

“芯”原創——NO.53
“芯事重重”是騰訊科技半導體產業研究策劃,本期聚焦科技公司下場自研AI芯片。
文 I 芯潮IC 阿牛
編輯 I 騰訊科技 蘇揚
ID I xinchaoIC
“我們的英偉達芯片儲備,已經跟不上了。”一位AI大模型企業CEO坦言。
受出口管制進一步收緊的影響,A800、H800等中國特供版芯片已經很難正常採購,取而代之的是合規版H20,後者性能大幅縮水,外界也將其稱之爲閹割版。即便如此,H20仍然有可能在今年10月份美國商務部出口管制條款更新當中,同樣面臨出口管制。
《金融時報》援引兩位與英偉達關系密切的匿名人士消息稱,多家中國公司向英偉達下單訂購了共50億美元的芯片。與此同時,一些國產芯片進入科技大廠的視野,但由於工藝、互聯等原因,性能仍有差距,供給也存在挑战。
在這種背景下,多家大公司下場自研,先後在台積電流片,覆蓋5nm、7nm等多個工藝節點,以保證自身AI芯片的供應安全。
出口管制像一把雙刃劍,卡住了算力的脖子,也限制了英偉達的增長,尤其是在客戶自研的背景下,英偉達在大陸的營收开始出現變數。2022財年,中國客戶爲英偉達貢獻了25%的市場營收,而到2024財年,這個比例已下降至個位數。
對英偉達來說,中國大陸的蛋糕縮水,硅谷也在變天。谷歌、蘋果、Meta、亞馬遜、特斯拉等大客戶都在嘗試兩條腿並行,一邊用着英偉達的芯片,一邊下場自研。
中、美大廠自研芯片的邏輯是什么,湧進紅海的科技公司,靠自研芯片能順利上岸嗎?
硬通貨,握在手裏才有安全感
01
大模型和生成式AI熱潮狂卷的當下,算力芯片是科技公司手裏的硬通貨,芯潮IC曾在《天價H100流向黑市》一文中跟蹤過這種“搶算力”的瘋狂與緊張。
把牌握在自己手裏,是大廠自研芯片的根本原因。
在千芯科技董事長陳巍看來,大廠的底牌有三張:保供、降本和競價,籠統來說是一種芯片自主權。
對很多中國大廠,特別是互聯網和人工智能大廠來說,在先進芯片出口管制的背景下,隨時面臨算力斷供風險,下場自研是算力安全的保障。不過,各家开發的芯片主要是內部自用,規格也是針對自家產品定制設計,並非通用型產品。
對“燒錢”堆算力的巨頭們來說,自研是降本的一條路徑。“體量足夠大、需求足夠大,再考慮自研,否則不一定能真的降本。”前台積電建廠專家吳梓豪說。
2021年,馬斯克推出了由自研AI芯片D1打造的Dojo超級計算機,用以訓練特斯拉的自動駕駛系統。據摩根士丹利最新研報,這套系統比用英偉達的A100,足足省下了65億美元。
隨着AI需求興起,雲廠對GPU的依賴性遠遠超過了CPU,對英偉達芯片的需求稱瘋狂,自研也是雲廠搶英偉達訂單的競價籌碼。
一位接近亞馬遜的人士告訴芯潮IC,英偉達的卡並不便宜,DSA大廠如果手握自研的專用芯片,不但可以充分降低在芯片和專利上的平均成本,面對英偉達也能有更好的議價權。
公开資料顯示,亞馬遜不僅設計自己的計算服務器、存儲服務器、路由器,還研發了自己的服務器芯片Graviton。

AWS推出通用Graviton4處理器
據The Information報道,亞馬遜通過Graviton替換英偉達來持續降低價格,客戶租用Graviton服務器,直接節省了10%~40%的計算成本。站在英偉達的角度,要留住亞馬遜這種全球最大的雲廠客戶,就得坐在牌桌上,協商出一個更好的價格。
“這種讓利,有時候不一定完全反映到折扣上,有可能反映在配置上。”
