
本月發表的《》新論文,研究人員提出 MatMul-free 語言模型(MatMul-Free LM),該模型性能與最先進的 Transformer 相當,同時推論過程需要的記憶體用量更少。
矩陣乘法(Matrix Multiplication,MatMul)是大多數神經網路運算的基本操作,歸因於 GPU 針對 MatMul 操作進行一系列效能改進。儘管 MatMul 在深度學習發揮關鍵作用,但它也是決定運算成本的一大關鍵,通常訓練和推論階段消耗大量執行時間和記憶體存取,帶來昂貴的運算成本。
來自加州大學聖克魯茲分校、蘇州大學、加州大學戴維斯分校及 LuxiTech 組成的研究團隊,透過論文介紹可擴展的 MatMul-Free LM。他們研究表明即使達到十億等級參數規模,也能完全消除大型語言模型(Large Language Models,LLM)的 MatMul 操作,同時模型保有穩健性能。
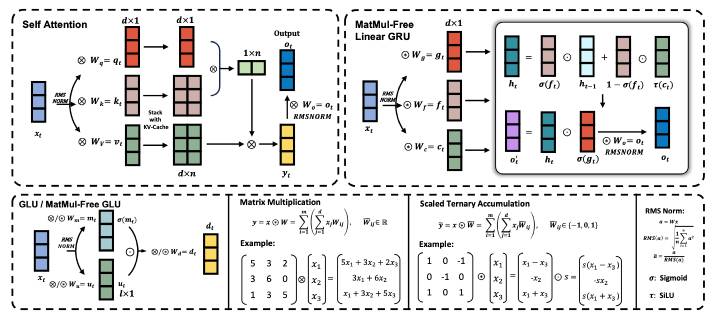
MatMul-free LM 透過密集層和元素級阿達瑪乘積採用加法運算來達成類似自注意力機制的功能。具體來說,三元權重用於消除密集層中的 MatMul,類似二元神經網路(binary neural network,BNN)。為了消除 MatMul 的自注意力機制,研究人員使閘門循環單元(Gated Recurrent Unit,GRU)最佳化,完全依賴元素乘積。這種創新模型可與最先進的 Transformer 競爭,同時消除所有 MatMul 操作。
▲ MatMul-free LM 概述。
研究團隊的架構視角受到 Metaformer 啟發,Metaformer 將 Transformer 概念化為由 token mixer 和 channel mixer 組成。
為了量化其輕量級模型的硬體優勢,研究人員提供優化的 GPU 實作以及 FPGA 加速器,這種方法可將記憶體使用量減少多達 61%。透過推論過程利用最佳化的內核,當與未優化的模型相比,MatMul-free LM 的記憶體用量減少 10 倍以上。
為了徹底評估他們提出架構的效率,研究團隊在 FPGA 開發了一種客製化硬體解決方案,利用 GPU 功能以外的輕量級操作,成功在功耗 13W 情況下處理 10 億參數規模的模型,以超出人類可讀的吞吐量,使 LLM 接近大腦般的效率。
(首圖來源:shutterstock)

標題:新研究從 LLM 消除 MatMul 操作,模型記憶體用量減十倍
地址:https://www.utechfun.com/post/384575.html