
奇偶派(jioupai)原創
作者 |光塵、葉子
編輯 |釗
圖源:圖蟲創意
2023年是大模型風潮大起的一年,目前市面上,文心一言、訊飛星火、通義千問等諸多國產大模型已經开放內測許久,這些大模型的技術能力以及由此帶來的用戶體驗感均有所不同。國內國外百模大战之下,哪個大模型更強大,在各方面能力表現如何引人好奇。
帶着這樣的好奇,我們對包括ChatGPT、文心一言、通義千問以及訊飛星火四大國內外主流大模型進行一次綜合橫評,看看誰的表現更好。測評結果由1、2、3、4作爲排名,最終綜合排名相加越低,表示該大模型表現越好。
希望這次測評能給大家帶來一些有價值的參考與結論,廢話不多說,下面我們一起來看看測評。
1
多模態能力
多模態能力指的是處理和理解來自不同模態的信息的能力,例如圖像、文本、音頻和視頻等。它涉及到信息融合、交互式體驗、數據分析、機器學習發展等多方面,我們對其中最重要的部分語音交互能力以及幾個大模型由文字生成圖片、視頻、音頻的能力展开了測試。
①語音交互能力:
語音交互能力是指系統能夠理解和響應語音指令,它是多模態交互中的一個重要組成部分。
我們以一人在春運回家路上遇到的困難,需要得到幫助作爲場景,和幾個大模型展开了對話。
1)文心一言:

文心一言只能一條條語音進行交流,無法實時通話。
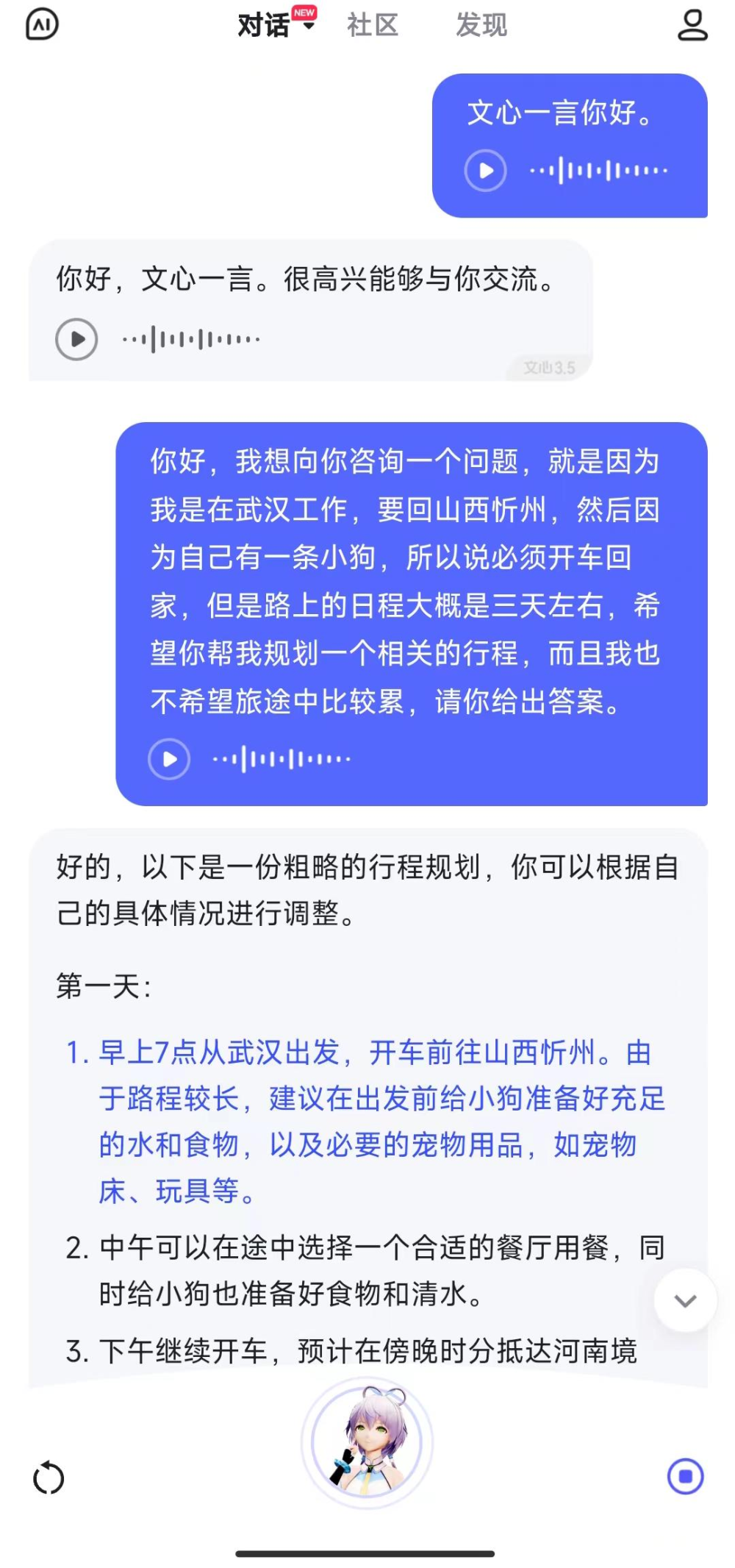
不過給出的解決方案還是比較具體和詳細的。
2)通義千問:
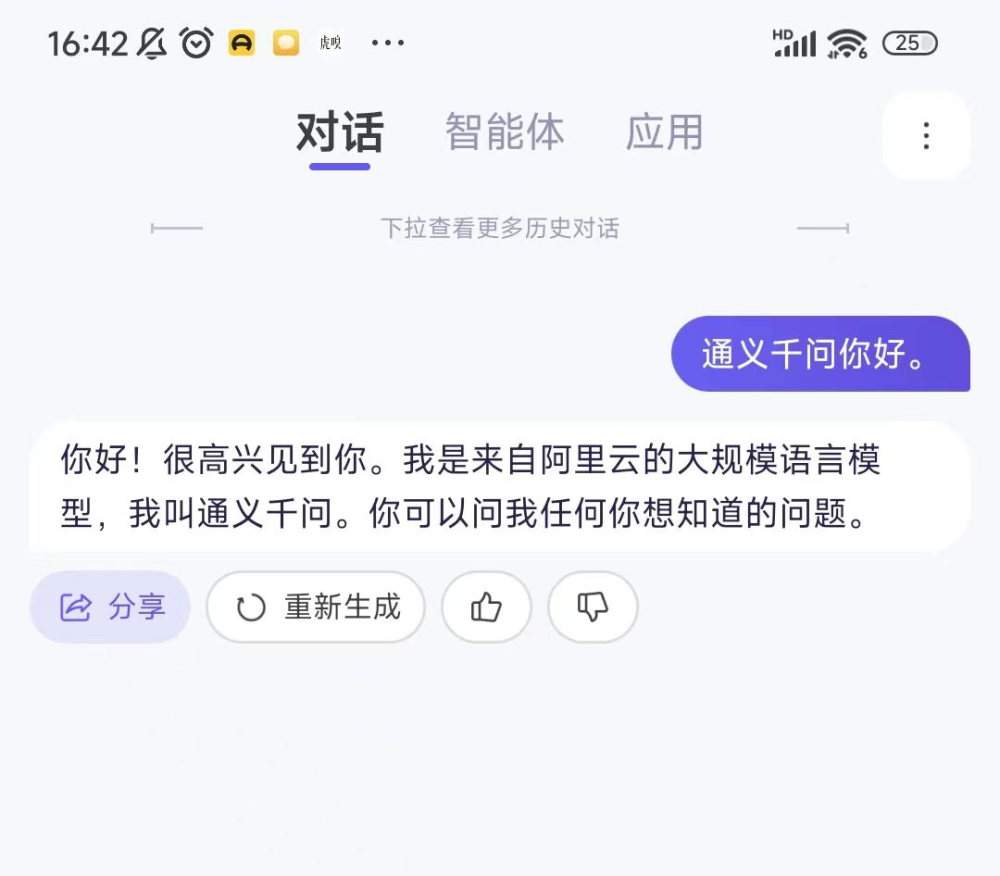
通義千問則是只能在輸入時將語音轉成文字,而在輸出時只有文字的形式。
3)GPT:
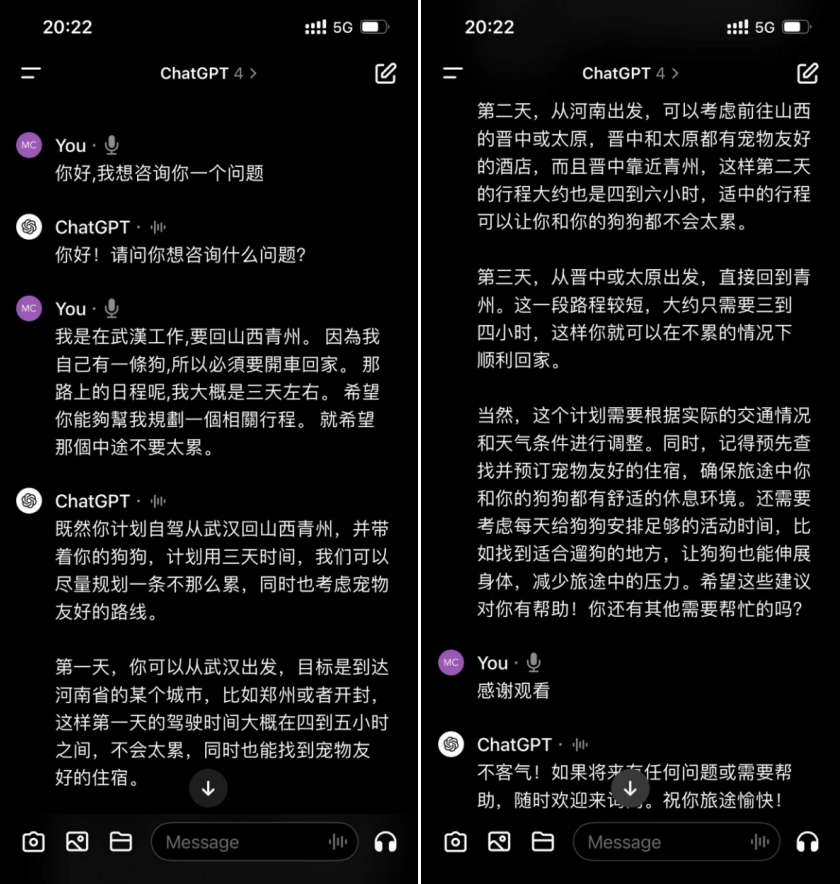
作爲對比,我們也測試了ChatGPT面對相同問題的反應,回答如上,可以看到,GPT給出的解決方案也很細致周到,且包含的問候語很多,聲音擬人度較高。但也要吐槽下,由於網絡問題需要等待很久,且容易被打斷,對國人很不友好。
4)訊飛星火:

