在基於GPT-3.5的ChatGPT問世之前,OpenAI作爲深度學習領域並不大爲人所看好的技術分支玩家,已經在GPT這個賽道默默耕耘了七八年的時間。
好幾年的時間裏,GPT始終沒有跨越從“不能用”到“能用”的奇點。轉折點發生在2020年6月份發布的GPT-3,從這一版本开始,GPT可以做比較出色的文本生成工作了,初步具備了“智慧湧現”能力。
再後來,OpenAI在GPT-3.5裏加入了個人機交互界面,做了聊天機器人ChatGPT,迅速席卷全球,在短短的兩個月的時間裏,用戶數量迅速突破1億大關。
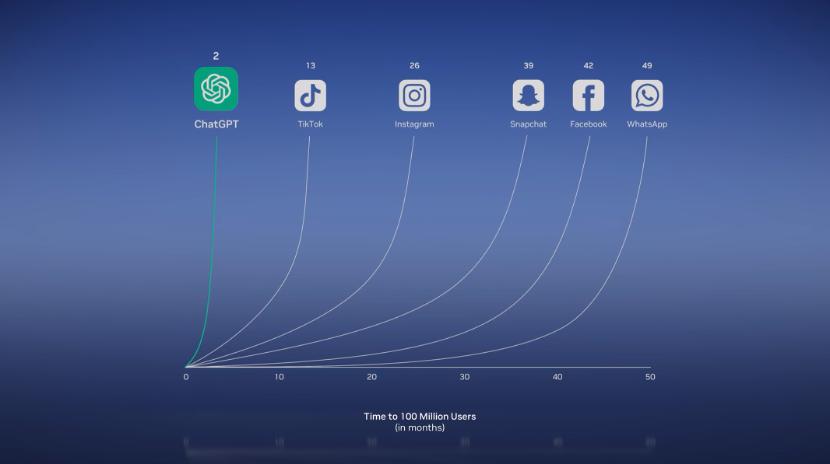
圖片來源:英偉達
海外的谷歌、Meta、特斯拉,國內的百度、華爲、阿裏、字節這些互聯網巨頭紛紛加碼在GPT大模型上的投入,再後來,本土電動車企形形色色的GPT也陸續問世了。
自2023年第四季度开始,問界M9上的盤古大模型、理想OTA5.0裏的Mind GPT,蔚來汽車上的NOMI GPT、小鵬XOS天璣系統裏的XGPT陸續上車,不僅幫你寫詩,還能幫你做事。
那么,這些車載GPT是如何橫空出世的,它們又將爲汽車上帶來何種變化呢?
一、大模型上車:开源 VS 閉源
早期,沒有在大模型方面布局的本土車企是借助國內外开源的基礎大模型自研GPT,這應該也算是業內公开的祕密。原因無他,真正自研大模型實在太消耗資源了。
大模型的賽道非常卷。爲了縮短訓練時間,且提高訓練效率,OpenAI、谷歌、Meta這些巨頭的基礎大模型都是投入大幾千張甚至幾萬張A100、H100顯卡訓練出來的。
1萬張A100大約對應3.12E的訓練算力。公开信息顯示,國內頭部車企裏,華爲用在汽車業務上的訓練算力3.5E,百度爲2.2E,蔚小理的算力規模都在1E左右。
在一次訪談中,馬斯克透露過xAI的Grok(據說要上特斯拉的車)訓練投入了8000張A100。從GPU小時來算,且不說這些閉源的參數量奔着萬億級別而去的大模型,即便那些开源大模型,其消耗的GPU資源都是不可承擔之重。
據悉,Meta开源的LLaMA-2-70B的大模型,使用了2000個英偉達A100訓練,耗費了172萬個GPU小時;地表最強开源大模型Falcon-180B,使用了4096個A100 GPU,耗費了約700萬 GPU小時進行訓練。
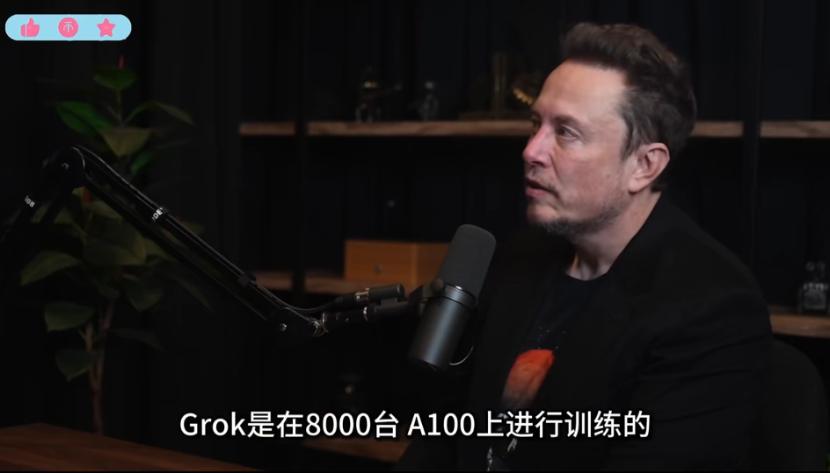
來源:馬斯克訪談
無論從什么角度,不以大模型爲主業的本土車企,都不可能爲這個賽道投入這么巨大的資源,而且,幾萬張A100/H100(百億美金)遠不是這些現在基本上還無法盈利、只能依靠資本市場輸血的車企所能承擔的了的。
所以,採用开源大模型自研可滿足車用場景的GPT,成了本土車企的捷徑,也幾乎是唯一可行的路徑。
只有少數巨頭強勢賦能的車企,才會採用了自研基礎大模型的方案。比如,華爲系的問界、智界和百度系的極越,真要算起來,華爲的盤古大模型和百度的文心一言問世的時間也不短了。
稍許遺憾的是,這兩個大模型至今沒有產生破圈效應,GPT上車的時間也並沒有比蔚小理早很多。
這背後有一系列復雜的原因。
一方面,正如華爲高管在2023年的華爲开發者大會上所說的那樣,“我們的大模型不做詩,只做事”,因爲一直做着to B的生意,沒有to C,所以沒有被大衆所熟知。
另一方面,盤古大模型和文心一言之前基礎能力不足,基礎能力的不足來自於參數規模比較小、訓練數據和訓練時間不足。
