從 ChatGPT(GPT-3.5)發布至今的一年多,大語言模型的迭代速度之快、進步幅度之大,時刻刷新着我們的認知。最近一段時間,各家更是密集發布了新版的大模型,都在追趕和超越最新領先的大模型,甚至逼得 OpenAI 進一步取消了 GPT-4 的限制。
現在阿裏雲最新的通義千問 2.5 版本也來了,不僅在中文語境下追上了 GPT-4 Turbo,更讓人期待的是:在开源和免費的發展策略下,通義千問 2.5 會不會成爲大模型落地的分水嶺,加速 AI 應用的全面爆發?
這一點還需要我們拭目以待,但至少,通義千問的這一輪升級中再次證明自己的能力和潛力。
通義千問全面升級,中文性能追平 GPT-4 Turbo
5 月 9 日,阿裏雲正式發布通義千問 2.5,這是其旗下的通義大模型系列的最新版本。與此同時,阿裏雲還开源通義千問 1100 億參數模型。
按照阿裏雲方面的說法,得益於全方位的能力提升,在中文語境下,通義千問 2.5 的文本理解、文本生成、知識問答及生活建議、闲聊及對話、安全風險等多項能力趕超 GPT-4。

圖/阿裏
而據權威基准測評 OpenCompass 的結果顯示,通義千問 2.5 的得分也追平了 GPT-4 Turbo,是第一個做到的國產大模型。
在 LMSYS 最新的大模型對战排行榜中,通義千問(Qwen-Max)暫時位居總榜第 10,中文場景下與 GPT-4 Turbo 並列第 2,僅僅略遜於排在第一的 Claude 3 Opus 和 GPT-4(1106)。
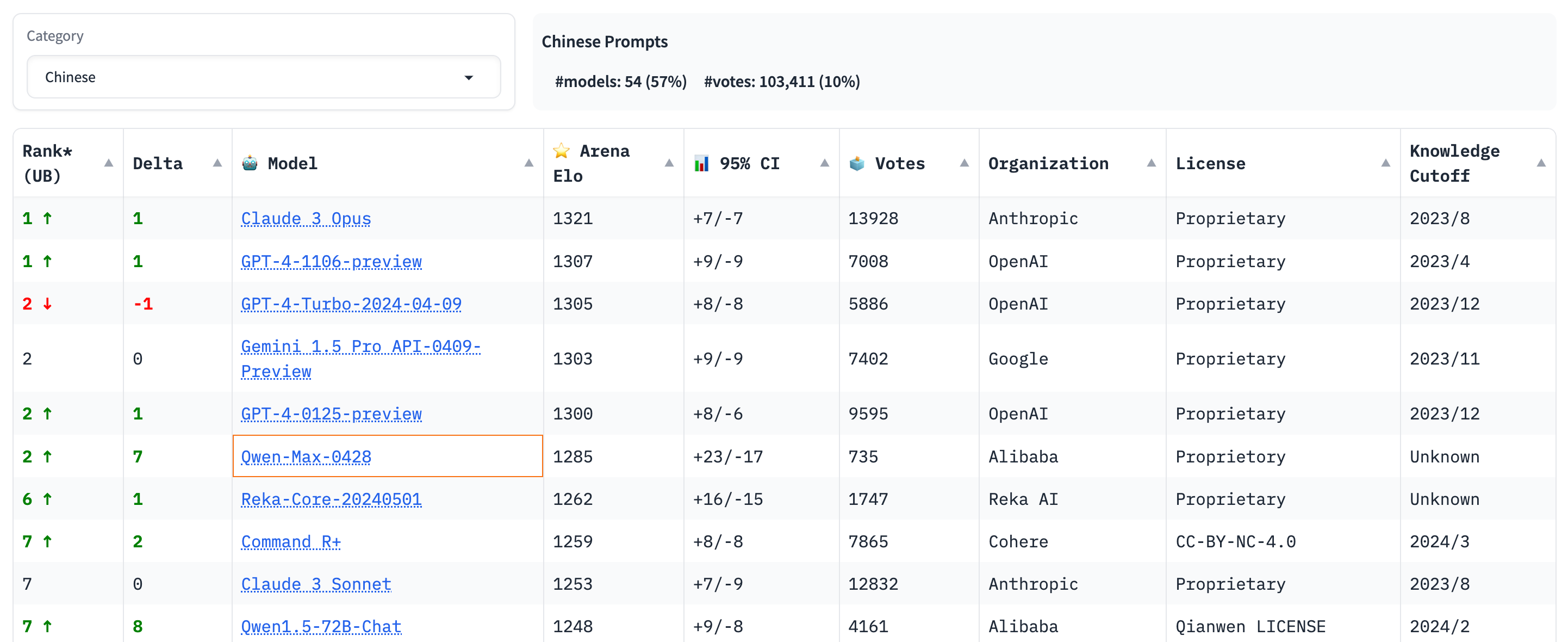
圖/ LMSYS
當然,跑分和排行榜很難完全說明大模型的實際性能表現,更遑論最終落到實處的用戶體驗。
根據介紹,通義千問 2.5 採用了阿裏雲自研的「問天」架構,並通過大量數據和算法的訓練,使得模型的核心性能得到了大幅提升。相比 2.1 版本,2.5 版本通義千問的理解能力、邏輯推理、指令遵循、代碼能力分別提升 9%、16%、19%、10%。
簡單來說,你可以認爲通義千問 2.5 能夠更准確地理解自然語言的語義,並識別出其中的細微差別;也能進行更復雜的邏輯推理,並解決更具挑战性的問題等。此外,通義千問版本升級後還新增了文檔處理、音視頻理解、智能編碼等多種能力。
在文檔處理上,通義千問 2.5 支持單次最長 1000 萬字、100 個文檔,覆蓋 PDF、Word、Excel,甚至 Markdown 和 EPUB 等多種文件格式。同時不只是正文內容,還可以解析標題、段落、圖表等多種數據格式。
圖/通義千問
另外在音視頻理解上,通義千問 2.5 也支持了實時語音識別、說話人分離等能力,能夠提取全文摘要、總結發言、提取關鍵詞等,且支持最多同時上傳處理 50 個音視頻文件。
這些升級或許看上去沒有核心性能的提升來得「性感」,但從實際使用的角度,不管是能一次塞給大模型更大、更多、更多格式的文檔,還是音視頻的多種能力,其實都在大幅擴展大模型的真實使用場景。
從這個角度來看,通義千問 2.5 的意義就遠不只是在性能上追平 GPT-4 Turbo。