上述知情人士透露,作爲全球頂級的現貨廠商,英偉達如果直接在單價上給予非常直觀的折扣,對產品定價體系的負面影響會很大,不利於產品價格保護,但它們可以通過升級互連設備、升級SSD存儲、增加更多Rack配置等方式,變相給大客戶提供優惠。
還有一種更爲常見的優惠手段——產能傾斜,提供首發權益。
拿到先發優勢,亞馬遜在短期內可以把整機價格定得更高,從整機溢價和配套軟件工具鏈的流通當中,把(折扣)錢“省”出來。
保供、降本和競價之外,有些大廠自研芯片更多是想要保證自身獨特的競爭力。
風雲學會副會長陳經提到,英偉達賣的芯片適用於通用計算,功能很全但也比較貴,但有些客戶只需要特定的功能來強化自身的某些優勢,這種情況下就會考慮自研。
“我只需要做大模型推理,不需要訓練功能,這種情況就可以設計一個功能簡單,但是速度更快,價格便宜的專用芯片,”陳經說。“像谷歌、微軟這些大公司,都有自己的軟硬件系統規範,如何去控制噪音,能耗要到什么級別,英偉達不一定能滿足標准,自己設計會更方便。”
硅谷巨頭當中,谷歌非常在意自身架構、成本和芯片技術的差異化,從2016年起就自研AI張量處理單元(TPU),以便於在大中型訓練與推理中,獲得更好的成本效益和性能,以保證自己的雲計算產品有更好的獨特性和識別度。

谷歌推出第六代TPU“Trillium”
根據谷歌披露的第4代TPU相關數據,與同等規模的系統相比,TPU v4的效率比英偉達A100強1.7倍,節能效率強1.9倍。
除以上幾點外,從生態角度來看,還有一個更深層的原因——打破CUDA壟斷。作爲英偉達研發的編程語言,CUDA是把GPU價格“炒上天”,而客戶又不得不接受的主要原因。
如果雲廠不做自研,即便可以拿到很好的訂單價格,但數據中心超95%的處理器依然要用英偉達GPU,整個雲上AI需求仍要依賴CUDA生態。說到底,命門還是捏在英偉達手上。
隨着雲廠在數據中心配備自研芯片,同時开發很多底層中間件和二進制翻譯功能,幫助客戶遷移至自家生態,對CUDA程序的等價兼容程度會更高,獨家的依賴程度會逐漸減輕。
“這是所有的雲廠都在做的事,即便處理器在整個數據中心所佔比可能不到4%,但依然要堅持做這個事情。”該知情人士說。
有人、有錢,那就下場吧
02
“有人、有錢、有事,同時它還有未來的量,那就可以下場了。”
聯想控股副總裁於浩認爲,大廠做芯片自研的邏輯是比較順,它的客戶就在那兒,這是個明確的優勢。
“‘人’得是有芯片全生命周期實战經驗的‘牛人’,‘錢’得是依托算力業務持續貢獻收入的‘活錢’,這樣一來,大廠依托AI業務閉環,盤點未來可預期的市場漲幅,量化算力需求,完成人和錢的战略統籌,自研芯片水到渠成。”於浩告訴芯潮IC。
不過,坐上自研這個牌桌,入場費至少20億美元起。今年初,OpenAI CEO山姆·奧特曼甚至傳出了籌資7萬億美元造芯片的瘋狂計劃,盡管後來當事人對這一傳聞給予了否認。
據知情人士透露,“每家迭代第一代產品,如果按7納米中間節點去算,加量產至少小20億美金。”
此外,自研芯片更多是自用,可以不考慮建設生態的難度。燃次元援引天鷹資本合夥人的觀點表示:“專用芯片在架構設計上一般不用特別復雜,應用特性也很明確,开發相對快速,因而對於很多互聯網公司來說,他們开發專用芯片就在於有明確場景,不需要花太多財力和時間去搞定軟件生態,工藝IP也成熟。”
理論行得通,具體自研這件事如何才能玩兒得轉?
