繼旗下xAI公司宣布正式开源大模型Grok-1後,特斯拉CEO馬斯克再次在大模型市場扔下一顆重磅炸彈。
當地時間8月11日晚,馬斯克在X平台上透露人工智能模型Grok-2測試版將在不久後發布。事實上,馬斯克在7月份就在X平台上確認,Grok-2將於8月發布,在回應用戶關於訓練數據的提問時,他表示該模型將在這方面做出“巨大改進”。

圖源:X
今年三月,馬斯克曾表示Grok-2將在“所有指標”上超越當前一代的AI 模型。
作爲一個由xAI從頭开始訓練的混合專家(MoE)模型,Grok自2023年11月推出第一版以來,於今年3、4月陸續推出了Grok-1.5大語言模型和首個多模態模型Grok-1.5 Vision,整體迭代速度已足夠驚人。
但要超越當前所有AI大模型,Grok-2要面對的問題或許遠沒想象中簡單。
所有指標超越當前AI大模型,真的假的?
2023年11月,xAI推出其第一代大語言模型Grok時表示,Grok的設計靈感來源於《銀河系漫遊指南》,最初主要爲X上的Grok聊天機器人提供支持,用於包括問答、信息檢索、創意寫作和編碼輔助在內的自然語言處理任務。
最初版本Grok-0僅擁有330億參數,經過數次改良後的Grok-1擁有3140億參數,是當時全球參數量最大的开源大語言模型。
即便這些參數在給定token上的激活權重僅爲25%,Grok-1的激活參數數量也有860億,這比LIama-2的70B參數還多,這意味着其在處理語言任務時具備廣闊的潛在能力。
Grok-1採用了混合專家系統的設計,每個token從8個專家中選擇2個進行處理。在該架構下,根據具體詢問的內容,模型只會激活不同的專家子模塊進行推理,在吞吐量一定的情況下,可以更快地完成推理、給出回答。這讓Grok-1擁有了更快的生成速度和更低的推理成本,簡而言之就是更好的使用體驗和性價比。
根據xAI公布的數據,在GSM8K、HumanEval和MMLU等一系列基准測試中,Grok-1的表現超過了Llama-2-70B和GPT-3.5,不過與第一梯隊的GPT-4差距還很明顯。
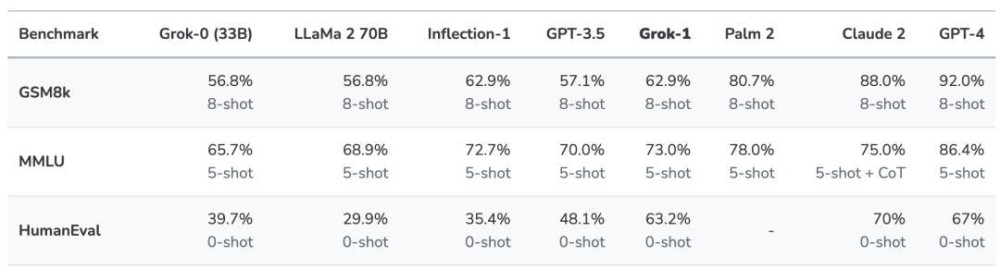
圖源:xAI
來到Grok-1.5,情況已大爲改觀。Grok-1.5不僅具有改進的推理能力和128k的上下文長度,其在編碼和數學相關任務中的表現也得到顯著提升。
在官方測試中,Grok-1.5在MATH基准上取得了50.6%的成績,在GSM8K基准上取得了90%的成績,這兩個數學基准涵蓋了廣泛的小學到高中競賽問題。此外,它在評估代碼生成和解決問題能力的HumanEval基准測試中得分爲74.1%。
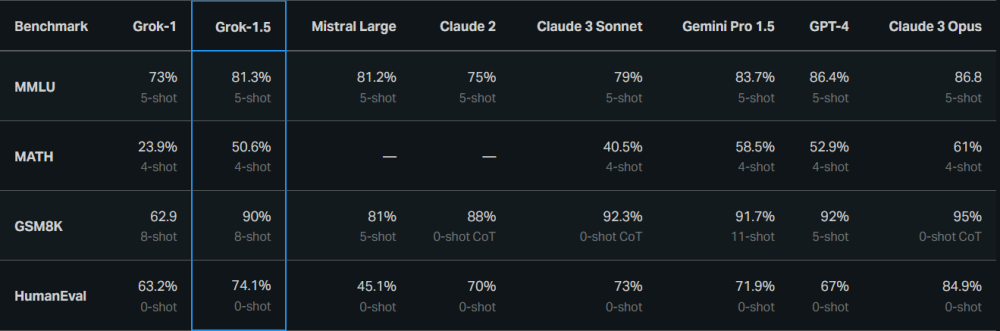
圖源:xAI
基准測試中的整體表現與GPT-4已十分接近,甚至在HumanEval測試上實現了超越。
緊接着xAI發布的多模態模型Grok-1.5V,號稱能連接數字世界和物理世界。不僅多項基准測試可以和GPT-4V、Claude 3 Sonnet、Claude 3 Opus等這些最頂尖的多模態模型對打,還能處理文檔、圖標、屏幕截圖和照片之類的各種視覺信息,支持讀懂梗圖、寫Python代碼的操作。
盡管馬斯克和xAI目前尚未公布關於Grok模型的詳細信息,但按照該模型的迭代趨勢,馬斯克口中將在“所有指標”上超越當前一代AI模型的Grok-2,看來也不是空口無憑。
更大的參數量、更強的性能和速度這些幾乎是板上釘釘的升級,當然最讓我期待的,或許還是年底左右推出的Grok-3,畢竟馬斯克表示該模型的水平將“達到或超越”尚未發布的OpenAI GPT-5,後者被認爲是大語言模型領域的下一個重大突破。