必須承認,直到OpenAI的ChatGPT問世之後,整個行業及業界專家才真正接受了比例定律Scaling Law,建立了可以通過擴大模型規模、增加訓練數據量、延長訓練時間實現模型性能持續提升的“信仰”。
信仰不足、意見不一是之前不夠大的大模型基礎能力不足,從而沒有產生破圈效應的重要原因。
即便認可了比例定律的第一性原理,要從千億參數邁進到萬億參數,也需要對模型設計做大量的科研工作,才能解決參數數量級提升引發的梯度爆炸等一系列問題。
無論如何,雖然同是率先將大模型技術搬上汽車的第一陣營,華爲(問界和智界)/百度(極越)的大模型上車路徑和蔚小理還是有着明顯的區別,其本質的區別就在於前兩家的基礎大模型來自自力更生,而新勢力的基礎大模型很大可能來自於業界的开源方案。
二、 專心做訓練也是一種自研
除了參數量達到1800億的Falcon-180B(去年9月份开源),开源基礎大模型的參數一般都在幾百億級別。這是巨頭的遊戲。
扎克伯格的Meta是开源大模型的主要貢獻者,它們开源的LLaMA-70B的參數在700億左右。
另一玩家是谷歌,也許是意識到了無法打敗OpenAI,帶着攪局或者不想讓OpenAI壟斷基礎大模型市場的心思,谷歌正加快开源的動作,它最近开源了兩個大模型——Gemma 2B和7B,可分別在端側和雲端部署。
根據這些巨頭宣布开源大模型的時間做一個推論,蔚小理等本土車企們用的开源大模型的參數量大概在千億左右。
這些开源基礎大模型提供的不只是模型結構的細節,更重要的是,它們經過了萬億Token的訓練,模型裏的權重參數已經是完成度很高的可用狀態。對於基於开源大模型做訓練的車企而言,要做的工作是尋找或建立能夠適用於車用場景的數據集,再進行微調訓練。
在开源基礎大模型上面做定制,從而訓練出微調大模型的過程,就好比學霸上完了高中,並將他腦袋裏成熟的神經網絡復刻到你的腦袋裏,然後你再去上大學選個專業,在這個專業領域單兵突進,繼續深造。
比如,現在有專門面向醫療行業、財稅行業的大模型,同樣是在基礎大模型之訓練出來的。
再比如,一小撮程序員訓練出來志在消滅大多數程序員的軟件开發者大模型——GitHub Copilot,和最近讓碼農們聞風喪膽的Davin。

圖片來源:GitHub
和華爲系、百度系相比,蔚小理的GPT在參數量上也許小了一個數量級,但這並不意味着NOMI GPT們在車載場景下的專項能力一定會低於華爲/百度系車企,幾百億參數的大模型足以將文本形式的所有人類知識壓縮進去。
再者,加大訓練數據規模同樣可以提升大模型的表現,可以認爲,數據集的作用並不亞於模型參數。
在2023年的微軟Build大會上,Andrej Karpathy大神在闡釋參數量和Token數量對大模型性能的影響時,對2020年問世的GPT-3和2023年問世的LLaMA-65B做過對比。

圖片來源:微軟Build大會
2020年發布的GPT-3的參數量爲1750億,訓練Token數量爲3000億(隨着時間的增加,會繼續追加訓練數據規模),LLaMA-65B的參數量爲650億,用於訓練的Token數量介於1萬億-1.4萬億之間。
GPT-3參數量更大,表現卻不及LLaMA-65B,背後的主要原因就在於LLaMA進行了更加充分的訓練。
在訓練上,其他玩家也可以站在巨人的肩膀上,向訓練完備、表現出色的大模型投喂更多的訓練語料。而且,在一定程度上,語料庫也是現成的。