按照業內認知,芯片自研這件事可以拆分成前、後端兩部分。前端即邏輯設計,是芯片最基本的一些功能,後端是物理設計,是把所有的功能落實到電路並且流片出來的實體。
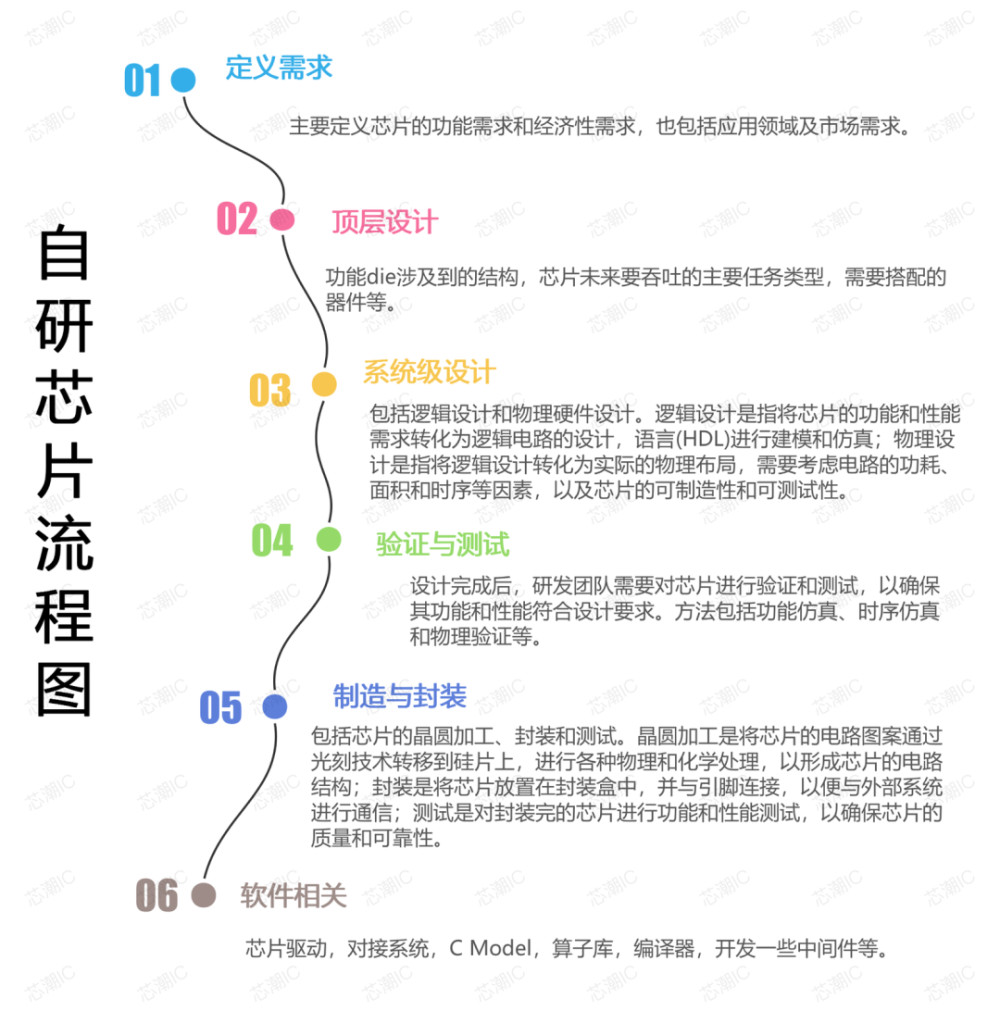
自研芯片流程示意圖
小團隊一般來講能夠獨立完成的設計只有邏輯芯片的前後端和軟件工具鏈本身,但即便如此,很多設計也僅有5%的自研專用電路。
前述知情人士表示,“市場上大家都是自己做1/5,其余的4/5找別人做,這是相當成熟的生態。至於如何獲得這些電路IP,有一些是不良渠道,有一些則是合規的渠道,比如ARM這樣的IP設計廠商授權。”
對於很多團隊來說,其實具備部分電路的自主設計能力,但因爲需要逾越有非常嚴密的知識產權保護的IP,就算做出來也很可能違反了計算機體系結構沒有辦法使用,甚至侵犯了別人的IP,這也是國內廠商自研芯片時碰的第一道坎兒。
還有一部分東西的確是自研團隊設計不了的,比如NOC(Network on Chip,片上網絡)一些非常艱深的結構。
設計只是自研芯片的一個環節,它還包括流片、量產等等,中間可能還會遇到各種各樣的問題,包括流片失敗,量產產能等,但這些都不是自研的終點,它還需要解決一系列的配套問題,包括如何將產業鏈整合落到實處。
在外界看來,一顆專用的邏輯芯片大概500多mm²,通用的GPU可以做到800mm²,包含數百億甚至上千億晶體管,其中一部分功能用於向量計算,可以認爲是一個向量處理器的全部,但要落地到應用場景當中,它還需要存儲、能耗控制、供電、整機工況方面的設計與實現,也需要互聯組網變成更大的集群。
此外,產品的最終目的都是打出差異化,這需要在外設接口和整機上做,也就會出現不同的SKU,而行業通常也是從整機的角度去對比存儲、能耗、坪效。
也就是說,自研芯片除了產業鏈整合、IP的問題,也得考慮做產品SKU,不是設計出一顆邏輯芯片就可以了。
一位不愿透露姓名的資深人士告訴芯潮IC,“很多國內公司不具備產品設計能力,做出芯片之後,要到各地去測試,它的工程師、商務BD每一天都駐扎在浪潮、曙光等大廠的數據中心,期待對方新的服務器主板上能夠去留一個插口給自己,測試成功就批量买一批,不過目前成功的確實非常少。”
量產,是設計、流片以及產品化之外的另一個挑战。小團隊必須考慮,究竟能不能夠預定到產能?
“產量永遠對Fab廠是一個非常關鍵的數字。”前台積電建廠專家吳梓豪表示,廠商要把握自己在哪個環節進入,承諾多大的產量,這是打動Fab最關鍵的點。
一线廠商基本都是在DTCO(設計技術協同優化)階段,就已經預定到了Fab廠的最新產能,目前全球最頂尖的設計團隊,比如ARM每年有大批的人駐扎在台積電,包括許多EDA廠商也是。