另一方面,AI 算力成本的高昂已經廣爲人知,不管是海外的 ChatGPT Plus(GPT-4)、Gemini Advanced、Claude Pro,還是國內的文心一言會員(文心一言 4.0)、WPS AI 等服務,都有不低的收費。
而面向 C 端用戶,通義千問主打一個全功能「免費」。同時通義千問 APP 還升級爲「通義 APP」,集成文生圖、智能編碼、文檔解析、音視頻理解、視覺生成等全棧能力,想成爲用戶的「全能 AI 助手」。
不難理解,阿裏還是通過免費迅速擴大 C 端用戶規模。但在現階段,B 端用戶可能更爲關鍵。
大模型生態落地,开源路线加速
「從 2022 年 9 月發布通義系列模型以來,如今我們的 API 日調用量已經過億。」5 月 9 日,阿裏雲 CTO 周靖人在總結通義千問過去一年時指出。
不僅如此,阿裏雲還透露通義系列大模型已經服務包括新浪微博、小米、中國一汽在內的 9 萬家企業用戶。發布活動上,阿裏雲還邀請微博和小米分享了他們對於通義千問的落地應用。
其中微博作爲最早的用戶,就基於通義千問打造了出圈的官方評論機器人 「評論羅伯特」。小米的小愛同學同樣也是基於通義千問,強化了在圖片生成、圖片理解等方面的多模態 AI 生成能力,包括在小米汽車、手機、音箱等硬件上。
事實上,上個月聯想發布了內嵌個人智能體的「真 AI PC」,其背後也是通義系列大模型。

圖/聯想
开源,毋庸置疑是阿裏在大模型生態上發展迅猛的關鍵因素之一。「大到整個產業落地 AI,小到每個企業开發應用,开源技術都至關重要,這一點在全球範圍內已經被多次證明,」周靖人在財新的採訪中說道。
去年 8 月,阿裏宣布通義千問加入开源生態,隨着沿着「全模態、全尺寸」的开源路线陸續推出十多款模型,參數規模橫跨 5 億到 1100 億,並且迅速成爲开源大模型社區最受歡迎的开源大模型之一。
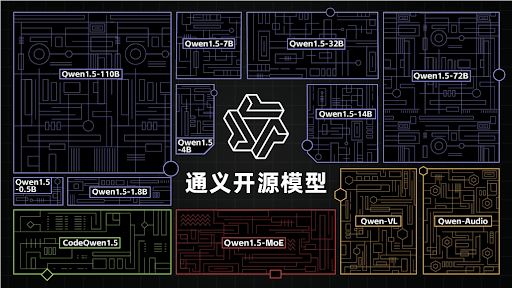
圖/阿裏
其中,1.8B、4B、7B、14B 等小尺寸的通義千問,可以直接在手機、PC 等設備端側部署運行;72B、110B 等大尺寸模型則更多運行在服務器和數據中心,支持更大規模、更專業的 AI 應用。
而隨着通義千問 2.5 的發布,其落地應用還有望得到進一步加速。在开源大模型中,通義千問擁有全尺寸的參數規模,還有目前最強的性能,开發者自然會更傾向基於通義千問的大模型生態進行开發。
更何況,即使相比最領先的閉源大模型,通義千問的差異也拉得很小了。
寫在最後
「我們仍處於 AI 發展的初期階段」,谷歌 CEO 桑達爾·皮查伊在最近一次採訪中說道。
過去一年多,AI 世界幾乎是一天一變,頭部廠商的大模型之爭也愈演愈烈,實質也帶動了整個生態的前進。事實上,今天打开手機,不提系統自帶的 AI 功能,已經有大量的應用都引入了生成式 AI,還在湧現大量的生成式 AI 原生應用。
不過還是不夠。所有人都明白,面向普通用戶的 AI 應用還沒真正迎來爆發時刻,通義千問當然也不可能直接做到,但作爲开源大模型,通義千問確實是最有希望推動 AI 應用真正爆發起來的大模型之一。
來源:雷科技
原文標題 : 最強中文大模型,通義千問2.5追上GPT-4了?
標題:最強中文大模型,通義千問2.5追上GPT-4了?
地址:https://www.utechfun.com/post/369582.html