過去幾十年,除了尋求如何設計更加可泛化的推理機制,設計可通向人類通用能力和常識的神經網絡和大模型,人工智能研究人員還把大量的精力放在了孜孜不倦地構建包含大量常識語料庫的知識庫上面。
比如,用於訓練和評估用於檢測機器釋義文本模型的Identifying Machine-Paraphrased Plagiarism、通用文本分類數據集Wikipedia、Reddit 和 Stack Exchange、QA 數據集Quoref 、 基於文本的問答數據集TriviaQA等等。
這背後有大量的工作要做。因爲,和基礎大模型可以通過無監督、無需標注的數據進行訓練不同,在基礎大模型之上進行微調訓練時,需要通過有監督和基於人類反饋的強化學習形式,在標注過的高質量數據集上進行訓練,通過對話形式進行專項能力訓練,工作量也不容小覷。

圖片來源: Andrej Karpathy
三、大模型上車的部署路徑
大模型自有其訓練機制,在車端的部署路徑也日益清晰。
按照難易程度和各個頭部車企的大模型上車實踐,可以做出一個比較清晰合理的判斷:大模型將全面改造智能座艙,並有望在幾年後真正部署在智能駕駛方案中。
智能座艙是人機交互集中發生的地方,人和機器或智能體的交互主要體現在機器對人類意圖的理解、記憶和推理三個方面,大模型天然具備超強的理解和生成能力,並可以通過提高上下文的長度增強記憶能力,再加上智能座艙的容錯能力特別強,所以,從技術和應用場景的契合度上,大模型和智能座艙可謂天作之合,也必然大幅度提升人機交互體驗。
理想汽車在MEGA發布會上,介紹了Mind GPT的四大落地場景:百科老師、用車助手、出行助手和娛樂助手,基本總結了大模型技術當前在智能座艙領域的幾個用武之地。

圖片來源:理想汽車
自動駕駛領域也是大模型可以大顯身手的地方。
大模型對自動駕駛的意義目前主要體現在加快算法开發和模型迭代速度上,比如毫末智行發布的大模型DriveGPT雪湖·海若可以在“訓練階段”進行數據的篩選、挖掘、自動標注,在“仿真階段”生成測試場景。
不過,由於自動駕駛對安全性的要求特別高,對實時性的要求也極爲嚴苛,要在車端部署大模型形式的自動駕駛方案還需要很長一段時間。
業界還在探索在“开發階段”利用大模型(生成式的多模態大視覺語言模型),比如理想汽車最近和清華聯手开發的DriveVLM,部署在英偉達Orin X上的話,推理能力需要0.3秒。
0.3秒是個什么概念?就是如果你以20米每秒(對應72公裏每小時)的速度开車,0.3秒可以跑出去6米。。。這還僅僅是考慮到了實時性這個單一因素,還沒有涉及到大模型的幻覺對安全性的威脅。
所以,大模型改造智能座艙可謂指日可待,但用在自動駕駛方面,只能說任重道遠,未來可期。
總體上,面對激烈的市場競爭,本土車企不能放過任何一個風口,大模型這種超級大的風口絕對不能錯過,其他車企今年會陸續傳來大模型上車的消息,這一點基本上毋庸置疑。
接下來這一年,大家可能需要做好迎接各種車載大模型炫技的測評視頻滿天飛的准備,不過,也不用太理會他們說的怎么天花亂墜,大模型從“能用”到真正“好用”,再到產生破圈效應,諸位且耐心等一等吧。
原文標題 : 車載GPT爆紅前夜:一場巨頭競逐的遊戲
標題:車載GPT爆紅前夜:一場巨頭競逐的遊戲
地址:https://www.utechfun.com/post/371246.html