DTC決定了下一代處理器在具體節點上的性能指標,比如通過在3nm節點,通過合理的布局設計,能節省多少錢、可以提升多少性能。
“英偉達、蘋果永遠愿意試水最先進的制程,只要台積電出一個最先進的制程,哪怕良率未知,性能的增益未知,即經濟模型還算不出來的時候,他們就已經在預定產能了,與Fab廠進行DTCO協同設計,這是一线廠商拿到產能的根本原因。”吳梓豪說。

台積電 | 圖源台積電官網
如果沒有從一开始做協同設計,Fab廠與Fabless團隊,甲乙雙方就得轉換角色,因爲大家都不太敢用,Fab廠只能一點一點去推銷自己的新制程,先從風險最低的芯片开始。
比如礦機芯片,結構非常簡單,尺寸又特別小,就很適合最初的試水,當年三星3nm芯片的首個客戶就是一家來自中國的礦機設備廠。
吳梓豪說,“Fab廠在這種小客戶訂單上試水成功後,才能再試着量產PC的CPU,手機芯片,最後是AI芯片,一步一步來。”
目前,國內大廠自研芯片至少已投入了數十億美金。如果初創公司想入局,要么本身有足夠的多的早期客戶,或有應用平台去支撐芯片的適配與試錯,要么有足夠的資本或融資能力很強,這兩個條件必須滿足其一。
陳巍告訴芯潮IC,如果是一家沒有低成本人力儲備的商業化公司,不依靠學校或研究所,那在量產之前需要不低於5~10億人民幣的融資;但如果有研究所或其他支持的話,人力成本能減少很多,金額門檻可稍微低一些。
“如果沒有那么多錢,但這家創企的成本控制能力非常強,能充分利用好上下遊協作來降低成本也可以,一切都是爲了保證產品研發的持續進行。”
Fab選擇優先級上,據知情人士透露,最初創企們會選擇去訂購台積電的產能,其次是格芯,但格芯沒有先進工藝,也沒有封裝,再轉而找中芯國際,但中芯國際能預訂的產能都排到後年了。
對於這一情況,投資機構持更長线的視角。
於浩表示,單就國內自研高端芯片來說,短期內面臨流片瓶頸是必然的,長期就看以中芯國際爲代表的先進工藝线打磨和產能擴充的進化速度,主要靠內循環。不過,有高端芯片設計能力的廠商,不妨考慮出海,用外循環帶動內循環,走出去反而海闊天空。
做英偉達的“掘墓人”不容易
03
老客戶自立門戶,受傷的總是英偉達。
這一場全球範圍的自研大潮,一個比一個“炸”。除了谷歌TPU、亞馬遜Graviton這些已臻成熟的自研成果。近日,整個科技圈都被“全球首款Transformer專用AI芯片Sohu”刷屏。

美國芯片創業公司 Etched 推出Transformer專用AI芯片Sohu
這款芯片直接將Transformer架構嵌入芯片內部,在推理性能上遠超GPU和其他通用人工智能芯片,號稱比今年3月才面世的頂尖芯片B200性能高出10倍。據傳,一台配備8塊Sohu芯片的服務器,性能足以媲美160塊H100 GPU的集群,每秒能處理高達50萬的Llama 7B tokens。