圖源:微博
如果Grok-3真能達到上述水平,那對馬斯克旗下公司的影響將是巨大的,比如陷入用戶增長停滯的X和專注於FSD的特斯拉,前者可以借助大模型爲用戶提供更智能的聊天機器人,打造社交平台的差異化;後者則可以使用大模型語言進行“思維鏈”處理,幫助汽車“端到端”分解視覺復雜場景,解決當前自動駕駛的某些局限。這點在Grok-1.5時,就傳出應用在特斯拉FSD V13的消息。
但不論如何,Grok接下來很可能改變大模型的迭代和應用方式,更可以確定的是,以Grok爲代表的开源大模型,與閉源大模型之間的競爭還在繼續加劇。
开源VS閉源,大模型路线之爭
馬斯克是开源的堅定支持者,其曾多次公开表達對OpenAI閉源商業路线的不滿,並向法院提起訴訟,以違反合同爲由起訴OpenAI及其CEO Sam Altman,要求恢復开源。
xAI的誕生,很大程度上就是爲阻止人工智能領域出現“一家獨大”的局面。諷刺的是,OpenAI的"Open"程度真不如xAI。馬斯克如期开源了3140億參數的Grok-1,遵守Apache 2.0許可證允許用戶自由地使用、修改和分發軟件,無論是個人還是商業用途。
OpenAI是AI領先者,要求其开源ChatGPT背後模型代碼不太現實——除非它自身愿意。但不可否認,無論是國內還是海外,大模型开源都已成爲一大趨勢。
海外,去年7月Llama2宣布免費可商用後,一舉成爲了全球开發者首選的开源大模型。不久後,谷歌也通過發布Gemma开始進入开源大模型的競爭,憑借70億參數碾壓 Llama2-13B(130億參數);國內市場,阿裏宣布开源720億參數的大語言模型通義千問Qwen-72B,性能超越標杆Llama2-70B,號稱最強中文开源模型。
大模型开源、閉源的路线之爭向來是熱點話題,不少行業大佬也發表了自己的觀點。百度CEO李彥宏是“閉源派”,其認爲在同樣的參數規模下,开源模型的能力不如閉源,如果开源模型想要在能力上追平閉源模型,就需要更大的參數規模,這將導致更高的推理成本和更慢的反應速度。

圖源:2024世界人工智能大會
“大模型五虎”之一百川智能的CEO王小川,則是开源派的擁躉,其認爲开源與閉源並非對立關系,兩者並存互補或許才是更優解。他預計,未來80%的企業會用到开源大模型,因爲閉源沒辦法對產品做更好的適配,或者成本特別高。
李彥宏和王小川的觀點沒有對錯之分,只是不同的選擇,大模型开源與閉源的路线本質上是由商業模式決定的。
閉源大模型在保護知識產權、確保數據安全合規等方面具有優勢,但在靈活性和可定制方面可能會受到限制;开源大模型是互聯網成熟的商業模式,盡管最終目的也是變現,但因爲有多方參與,更像是一個整體推動生態前進,比如快速迭代、快速試錯、共創共擔等等。
個人認爲谷歌高級軟件工程師Luke Sernau的表述十分准確:开源模式的迭代進步速度已經威脅到了部分閉源模型的生存,因爲开源方相當於獲得了整個星球的免費勞動力。
這正是开/閉源大模型之爭的根源:不管开發者還是用戶,都更傾向於最好的开源項目,群聚效應可能遠比閉源大模型來得明顯。
寫在最後
按照馬斯克的理念,接下來發布的Grok-2大概率也會开源。面對日益加劇的开源大模型战爭,不管是xAI、谷歌、Meta、阿裏,還是Mistral AI、Databricks以及更多的开源大模型廠商,都還在繼續進行迭代,提高性能、提高效率。畢竟誰也無法篤定在這場快速變化的技術革命中,能不能守住甚至擴大優勢。

圖源:特斯拉
馬斯克給xAI帶來的影響力只是短期的,真正決定xAI未來的還得看Grok的實際表現,它或許可與X、特斯拉業務結合打造AI大模型標杆殺手鐗應用,也可能只是“紙面參數”甚至Sora這樣的“技術期貨”,一切問題,都要等到Grok-2發布那天,才會有更明確的答案。
來源:雷科技
原文標題 : 馬斯克官宣Grok-2測試版!xAI將繼續擁抱开源路线嗎?
標題:馬斯克官宣Grok-2測試版!xAI將繼續擁抱开源路线嗎?
地址:https://www.utechfun.com/post/409551.html