影響。最終 AMD OLMo 1B SFT DPO 模型在基準測試平均優於其他開源模型至少 2.60%。
談到 OLMo 在對話基準上的指令調整結果,特別是將 OLMo 1B SFT 和 OLMo 1B SFT DPO 模型與其他指令調整模型進行比較,在 AlpacaEval 2 勝率中 OLMo 表現優於競爭對手 3.41%,AlpacaEval 2 LC 勝率則優於 2.29%。此外,在衡量多回合對話功能的 MT-Bench 測試,OLMo 1B SFT DPO 比最接近的競爭對手多 0.97% 的效能提升。
預訓練和微調模型的能力有助於整合特定領域知識,隨著客戶對客製化 AI 解決方案的需求持續增加,預訓練模型的能力為產業創新和產品差異化帶來更多機會。而 OLMo 新模型的推出,有助於提升 AMD 在 AI 產業地位。
(首圖來源:)
文章看完覺得有幫助,何不給我們一個鼓勵
想請我們喝幾杯咖啡?

每杯咖啡 65 元
 x
1
x
3
x
5
x
x
1
x
3
x
5
x
您的咖啡贊助將是讓我們持續走下去的動力

標題:使用 Instinct MI250 GPU 訓練而成,AMD 發表開源模型 OLMo
地址:https://www.utechfun.com/post/442196.html