“當紅炸子雞”橫空出世,Fab廠及合作商笑开了花。
據悉,該公司已就Sohu芯片的生產與台積電4nm工藝展开直接合作,並且已從頂級供應商處獲得足夠的 HBM 和服務器供應,一些早期客戶已經向該公司預訂了數千萬美元的硬件。網友給Etched起了個諢名——“英偉達的掘墓人”。
但英偉達真會因狼煙四起而“自研”神話破滅嗎?其實不然。
在半導體行業,有一個著名的“牧本周期”——芯片類型有規律地在通用化和定制化之間不斷交替演化——在某一個特定時期內,通用結構賣得最好,爲廣大用戶所歡迎,但到達一定階段後,通用結構在應對特定需求時落後,專用結構會大行其道。
而英偉達正當仁不讓地代表着通用結構時代,這個時代剛好還處在頂峰。
根據富國銀行的統計,英偉達目前在全球數據中心AI加速市場擁有98%的份額,處於絕對的統治地位。這也就是說,全球98%的人群正在使用英偉達的CUDA C去“榨幹”所有GPU的性能,只有剩下那2%-3%的人還在特別堅持用一個不怎么樣的“錘子”,去錘同一個“釘子”。
“現在亞馬遜也好,英特爾也好,自己做的處理器首先經濟上不能滿足一個雲廠商利益的最大化,所以他們一定還會大量使用英偉達芯片,直到有一天英偉達徹底失去優勢,才會走到牧本周期專用化那條路上。”前述知情人士表示。
不過,躺平不符合英偉達的人設,黃仁勳是一個深知“生於憂患死於安樂”的人,一年前在台大的演講,他就談到:“不論是爲了食物而奔跑,或不被他人當作食物而奔跑,你往往無法知道自己正處在哪一種情況,但無論如何,都要保持奔跑。”
這次,面對整個硅谷自研的挑战,英偉達也在出牌。
前述資深人士告訴芯潮IC,“英偉達做的早就不是一個通用GPU了,在它的GPU單元中可以看到大量的Tensor Core來解決矩陣計算,除此之外還能看到Transformer引擎、稀疏化引擎等,無論在硬件結構,還是在硬件算子的更新上,英偉達每年都在把自己推向DSA化的設計趨勢。”
DSA(Domain Specific Architecture)即特定領域架構,是一種針對特定領域定制的可編程處理器架構,能夠優化特定應用程序的性能和性價比。目前,谷歌、特斯拉、OpenAI和Cerebras等都針對特定應用推出了自己的DSA芯片。
據知情人士透露,所有做DSA的廠商都會發現,英偉達即使不修改硬件,通用GPU只更新一個算子,DSA廠商的優勢就完全沒有了。似乎與英偉達一比,自己不但邏輯芯片面積做得不夠大,器件容量和速度做得也不夠大,算力也比不上英偉達,軟件適配性做得也不夠好,這也是所有DSA廠商都面臨的問題——牧本周期原本要走向DSA特定領域架構,走向定制化的,現在又回到了通用處理器的時代。
除了和DSA廠商“照鏡子”,英偉達也向自研伸出了橄欖枝——2024年年初,專門建立了一個新的業務部門,由半導體資深人士Dina McKinney領導,專爲雲計算、5G 電信、遊戲、汽車等領域客戶構建定制芯片。
