作者:一號
編輯:美美
國產AI大模型距離GPT,或許只差半年。
國產大模型正迅速崛起成爲全球AI領域不可忽視的力量。隨着深度學習技術的不斷突破,國產大模型在自然語言處理、圖像識別等多個領域展現出驚人的潛力,它們不僅推動了人工智能技術的飛速發展,也在各行各業中發揮着越來越重要的作用。
然而,隨着技術的快速迭代,國產大模型也面臨着前所未有的商業化挑战。
技術革新與國際競爭
在全球人工智能的競技場上,國產大模型正以驚人的速度迎頭趕上,逐漸縮小與行業領頭羊OpenAI的技術差距。據最新資料顯示,這一差距已顯著縮短至半年左右,標志着國產AI技術的一次飛躍。
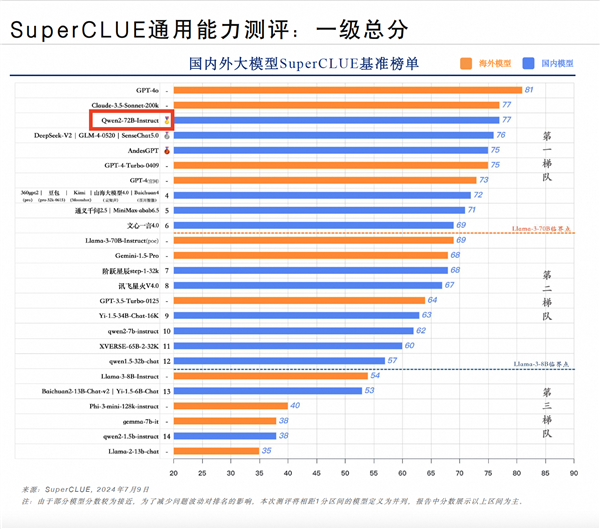
以阿裏的Qwen系列爲例,其最新开源的Qwen2-72B指令微調版本,在國際开源模型排行榜上一舉奪魁,超越了衆多國際知名模型,顯示了國產大模型在技術精度上的卓越表現。華爲的盤古大模型5.0,以其對物理世界多模態數據的深刻理解,已在超過30個行業、400多個場景中得到應用,證明了國產大模型在行業落地方面的強大實力。科大訊飛的星火大模型V4.0,不僅在中英文12項大模型主流測試集中8個測試排名第一,更在文本生成、語言理解等多個維度超越了國際先進水平。
值得一提的是,國產大模型在多模態能力上的發展。騰訊的混元大模型,憑借其Di-T架構,在全球多模態大模型領域中佔據了先發優勢。而階躍星辰的1T-MoE多模態大模型,更是在圖像生成和多模態感知能力上展現出業界領先水平。這些進步不僅豐富了AI技術的應用場景,也爲國產大模型在全球競爭中贏得了獨特的優勢。
开源與閉源雙軌發展
开源與閉源模型的雙軌發展策略,爲國產大模型的技術創新和行業應用提供了雙重動力。开源模型,以其开放共享的特性,加速了AI技術的迭代和創新。例如,阿裏的Qwen系列模型,通過开源,不僅吸引了全球开發者的廣泛關注和貢獻,也促進了技術的快速演進和優化。开源模型的另一個優勢在於其靈活性,能夠根據不同行業和場景的需求,進行定制化調整和優化。
閉源模型則在特定行業應用中展現出定制化的優勢。以華爲盤古大模型爲例,其閉源特性使得模型能夠針對特定行業進行深度定制,滿足行業客戶的個性化需求。閉源模型的另一個優勢在於安全性和專業性,能夠在保護知識產權的同時,提供更加專業和高效的服務。
通過具體數據和實例,我們可以看到不同模型在性能上的表現和市場接受度。例如,科大訊飛的星火大模型V4.0,在國內外多項大模型主流測試中表現優異,其在文本生成、語言理解等方面的能力超越了國際大模型。而在市場接受度方面,百度的文心一言用戶規模達到3億,日調用量超過5億,顯示了其在市場中的廣泛認可和應用。這種开源閉源雙軌發展的策略,不僅豐富了國產大模型的生態,也爲AI技術的未來發展提供了更多可能性。
商業化挑战與市場潛力
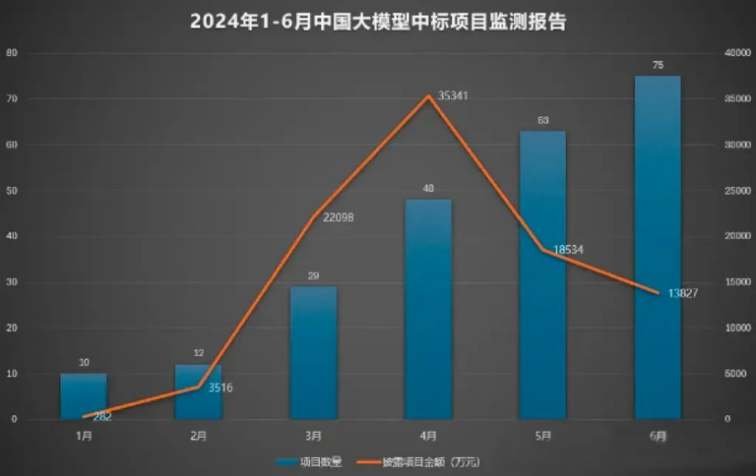
在國產大模型的技術進步背後,商業化之路並非一帆風順。盡管國產大模型在性能上取得了顯著成就,但商業化的現狀和挑战同樣不容忽視。6月份大模型相關中標項目75個,披露的中標金額達到了1.38億元,這一數字雖然可觀,但與巨大的研發投入相比,仍顯不足。
以百度和科大訊飛爲例,2023年的研發費用分別爲242億元和34.81億元,其中相當一部分投向了大模型的研發。這種投入與產出之間的差距,凸顯了國產大模型在商業化過程中的困境。
價格战的爆發進一步加劇了這一挑战。隨着字節跳動等廠商大幅降低Token價格,大模型的價格進入了所謂的“釐時代”,這無疑對整個行業的盈利模式和可持續發展構成了壓力。價格战可能會短期內吸引用戶,但長期來看,如何平衡成本和收益,尋找到可持續的商業模式,是國產大模型廠商需要深思的問題。
然而,挑战中也蕴含着機遇。國產大模型的用戶接受度和市場潛力不容忽視。以百度的文心一言爲例,其用戶規模達到3億,日調用量超過5億,這一龐大的用戶基礎爲國產大模型提供了廣闊的市場空間。通過進一步優化用戶體驗,提升產品的易用性和實用性,國產大模型完全有可能在市場中佔據更大的份額。
國產大模型在商業化的道路上,還需要在技術創新的基礎上,更加注重市場需求和用戶體驗,通過不斷的探索和調整,尋找到適合自己的可持續發展之路。
原文標題 : 新火種AI|國產大模型的技術突破與商業化探索
標題:國產大模型的技術突破與商業化探索
地址:https://www.utechfun.com/post/399047.html