“您認爲AI公司在昆明,跟北上廣相比有什么優勢?”
“我覺得昆明就是中國的硅谷,氣候特別好。”
這段對話,是在一次人工智能主題座談會上真實發生的。
經常參加這類交流活動的朋友可能會懂,這類問題一般在“遞話”,給受訪人一個“安利”自家的產品、技術、差異化價值的由頭。所以當現場有人拋出這個問題時,我也做好了聽到一堆PR公關辭令的准備。
沒想到,這位昆明某AI服務商、數據科技公司的技術負責人,給出的答案是大家都沒有設想過的。但這種“意料之外”,展現出在“北上廣”這類大城市少見到的“地氣”。
活動結束後,我和這位技術負責人單獨聊了聊,又發現了一種“意料之外”。
他們公司也在做大模型,用的是开源Llama架構+國產算力,經由私有數據微調,爲雲南遊客提供线上問答服務。
你可能會問,AI模型都不是自己從底層代碼寫上來的,有什么差異化競爭力?實際上並不是大家想的那么簡單,只要調用API再用數據跑一遍就行了,他們在模型之外做的工作非常多且扎實。

比如,他們服務的一些雲南本地企業,可能連數據標注、數據治理、數據工具鏈等基礎概念都不知道,高質量數據集、文檔也沒有,想要訓練專有AI模型,就得從自己組建“標注組”开始。因爲客戶都很在意數據隱私,所以一個組的項目做完就要解散,標注人才就流失了,下次再重新建組。今天的AI落地,依然高度依賴“有多少人工就有多少智能”。
當我們走到三、四线城市,發現這裏的AI公司和开發者,對AI的認知和做法,都有很大的不同。
用這些“意料之外”,我們可以大概拼出一張拼圖,上面寫着:在小城市做AI,究竟是一種什么體驗。
小城做AI,如同養“中華田園貓”
雄踞全球科技資本和人才的硅谷,是OpenAI、DeepMind等頂級AI機構生長的土壤。那么,中國三、四线小城市的一方水土,會孕育出怎樣的AI呢?
在雲南,我見到了兩個AI服務商,以及不少开發了行業AI應用的實體企業,他們的AI模型有一個共同點:都使用通用大模型作爲基座。比如基於开源Llama 2架構,加上自有數據、客戶數據進行精調,底層代碼都不是自己從頭寫上來的。
站在巨人的肩膀上,是目前在小城市做AI的最優解。
當地的AI开發者告訴我,首先,他們測試了市面上主流的开源大模型和閉源大模型,最終選擇了Llama,原因是模型在業務場景下的表現好,而且生態夠豐富,社區資源多,配套工具成熟,這給他們的後續訓練和开發減少了很多難度。

此外,身在三、四线城市的AI公司,往往並沒有足夠的預算、算力、工程人才去從頭訓練一個新的大模型,加入开源社區或閉源生態是最現實的選擇。一位技術負責人說,他們沒法像大廠那樣囤上幾千幾萬張英偉達算力卡,加上N卡價格瘋漲,所以用的是國產算力,雖然需要解決跟CUDA的兼容性問題,但能滿足他們的需求,是目前比較有性價比的選擇。
另外,他們在本地垂類賽道,數據和工程是核心競爭力。這些三、四线城市的AI公司,沒有股價壓力,也不需要給投資人PR,專注於某一個非常小的垂類場景,一般也是大廠看不上、不會去碰的小市場,依靠私有數據積累和工程化交付的能力,就能建立起商業模式。
因爲很多落地場景,只有在當地深入了解行業才能發現。
比如一個AI公司,基於开源大模型+自有旅遊數據开發的民宿大模型,已經在雲南大理的民宿落地了。而將大模型的對話能力,打造成“24小時AI管家”,這個靈感來自民宿會遇到社恐的遊客,或者不希望暴露隱私,不想因爲WiFi密碼等小事麻煩服務人員,管家的介入很難做到恰到好處,讓遊客住的不夠舒適自在。而大模型出來之後,就在旅客和管家之間,多了一個AI交互的緩衝地帶,一些小問題通過AI管家就能解決,需要人工服務時隨叫隨到,這樣就很好地解決了旅客的顧慮。
目前,該公司的AI大模型服務,主打的就是可落地、支持私有化,目前覆蓋了文旅、工業、政務等場景,業務營收有70%以上來自大型企業的數智化。
實話說,很多一线城市的AI創業公司、高校科研院所打造的大模型,都未必能產生這樣的落地能力和經濟價值。
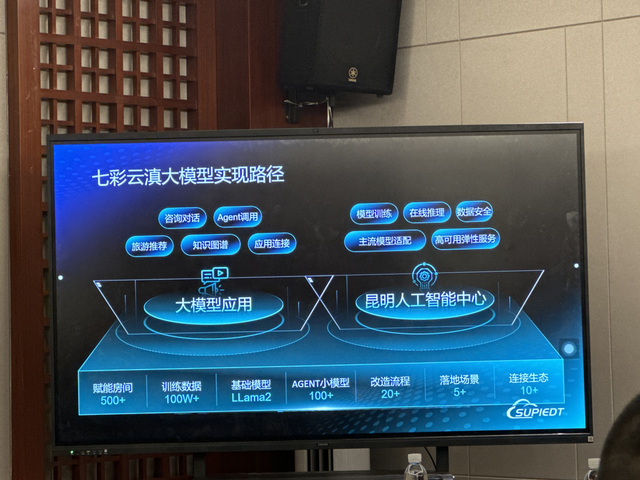
總的來說,我的感受是,三、四线城市的技術從業者,上來就是從場景裏找機會,找跟AI的結合點,反而更容易出效果。
一位开發者朋友是這樣說的,“搞AI就像養貓,科學家們和企業會養聰明的品種貓,這跟我沒什么關系,我喜歡養小貓串串,把AI領域跟人文藝術領域結合起來,這個品種你沒見過吧”。
將通用大模型的“品種貓”跟本地場景、本土需求相結合,進行“雜交”,養出一只只“混血小貓”,這些垂類AI應用,就像中華田園貓,可能是大廠和科技媒體人不太關注的,卻沐浴着雲南得天獨厚的陽光,真實而有生命力地成長着。
在小城市做AI的可能性
在交流活動中,有好幾個媒體人都詢問,在雲南做AI有哪些阻礙和挑战。真正的問題,似乎在意料之外,又在情理之中。
所謂意料之外,是很多問題已經在被積極解決了。