路透社援引知情人士說法稱,英偉達高管已與亞馬遜、Meta、微軟、谷歌和 OpenAI的代表們會晤,討論爲它們定制芯片的事宜,除了數據中心芯片外,該公司還在爭取電信、汽車和視頻遊戲客戶。
此前,有消息稱任天堂在今年推出的新版任天堂Switch遊戲機,很可能就會搭載英偉達的定制芯片,而英偉達在掌機市場也有很深的沉澱,並且推出過Tegra系列移動芯片,盡管這個芯片系列最後並沒有在移動設備市場佔據一席之地。
在性價比主導的市場裏,要做英偉達的掘墓人還真沒那么容易。之前的掘墓人大多走向了失敗——最終可能會被收購,像英特爾、Google收購了很多創企,但此外的大多數企業甚至等不到收購,直接夭折了。
也許對於初創企業來說,換一個角度更容易成功。
“比如不要執迷於AI處理器本身,與其花很多的時間去兌現一個DSA的理想,不如考慮一下系統級方案,比如可以做周邊外設來爲 AI的處理器提供服務,做專業存儲、專業傳感器也可以達到同樣的目的。”前述知情人士說。
2019年,英偉達宣布以69億美金的價格收購Mellanox,這個估值非常之高,英偉達幾乎透支掉自己的整個現金流。
這家公司既不研發端口,也不研發光伏模塊,更不研發交換機本身,它只做了一款產品——交換機底層和通訊底層的那一部分高速互聯的PHY“InfiniBand”。對於當時亟需突破服務器互連限制的英偉達而言,這是一個非常核心的外設的需求。當時無論NVLink做得多好,始終被鎖死在單機附近。但InfiniBand可以讓交換機突破服務器間的互聯瓶頸,把所有的GPU互聯成一個大集群。
放眼當下,國內正火熱攢局,芯片自研的子彈還得再飛一會兒。陳巍認爲,攢局不是一件壞事,但要攢一個高端局,以免錯失產業發展的關鍵窗口期。
未盡研究創始人周健工進一步展开這一觀點,他認爲,今後的應用對於AI芯片的專業、定制、小型化需求,會超出對於前沿基礎大模型的需求。以更低的成本訓練出开源的、較小型的模型,或者對大模型進行微調和蒸餾等,以及推理,都爲自研芯片帶來了廣闊的空間。而且在新技術的快速變動和未成熟期,圍繞上述應用會帶來大量的自研機會。
“不要去做終結英偉達的事,而是去做英偉達之外更多的事。”

免責聲明:
1、本文內容爲芯潮IC原創,內容及觀點僅供參考,不構成任何投資建議;文中所引用信息均來自市場公开資料,我司對所引信息的准確性和完整性不作任何保證。
2、本文未經許可,不得翻版、復制、刊登、發表或引用。如需轉載,請聯系我們。
原文標題 : 70000億虛晃一槍,硅谷的“刀”刺向英偉達
標題:70000億虛晃一槍,硅谷的“刀”刺向英偉達
地址:https://www.utechfun.com/post/404968.html