可以看到,星火的全語音交互能力並不體現在一條條語音中,而是由“實時通話”的形式展現出來,通過向其提問,星火流利、順暢且迅速、准確地給出了自己的解決方案。
令人眼前一亮的是,回答問題時,星火V3.5也會隨時帶着“嗯……”、“額……”等語氣詞,自然且不顯突兀,不止如此,星火V3.5還會時而說出“就是”、“這個”等口語化的輔助詞,即便對比ChatGPT的“Ember”、“Juniper”,在擬人度和真實度方面也幾無挑剔之處。
這也對比出星火的難能可貴,即星火V3.5在回答問題時,能夠體現出高情商和同理心,這使得它不僅僅是一個智能助手,更像是一個真正理解用戶需求的朋友。
進一步給出更多條件後,星火的回答也更加細致,且其支持語音互動中的文字轉寫。
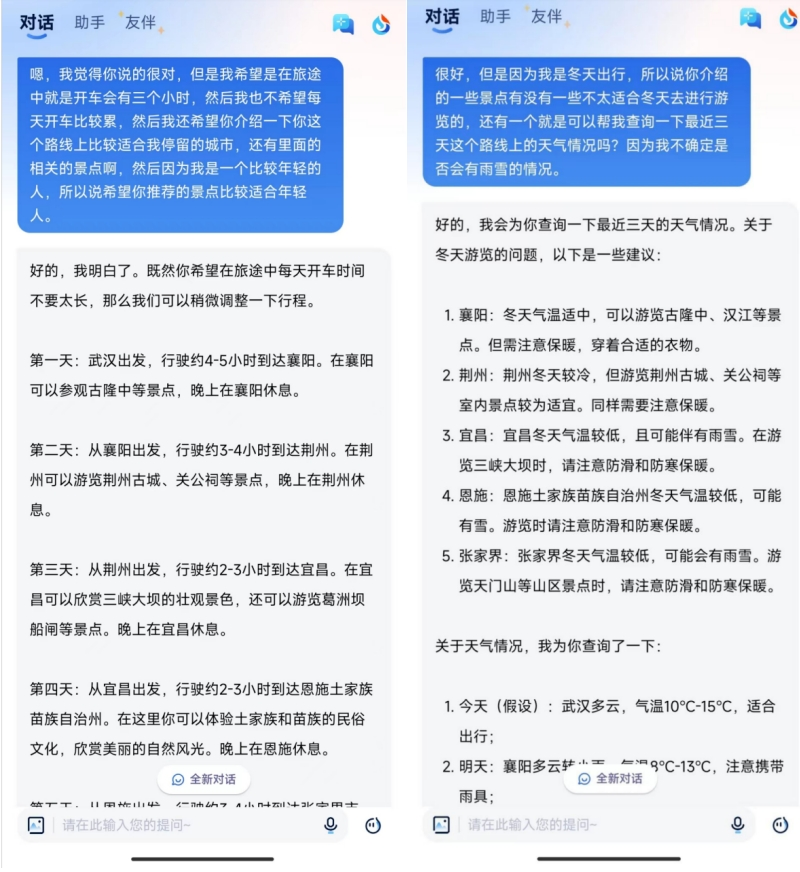
此外,該“通話界面”還有打斷和暫停功能,暫停後也可恢復提問,且可隨時切換到文字模式,看到通話全程的文字版。
而在另一個對話中,對於問題,星火V3.5的回答表現出的關心和體貼,讓人感到被理解和支持,體現了高情商和高同理心。
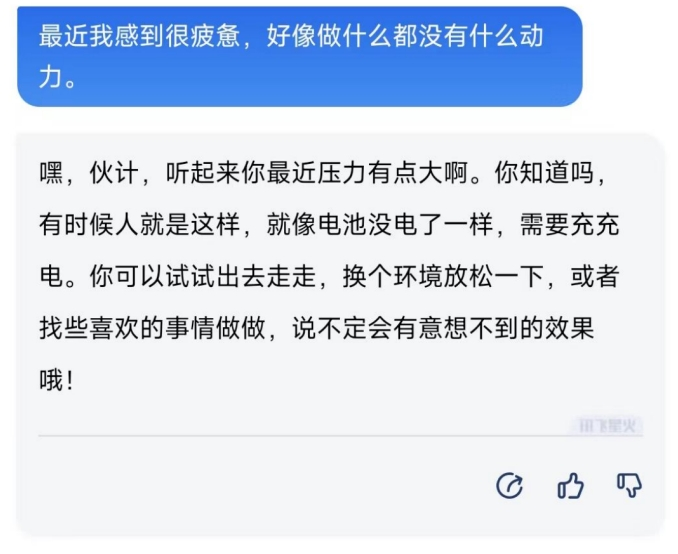
而文心一言和通義千問都只支持一條條語音,而不支持“實時通話”的模式,這一點曾經是ChatGPT的最大賣點之一,而目前在國內廠商中訊飛星火的全語音交互能力可以說是迎頭趕上了。
我們給出的評價是:
1-訊飛星火、GPT
2-文心一言、通義千問
②文生圖/視頻/音頻
在語音交互能力之外,多模態能力發展之處實際上是“以文字形式輸入,以XX形式輸出”。於是我們對文生圖/視頻/音頻的能力分別做了測評。
1)訊飛星火:
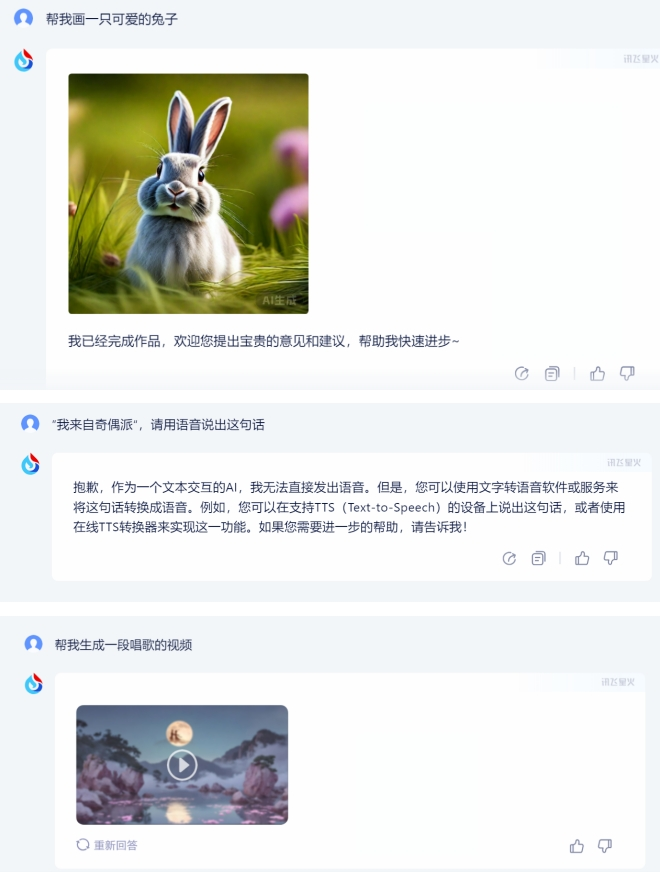
可以看到訊飛星火支持完成文生圖、文生視頻,雖然不直接支持生成音頻,但支持對回答消息的語音朗讀,並且在 App 端還可以切換朗讀的主播,因此也可以說是支持文生語音的能力的。
2)文心一言:
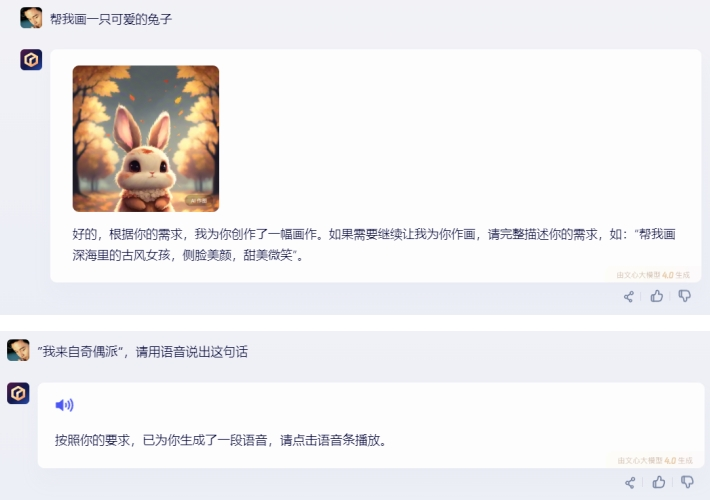
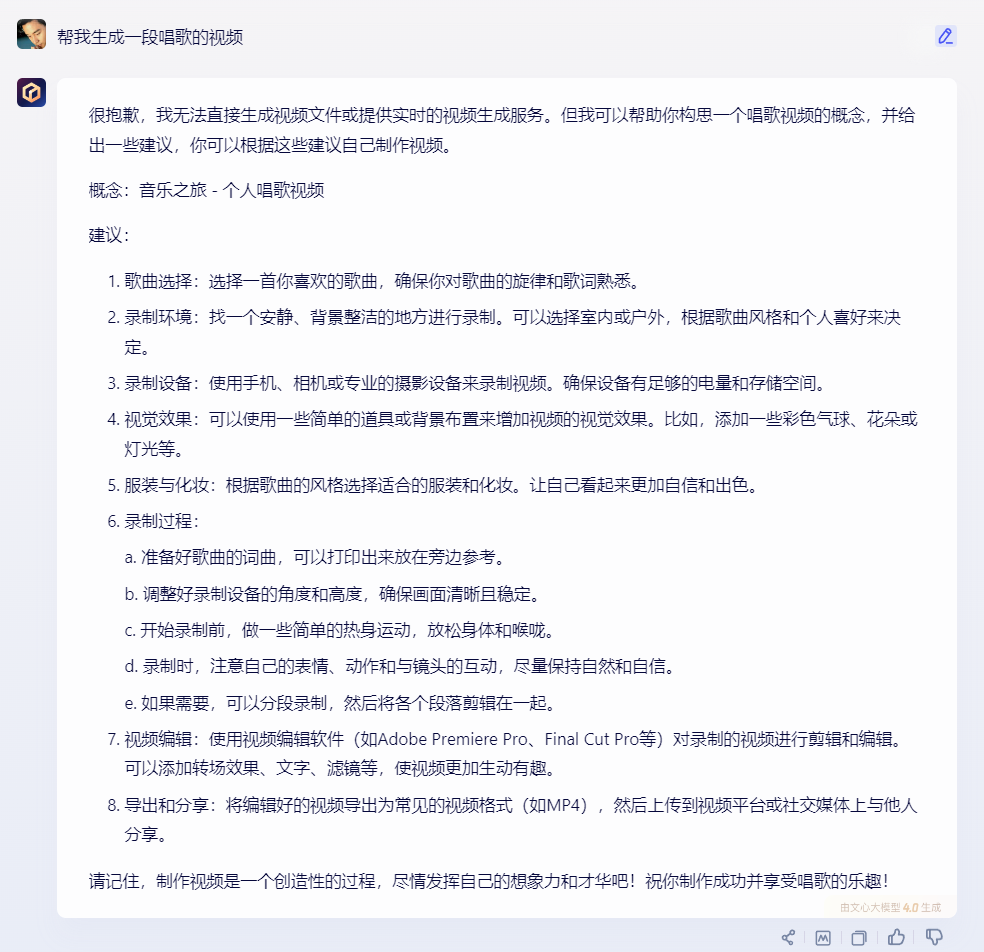
文心一言支持文生圖、文生音頻,但無法支持生成視頻,他以文字的形式試圖“反向激發”提問者。
3)通義千問:
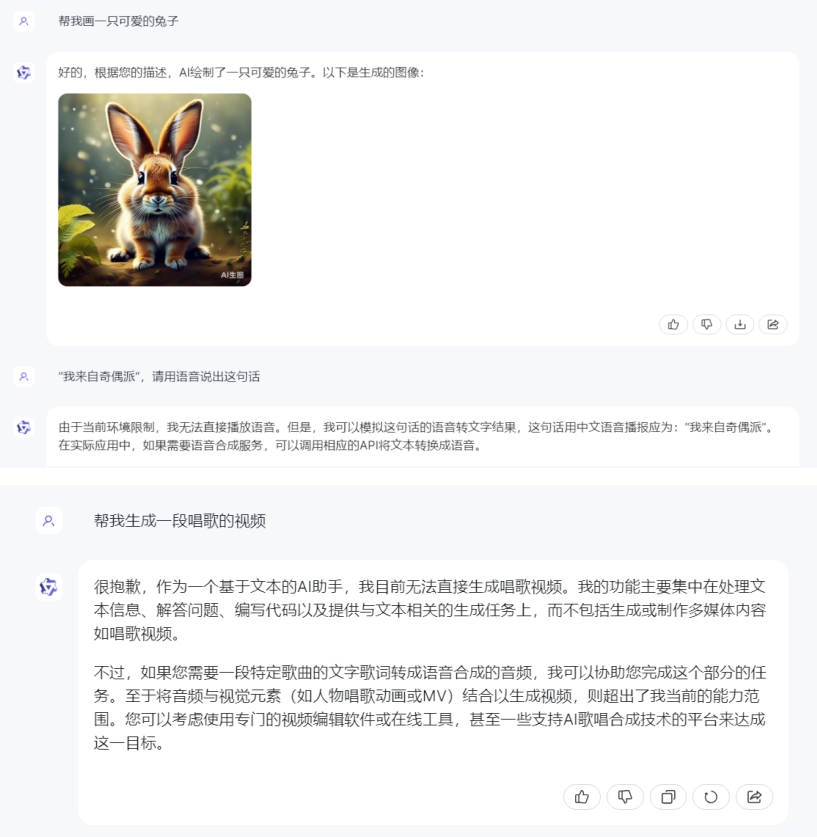
通義千問則只能支持文生圖,文生視頻、音頻均不支持。
4)GPT:
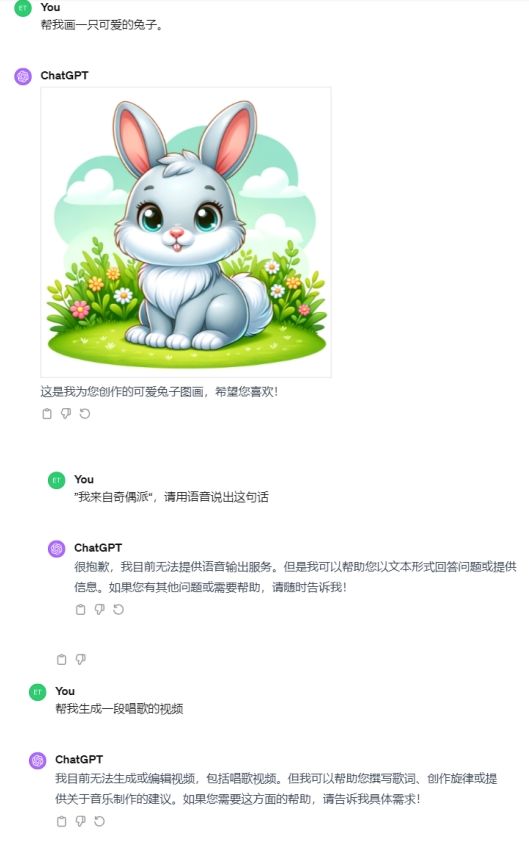
GPT可以支持文生圖,但無法支持文生視頻、音頻。
因此,總結以上,在文生圖/音頻/視頻方面,評判如下:
1-訊飛星火
2-文心一言
3-通義千問、GPT
2
語言理解能力
作爲認知大模型,語言理解能力幾乎是大模型與外界交互的基礎,我們選取了語義理解、總結提煉、抗幹擾項能力三個層面來對這一維度進行評判。
①語義理解:
1)訊飛星火:
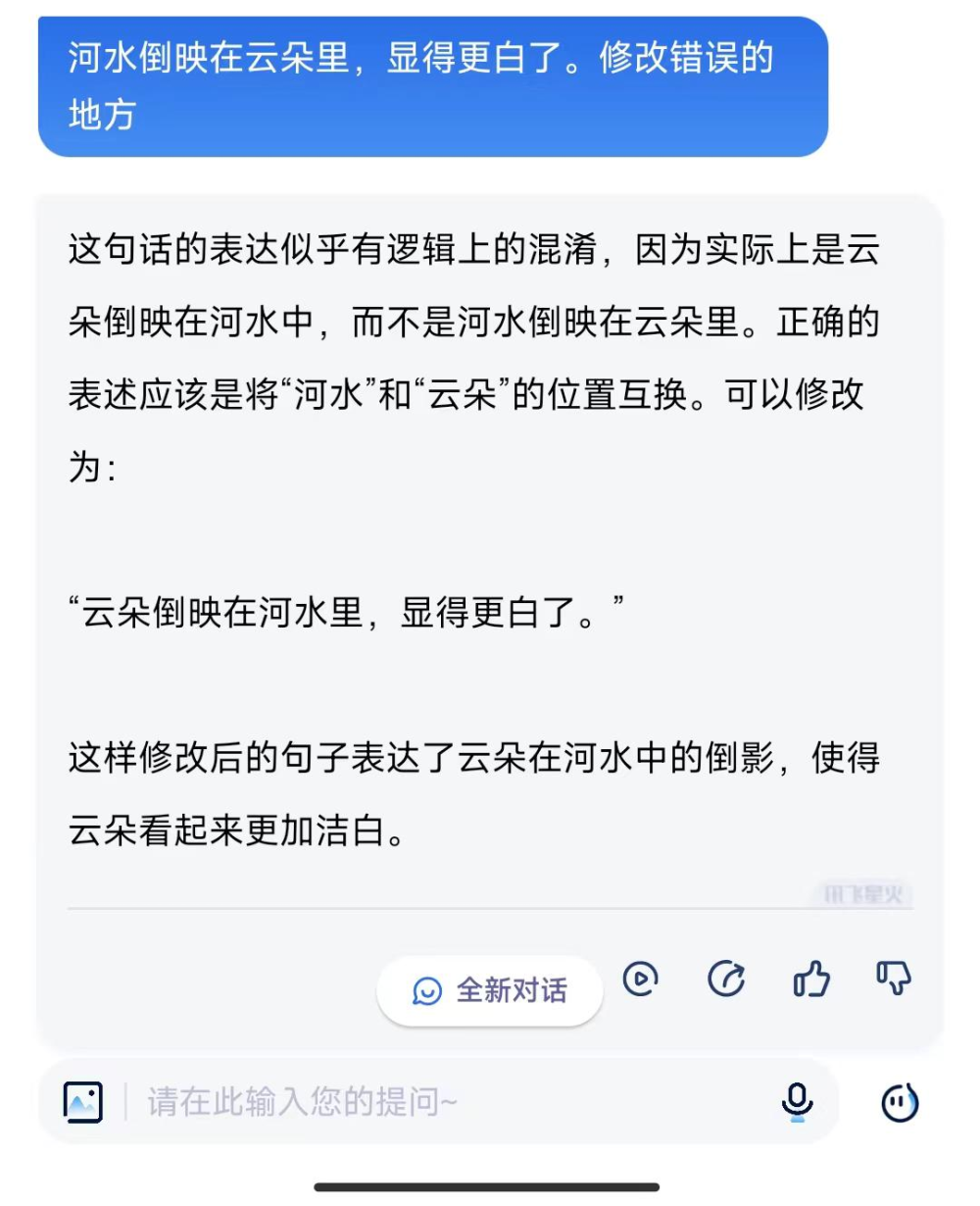
訊飛星火正確地給出了修改意見。
2)文心一言:
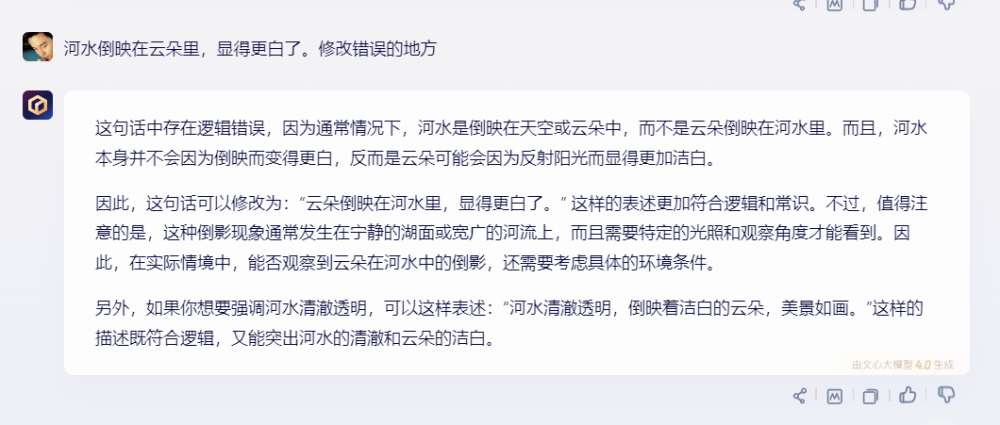
文心一言給出了正確的修改意見。
3)通義千問:
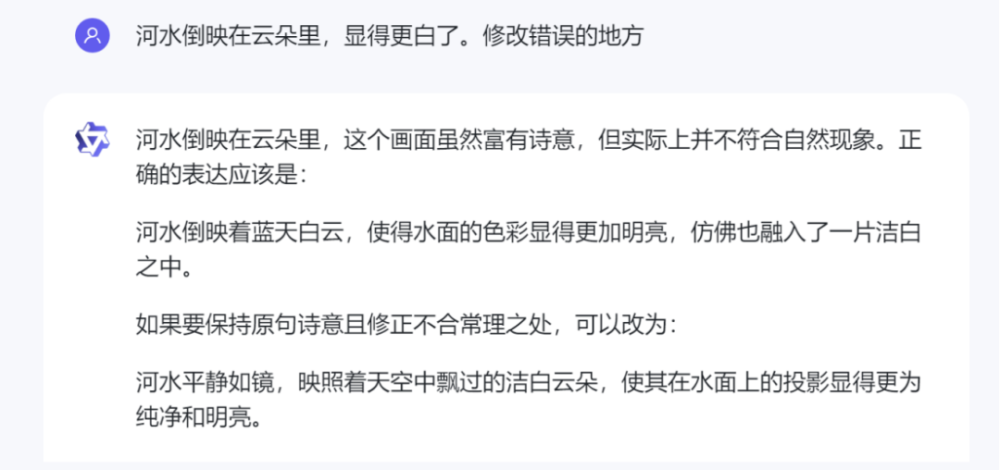
通義千問則是將句子改的更加復雜了,不符合題意。
4)GPT:

GPT則給出了正確回答且有分析。
鑑於文心一言、訊飛星火和GPT正確,因此給出評判:
1-訊飛星火、GPT、文心一言
2-通義千問
②總結提煉
對文段的總結提煉被認爲是考察大模型是否快、准、狠的重要因素,我們做了以下測試:
1)訊飛星火:
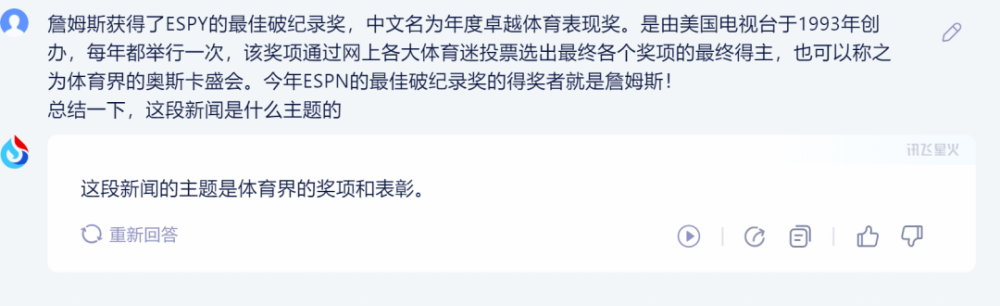
星火的回答簡潔、准確。
2)文心一言:
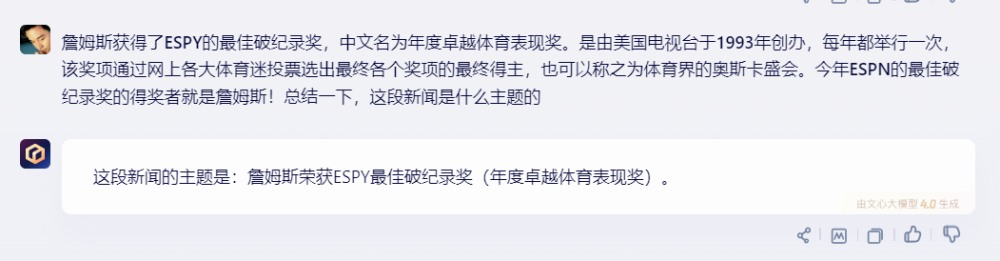
文心一言回答幾乎將第一句話復制粘貼,並沒起到總結效果。
3)通義千問:

通義千問的回答更加冗長,且幾乎就是把問題重復了一遍。
4)GPT:

GPT的回答明確,且擴寫了其介紹。
評價:
1-GPT
2-訊飛星火
3-文心一言、通義千問
③抗幹擾項能力:
抗幹擾項能力是考察大模型是否足夠“聰明”的重要手段,我們在這項考察上挖了陷阱,其實給出的問題和前面兩個半句並沒有聯系,看看他們的回答:
1)訊飛星火:

星火並沒有受到擾亂,給出了准確的回答,還附帶有詳細的分析。
2)文心一言:

文心一言的回答中漏掉了十年中有三個閏年的情況,即漏掉了3653天的答案。
3)通義千問:

通義千問的回答則不夠准確,明明算出來了實際天數可能是3652天,但最後給出答案時又去算了平均值,讓人摸不着頭腦。
4)GPT:
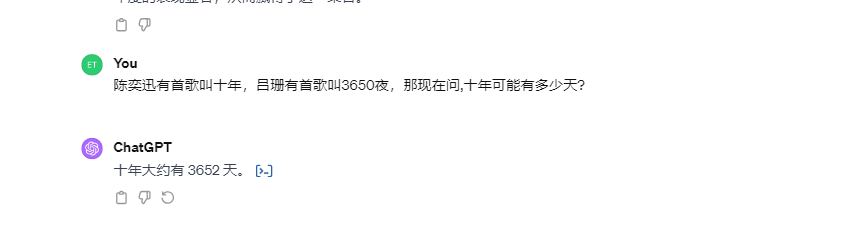
GPT僅有結果,沒有給出過程,給出的答案沒有考慮到三個閏年的可能性。
評價是:
1-訊飛星火
2-文心一言、GPT
3-通義千問
3
知識問答能力
對知識問答能力,我們從生活常識、行業知識、歷史人文知識三方面來評判。
①生活常識
對生活常識的了解應該是大模型的基礎能力。
1)訊飛星火:

訊飛星火的回答正確,且具體詳實,將制作原料、口味、歷史都介紹了一遍。
2)文心一言:

文心一言的回答正確,且進一步將所屬菜系、原材料、烹飪方法等都介紹了。
3)通義千問:
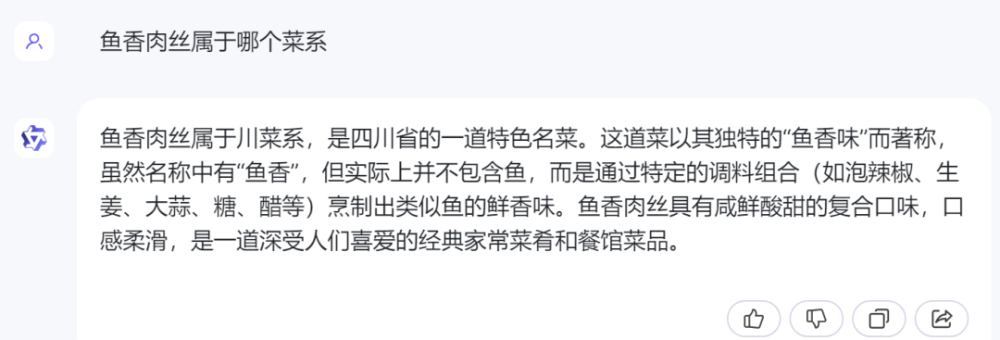
通義千問的回答也正確,且包含了對菜品的介紹。
4)GPT:

GPT的回答也正確,總體效果和通義千問持平。
評判結果:
1-GPT、訊飛星火、文心一言、通義千問
②行業知識
對某個行業知識的理解,可以起到該行業的專業人士的作用,幫助對需要了解該行業的人進行知識普及。
1)訊飛星火:
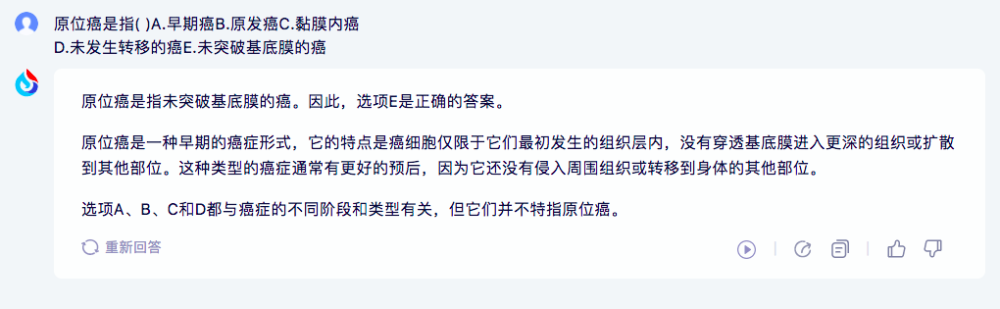
訊飛星火的答案正確、且有具體分析,對於做題的學生黨、考試黨來說很友好。
2)文心一言:
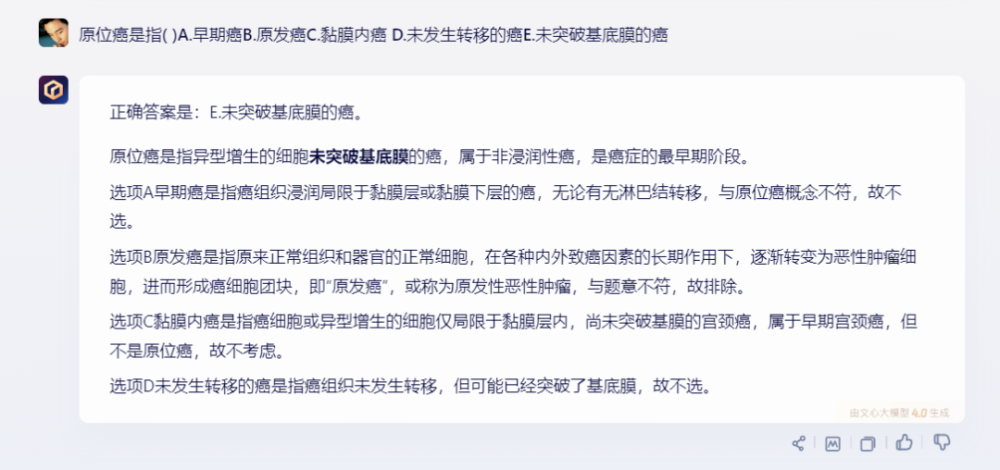
文心一言的答案正確的同時,給出了標黑重點,還有更進一步的分析,每個選項的錯誤點都指了出來,偏向於“老師向”,表現優秀。
3)通義千問:

通義千問的回答則是進一步介紹了原題提到的名詞,偏向於“百科向”,起到普及的作用,但沒有其他錯誤選項的分析。
4)GPT:

GPT的回答則介於“普及向”和“老師向”之間,沒有每個選項逐個分析,但綜合一句話可以概括。
評測結果:
1-訊飛星火、GPT、文心一言
2-通義千問
③歷史人文知識
接下來是歷史人文知識,我們用““九州”在《書·禹貢》中指冀、( )、青、徐、揚、( )、豫、梁、雍。”這個問題來考驗。這個問題比較小衆,屬於“查資料”型題目。
1)訊飛星火:
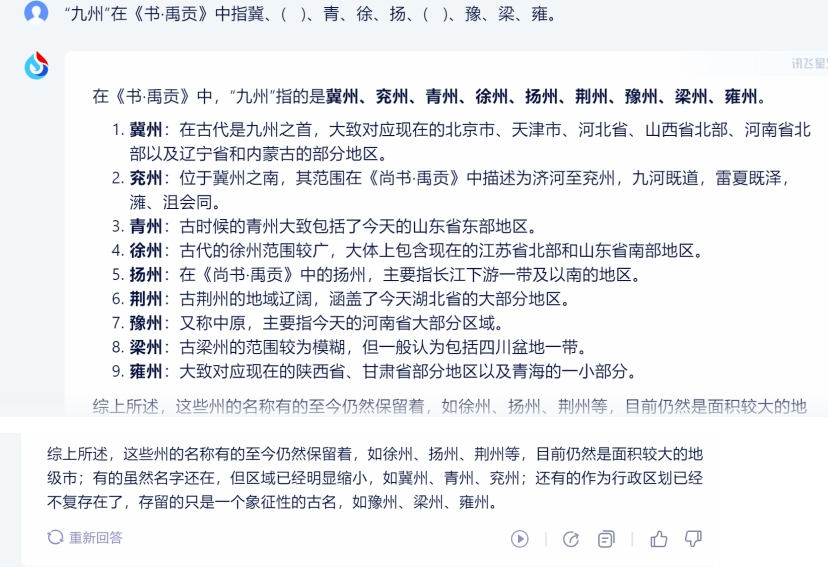
訊飛星火的回答准確無誤,且附有介紹,令人滿意。
2)文心一言:
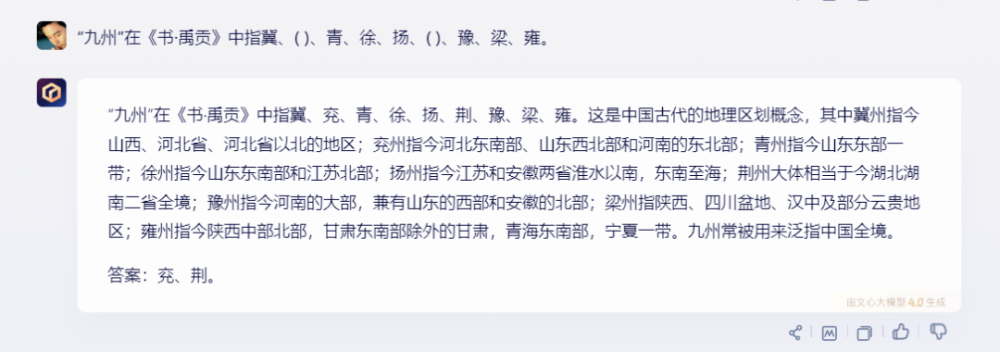
文心一言的回答正確,且有更多更詳細的介紹,介紹了每個州的地理位置。
3)通義千問:

通義千問則是只給出了答案,沒有其他介紹。
4)GPT:

GPT的回答和通義千問一樣,也是只給出了答案,沒有其他介紹。
考慮到歷史知識類問題一般需要更多分析和介紹,因此評價結果爲:
1-訊飛星火、文心一言
2-GPT、通義千問
4
邏輯推理能力
邏輯推理能力上,我們將其分類爲容易類和困難類,來進行測評。
①容易的邏輯推理問題
1)訊飛星火:
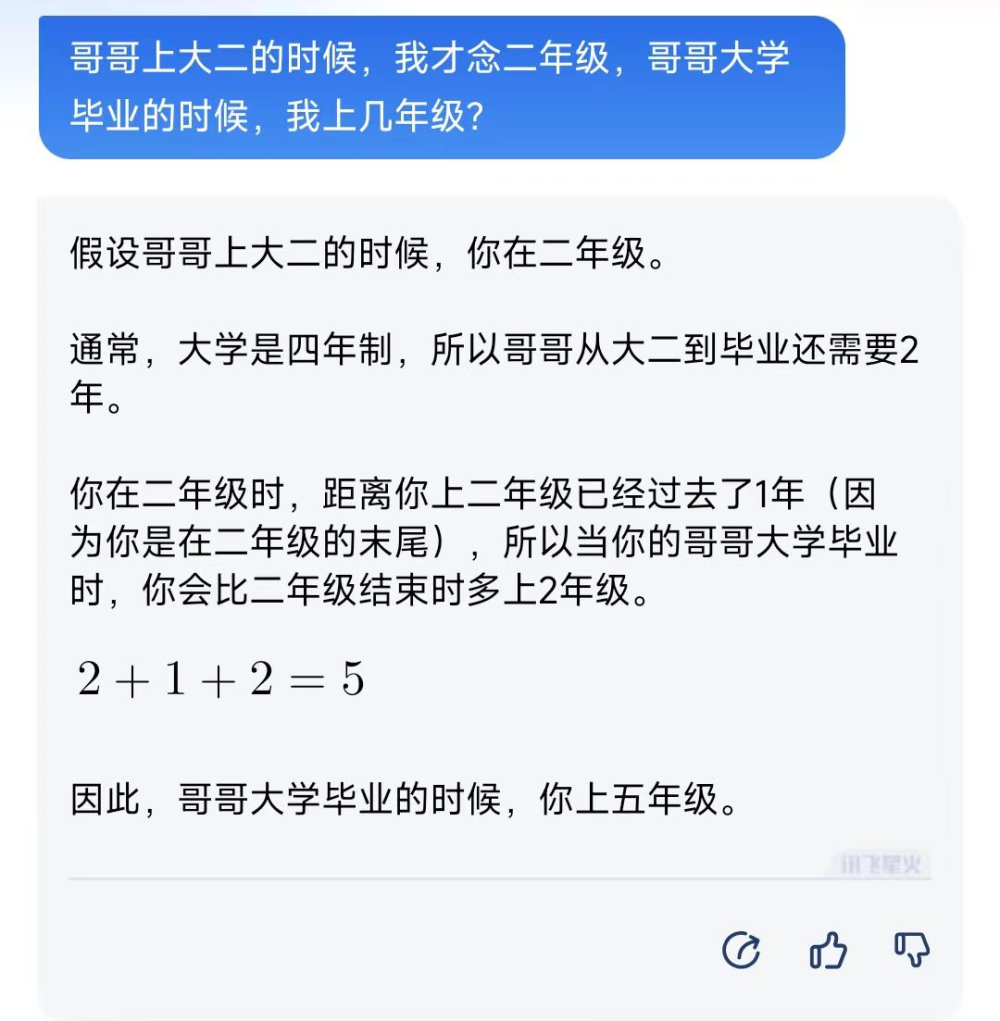
訊飛星火的答案差強人意,其中,“你在二年級時,距離你上二年級已經過去了1年”的描述很奇怪,不符合邏輯,或許是想表達其在二年級下學期,事實上這一題的正確答案應該是四年級畢業,因此說是四年級、五年級皆可,但這個解題過程有待商榷。
2)文心一言:
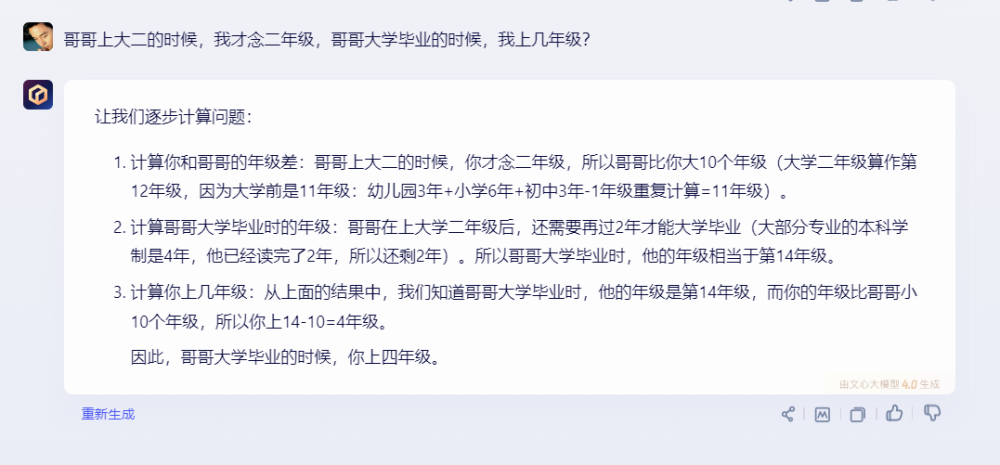
文心一言給出了正確答案。但步驟1中計算大學前年級時沒有計算高中年級,反而計算了幼兒園年級,讓人有所異議。
3)通義千問:

通義千問的答案錯誤,“大二比二年級大四個年級”的錯誤和文心一言犯的錯誤如出一轍。
4)GPT:
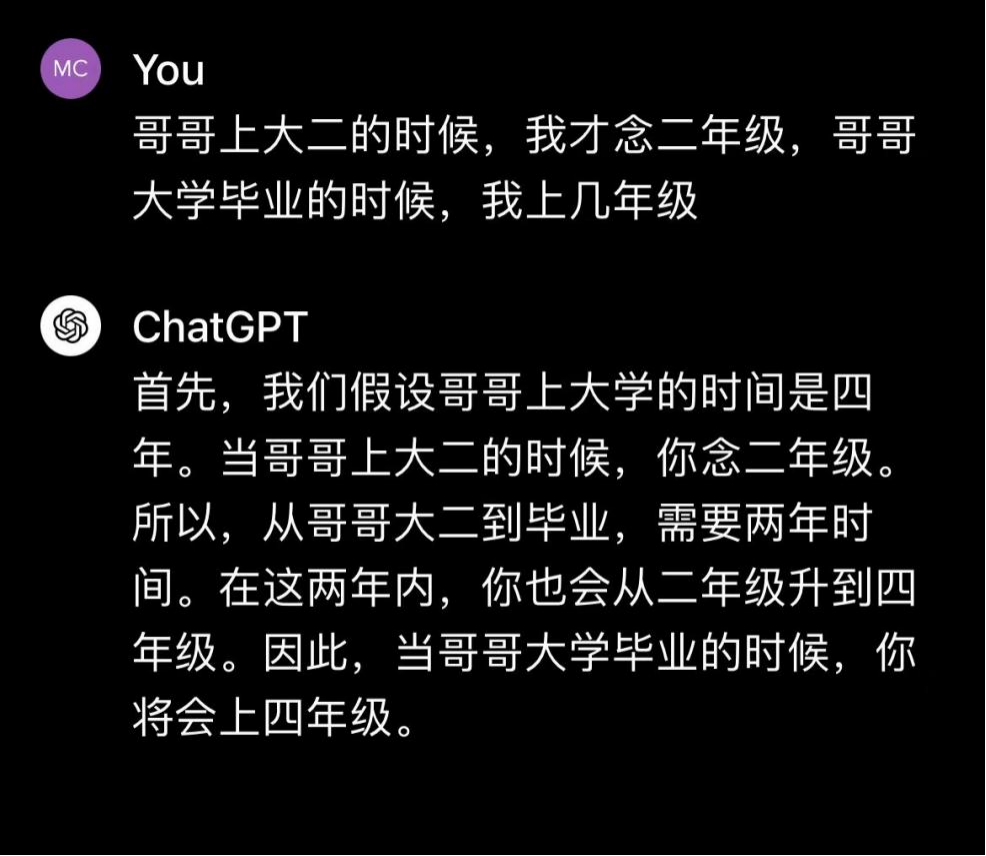
GPT 的回答邏輯清晰,答案正確。
由於除了GPT外,三個大模型均有錯誤,或是結果,或是過程,或是結果、過程都錯,所以給出評判:
1-GPT
2-文心一言、訊飛星火、通義千問
②困難的邏輯推理問題
1)訊飛星火:

訊飛星火的回答邏輯、條理清晰。
2)文心一言:
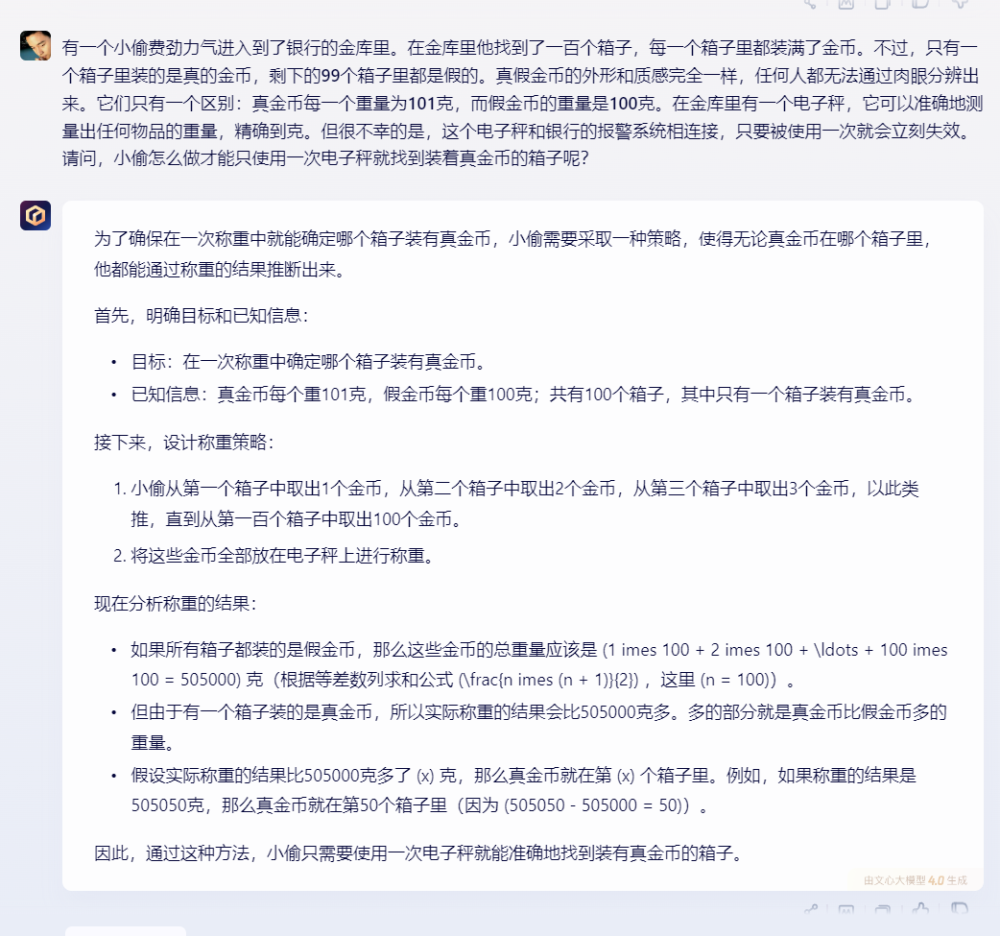
文心一言給出的答案正確,附有分析過程。
3)通義千問:

通義千問的第二個步驟中“拿一個已知是假的金幣作爲參照物”,但事實上無法在不使用電子秤的前提下確定某一個金幣是假幣,因此推導過程存在瑕疵。
4)GPT:

GPT給出了正確答案。
評測結果:
1-訊飛星火、文心一言、GPT
3-通義千問
5
數學能力
數學能力是大模型應用時的一個很重要的考量因素,尤其是許多學生朋友們,或許會用到大模型來解題。我們分爲英文提問的代數題和中文提問的幾何題,來測試四個大模型的數學能力。
①英文提問的數學代數題
1)訊飛星火:

訊飛星火回答正確。
2)文心一言:
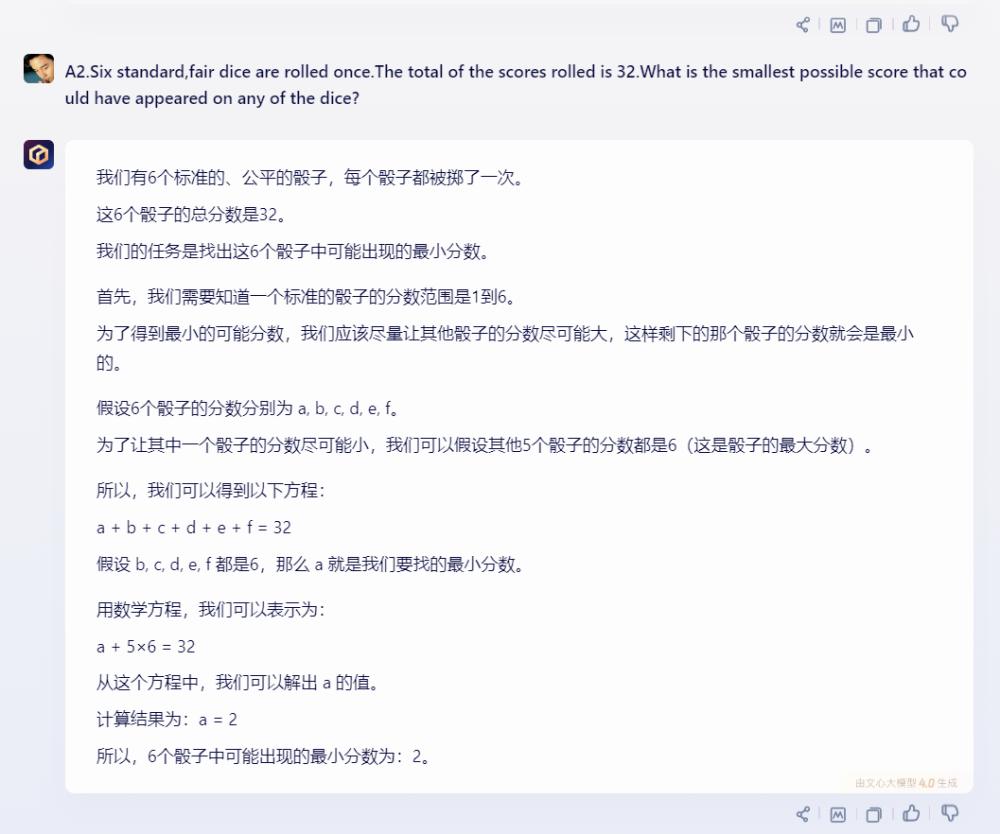
文心一言給出了正確答案。
3)通義千問:

通義千問則是同樣用英語給出了正確答案。
4)GPT:
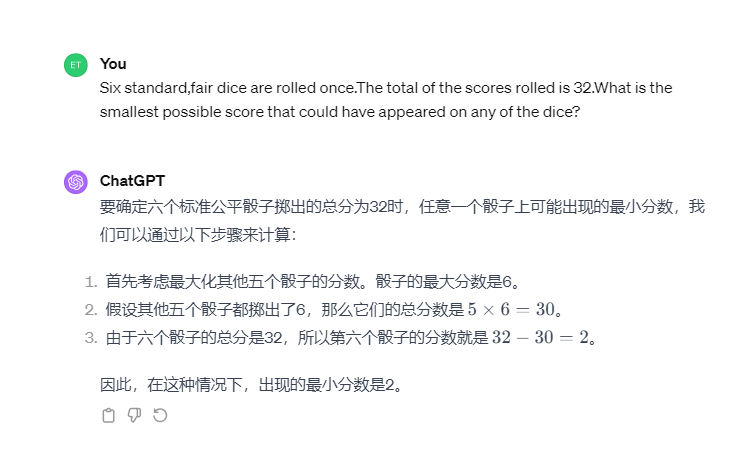
GPT給出了正確答案。
四個大模型都正確,因此:
1-訊飛星火、文心一言、通義千問、GPT
②中文提問的數學幾何題
1)訊飛星火:
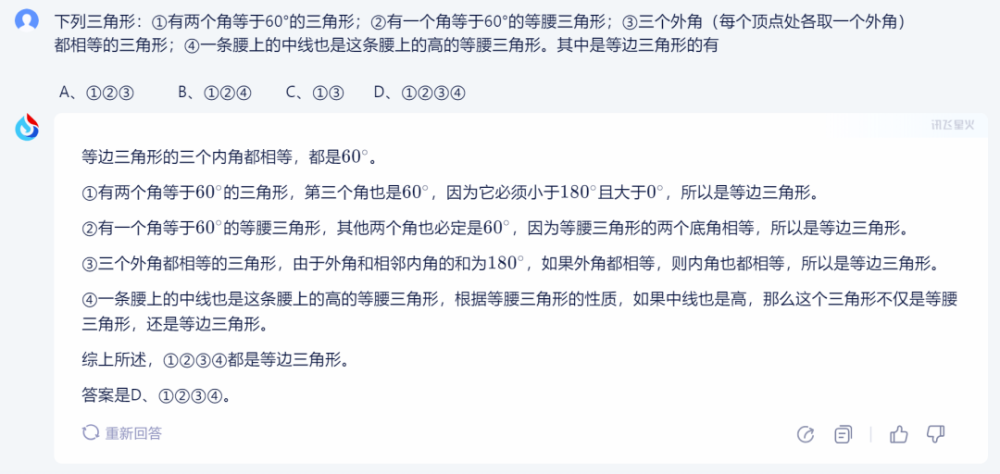
訊飛星火的答案正確,過程具體清晰。
2)文心一言:
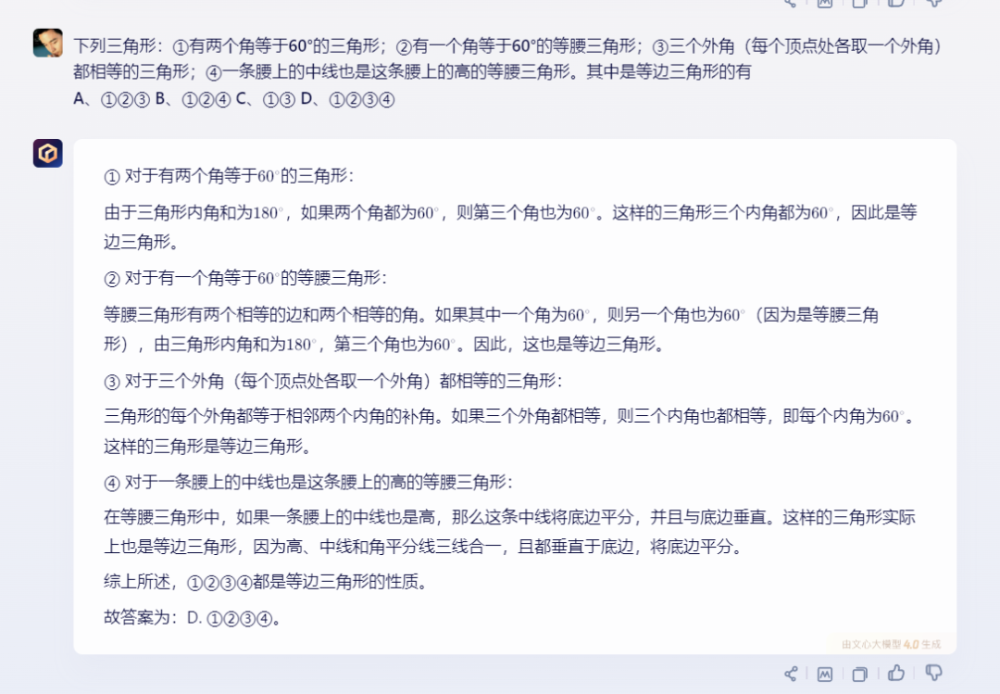
文心一言的答案正確,過程同樣具體清晰。
3)通義千問:
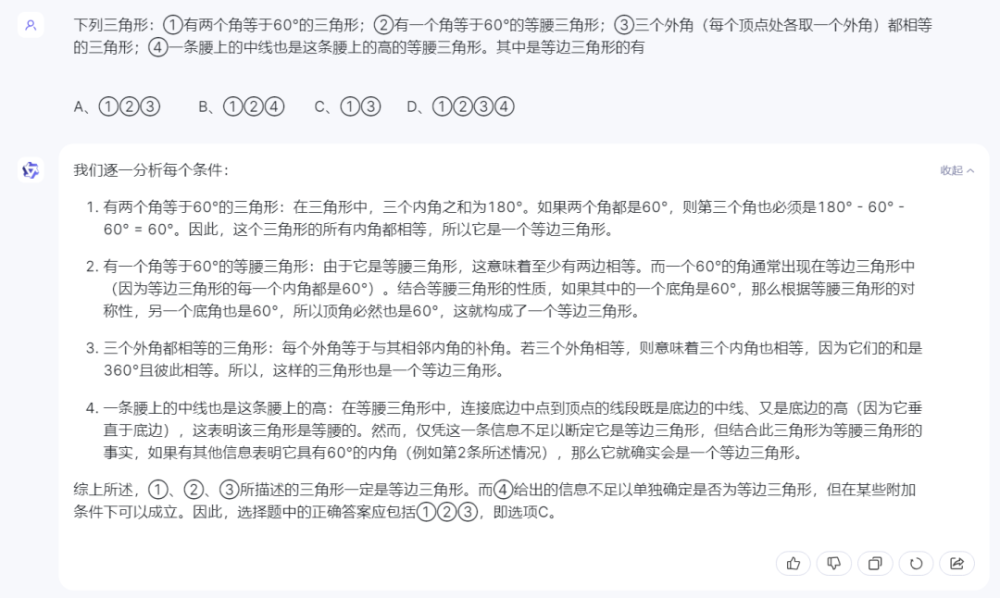
通義千問答案錯誤,前三個選項沒問題,第④個選項中顯然沒有理解題意中“一條腰上的中线”這一前提條件。
4)GPT:

GPT答案錯誤。
因此,給出的評判是:
1-訊飛星火、文心一言
2-通義千問
3-GPT
6
代碼能力
讓大模型幫助敲代碼,想必是許多程序員朋友們夢寐以求的事,我們對幾個大模型進行了代碼能力的檢測。我們提出了要求,想讓四個大模型完成“用python實現:輸入一個整數,將其分解質因數,例如輸入90,輸出90=2*3*3*5”的要求。
1)訊飛星火:
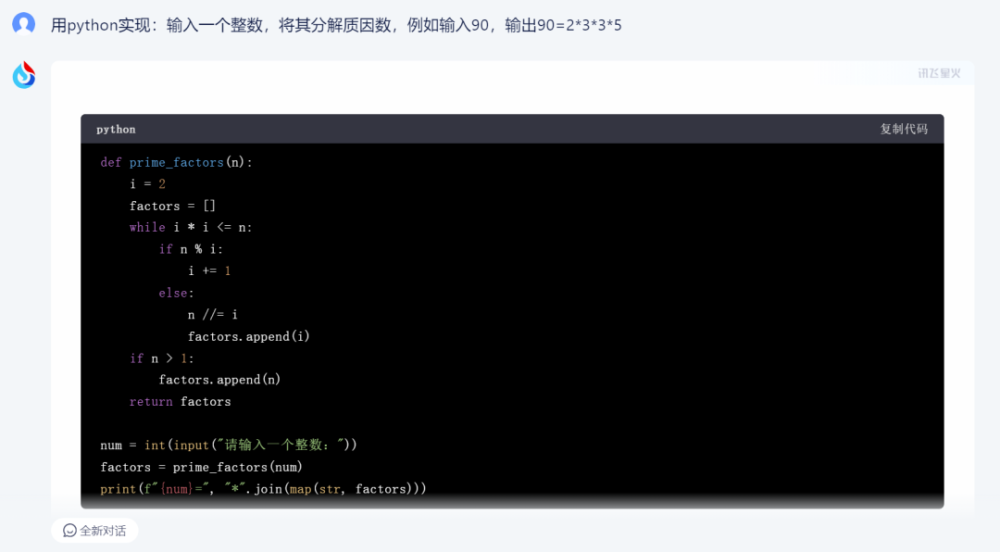
訊飛星火給出的代碼格式標准,清爽很多。
2)文心一言:
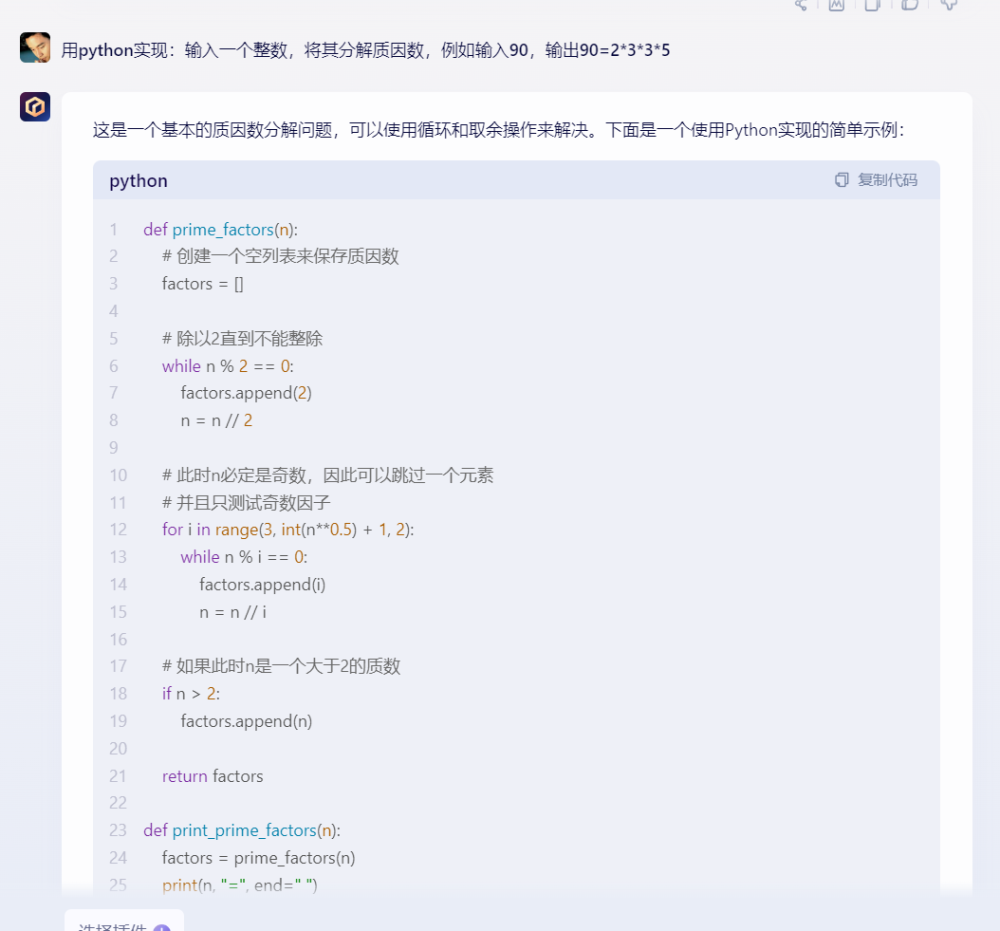
文心一言給出的代碼詳細,且有介紹,
3)通義千問:
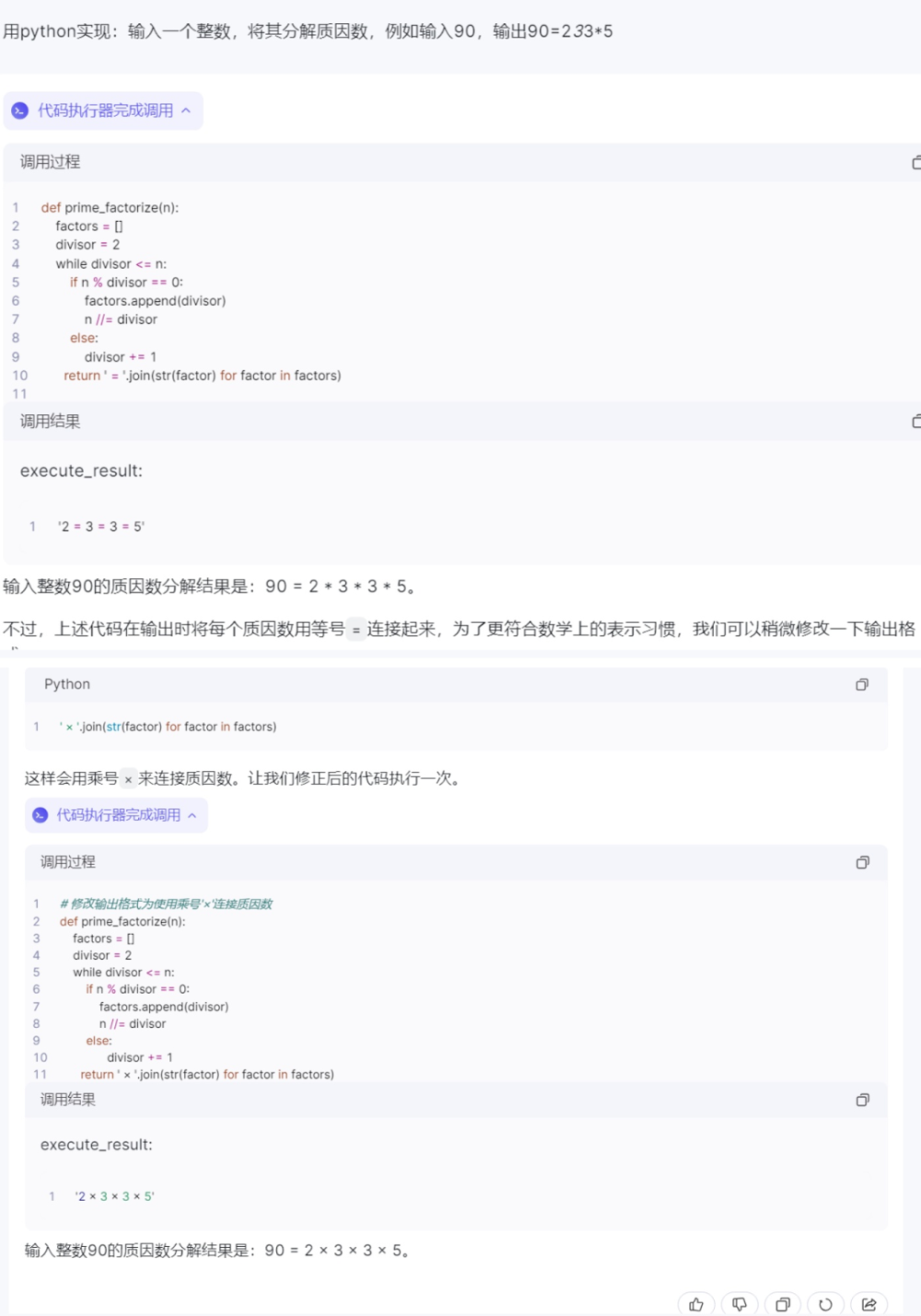
通義千問給出的代碼則更加繁瑣,且生成界面中會需要代碼執行器完成調用。
4)GPT:

GPT沒有給出代碼。
綜上,代碼能力上:
1-訊飛星火
2-文心一言、通義千問
3-GPT
7
文本生成能力
生成是大模型最核心的能力,通過對大量的文本進行訓練,能夠生成原始且連貫的文本內容,可以創造性的生成一些文本,是大模型最基礎的能力之一。這次測評中,我們從智力遊戲、文案創作、故事續寫、文章寫作、方案策劃等五個方面對幾個大模型進行評測。
下面是他們的表現:
① 智力遊戲
爲了測試文本生成能力,我們向四個大模型提問了同一個問題:“你能寫出三個關於元宵的謎語么?要包含‘團圓’二字”。這個問題的條件有兩個:1.關於元宵;2.包含“團圓”二字。
1)訊飛星火:
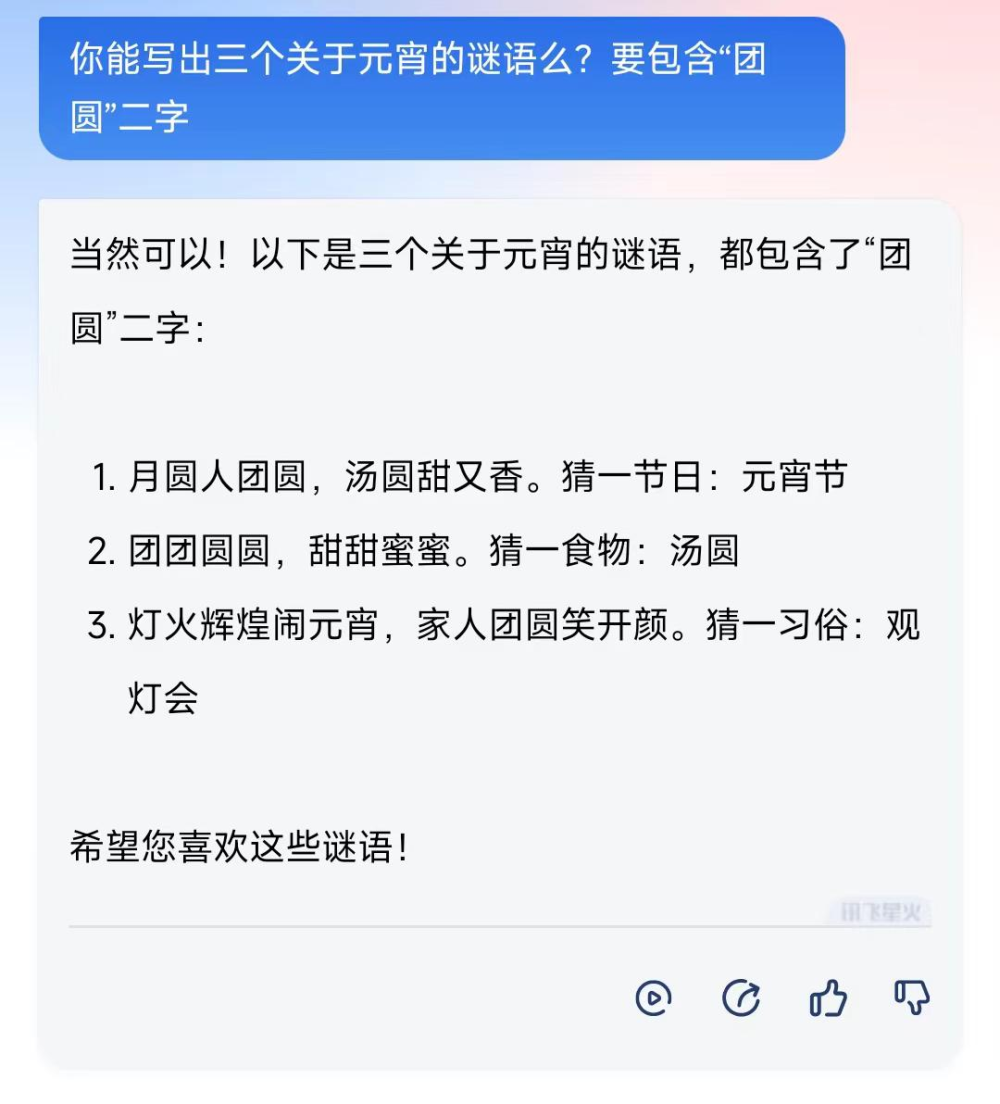
星火在作出回答之前,首先回答了“能不能的問題”,因此先回答“當然可以”,然後再做出後續的針對該問題的回答,答案也完美符合題意,但美中不足的是沒有進一步的分析。
2)文心一言:
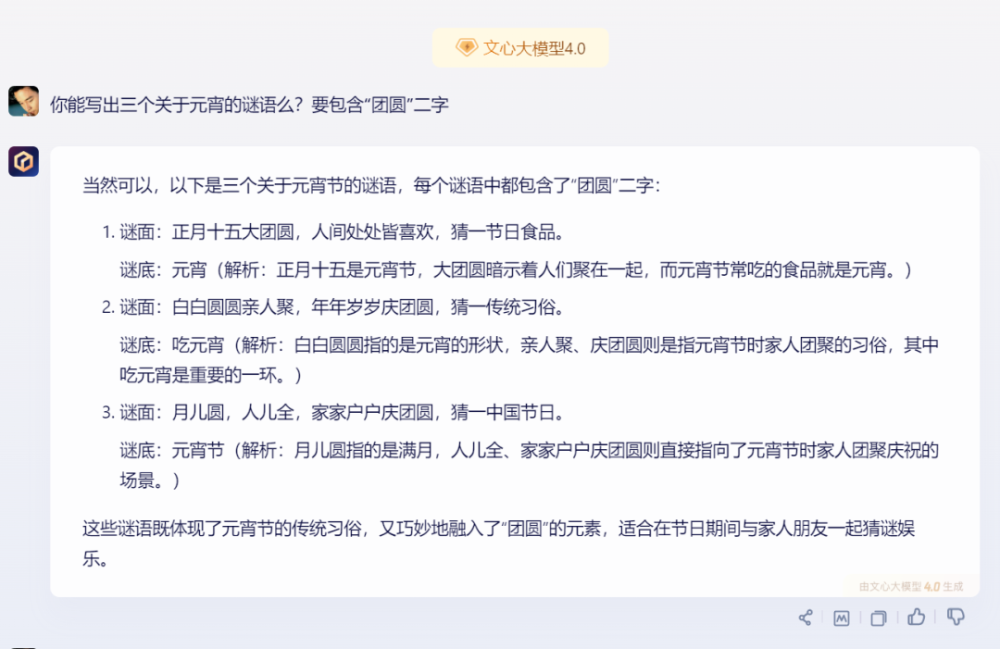
文心一言的回答符合要求,且有解析。
3)通義千問:

通義千問的回答則考慮到了兩個要求,且還有解釋介紹謎底和謎面的關系,表現不錯。
4)GPT:

GPT的回答則類似星火,在首先回答了“可以”之後,給出了比較正確的答案,但沒有進一步解析。
因此在這一層級,我們的評價是:
1-通義千問、文心一言
2-訊飛星火、GPT
②文案創作
文案創作能夠體現大模型對語義的理解和創作能力。工作、學習中,我們都可以利用大模型的文章生成能力,學習如何寫好對應題材的文章。這裏我們以 "兵地融合共建" 爲主題,讓四款大模型寫一篇新聞稿,並給出了具體的結構要求,看看他們的寫作能力如何吧。
1)訊飛星火:

首先是訊飛星火,這篇文章條理清晰,觀點明確,但並沒有按照要求的結構來寫,且地點以“XX”來代替,不夠具體。
2)文心一言:
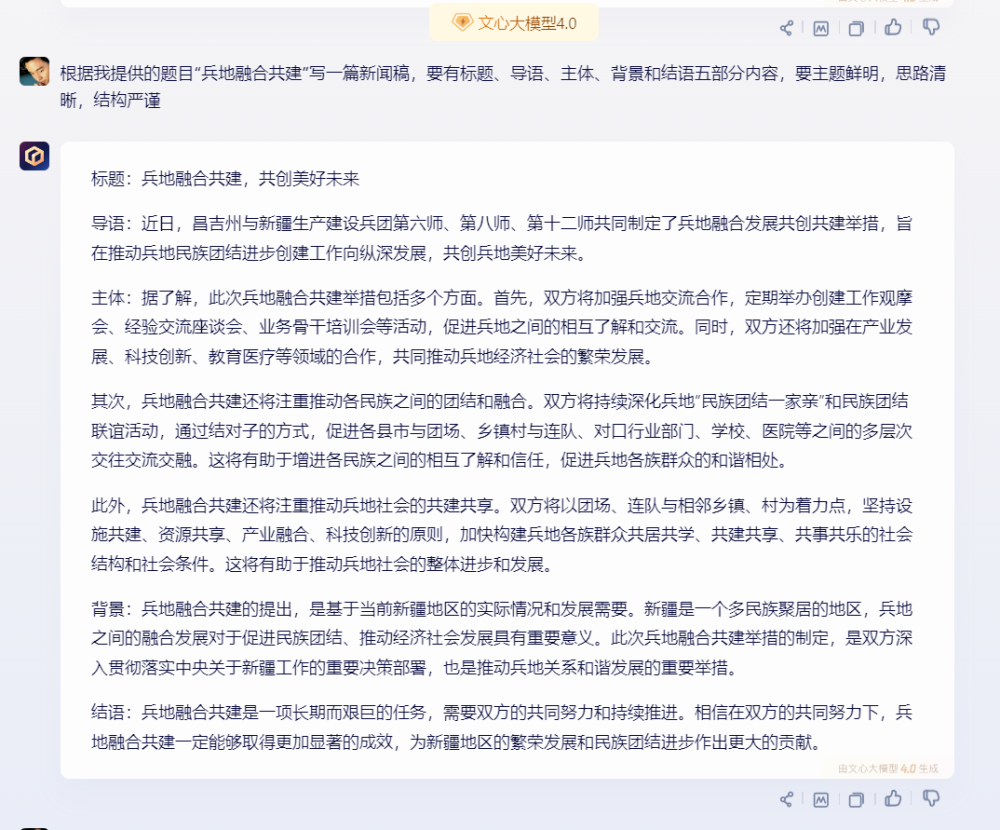
其次是文心一言,它的文章嚴格按照要求的結構來寫,且自身確定了“新疆”這一地點,文章條理清晰,脈絡明確。其中“主體”部分還分成了三項依次陳述。
3)通義千問:

通義千問方面,生成的文章同樣嚴格按照要求的結構,美中不足的是,“主體”部分本應作爲文章的詳寫部分,其他部分爲略寫部分,在詳略得當方面做的不好。
4)GPT:

GPT方面,生成的結果主題、結構都沒問題,背景、結語也都緊扣“兵地融合”,表現優秀。
我們給出的評價是:
1-通義千問、GPT、文心一言
2-訊飛星火
③故事續寫
故事續寫是考驗大模型創作能力的一大指標,我們以經典的“小白兔”、“大灰狼”作爲主角开頭,看看他們會續寫出怎樣的故事。
1)訊飛星火:

可以看到,訊飛星火續寫的故事非常詳細,描述生動形象,甚至分成了四個章節,可以算是寫了一本短篇小說,而且小說內含寓意,最後一個章節點出了“不應該僅憑外表和傳言判斷他人”這種道理,可以稱得上是一篇優秀的寓言故事。
2)文心一言:

文心一言給出的故事則相對更短,且沒有太多後續情節,故事邏輯和場景相對單一。
3)通義千問:

通義千問給出的故事相比文心一言要更加成熟,但總體來說,文章走向很類似於訊飛星火的文章的“章節一”,整體不錯,但文章的完整度略顯不足。
4)GPT:

GPT續寫的故事則和通義千問如出一轍,有一定對話,雖然故事比較簡單,但整個故事立意更加成熟,且結尾更留有余味。
綜合來看,在故事續寫部分,我們給出的評價是:
1-訊飛星火、GPT
3-文心一言、通義千問
④方案策劃
對於身處職場、體制內、或者身居組織責任要職的朋友們來說,經常需要擬定一些活動方案、評定標准等,我們以“我是一名房地產銷售主管,我要給我的三個下屬制定KPI。請你給我一點KPI參考”爲主題,來進行測試。
1)訊飛星火:
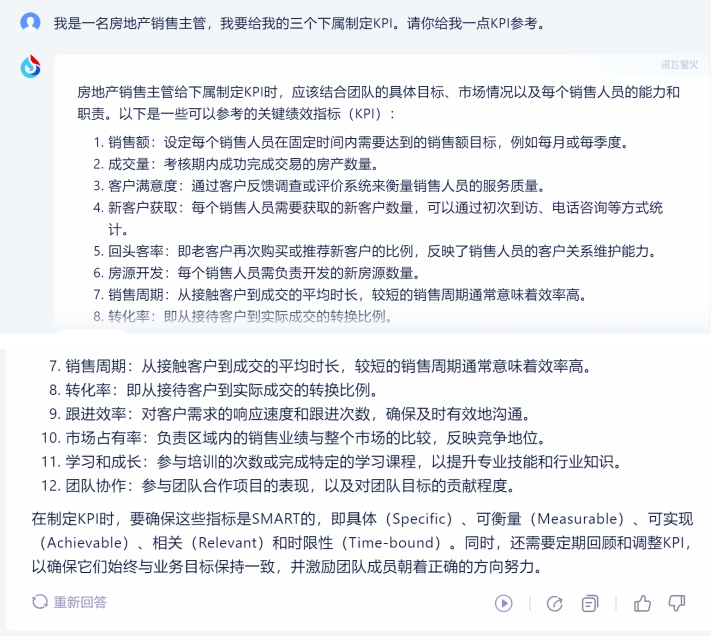
訊飛星火擬定的KPI標准細則最多,共有12條,詳實具體,每一個標准都有介紹,可操作性較強,且還在最後給出了確定這些指標的方法,可以作爲不錯的模板使用。
2)文心一言:

文心一言給出的標准較少,且並沒有給出爲什么確定這些指標,比較簡略。
3)通義千問:

通義千問則是首先回答了制定標准時需要考慮的因素,之後給出了8條標准,每條標准下轄一個指標或者具體可量化的參考,且也在最後簡述了制定這些標准的方法,還比較貼心地提醒提問者“定期回顧、適時調整”。
4)GPT:

GPT給出的答案優點是:每個標准都給出了如何評判的具體介紹,但缺點在於:沒有提到制定這些標准的因素和方法,但只是給出了評判標准,沒有給出具體指標。
因此,這層級,我們給出的評判是:
1-訊飛星火、通義千問
2-文心一言、GPT
8
寫在最後
本次橫評,我們從語言理解、文本生成、知識問答、邏輯推理、數學能力、代碼能力和多模態能力等方面對文心一言、訊飛星火、通義千問和ChatGPT四款大模型做了詳細的體驗橫評。
測下來後,在國內大模型中,訊飛星火在產品體驗上大幅領先,其中多項測評排列第一,尤其是在全語音交互能力上,星火V3.5作爲國產大模型中目前支持“實時通話”的佼佼者,已經表現出了很強的實力。這對於加強星火後續的多模態能力升級有着非常重要的战略意義。
當然,訊飛星火也並非完美,在文本生成和知識問答等部分細分領域,星火V3.5也表現欠佳,但總體來看可以說是和GPT有來有回的。
文心一言和通義千問表現也不錯,其中,文心一言主要擅長知識問答,這也與其背靠百度這一搜索引擎巨頭有着密不可分的關系。
當然,本次橫評所使用的問題樣本有限,大家實際體驗時的感受可能與我們橫評的內容有出入,因此上述位置值也僅供大家參考,實際選擇時,大家還是要根據自身的感受來選用適合自己的 AI 大模型。
無論是訊飛星火,還是文心一言、通義千問,都是國產大模型的第一梯隊,在當前的科技競爭、產業競爭的局勢下,背後都要加強創新,實現我們在通用人工智能上的追趕與超越。
原文標題 : AI大模型哪家強?七大維度橫評四款主流大模型!
標題:AI大模型哪家強?七大維度橫評四款主流大模型!
地址:https://www.utechfun.com/post/327372.html