比如基礎設施,在大家的印象中,三、四线城市的數字基礎設施發展比較晚,發展AI的資源稟賦比較薄弱。實際上,基礎設施在當地越來越不成爲問題。
拿算力來說,雲南的算力資源已經可以滿足當地AI的开發需求。當地工作人員告訴我們,由於電價便宜,氣候條件好,所以雲南很適合發展AI人工智能數據中心,前文提到的民宿大模型,就是在昆明人工智能計算中心上進行訓練的,採用的國產算力。當地交通領域的數據中心工作人員也提到,該行業數據中心已經完成了60%的國產替代率。
至於數據,參加交流活動的兩家AI服務商,此前都是數據服務提供商。其中一個成立於2018年,在2020年的時候就形成了第一版數據解決方案,和一、二线的大廠籤訂了合作關系,積累了大量的數據資源和工程經驗。而算法,如前所說,依托全球領先的开源模型和社區,當地AI公司也可以快速上手开發。
那么,當地AI發展的真正約束條件是什么呢?
一是遠離產業帶。行業AI解決方案包含了多個環節和生產鏈條,很多小城市還沒有建立起產業集聚優勢,導致生產環節中存在斷點。一位昆明當地的AI服務商提到,客戶的私有化部署,往往需要單獨成立標注組,項目完成就解散了,人才就要流失。而他們跟省外的標注公司合作,有的要收取加盟費,有的對團隊規模有要求,必須達到100人以上,這就給他們的項目增加了不少成本。

二是缺人。既然到外省找人很麻煩,那么找本地人才呢?答案就是當地沒有那么多AI人才。那一場交流活動中,也有雲南當地的AI產業學院老師參加,對方提到,該學院今年招收了200名人工智能專業的本科生。現場一家AI公司表示:“200個?根本不夠用啊。”
除了人數少,由於人工智能是一個新興專業,當地也還在探索培養方案,有老師提到,目前AI教學還存在跟應用領域不夠貼近的問題,企業提供的AI實訓平台不符合教學、科研的需求,學校只能自己开發。
如何解決上述困境?我也在當地看到了一種跟开源文化有點類似的產業集群創新模式,那就是“抱團取暖”。
一家本地的數據服務公司,將自己打造的數據標注、數據治理、數據探源等工具鏈,开源出來,豐富區域內的數據資源。此外,依托昆明人工智能計算中心,當地也在陸續开展師資培訓、工程師培訓等人才培養項目,打通“學練訓賽業”,推動產學研用的融合。
遠離了“北上廣”和“龍頭企業”的三、四线城市,由於AI產業鏈的零星聚集,反而跟彼此產生了格外強的引力,特別積極地希望貢獻出自己的一份力量。
產業AI的“面子”和“裏子”
說到這裏,你可能會問,那三、四线城市的AI落地情況究竟怎么樣?跟當地產業相結合的廣度和深度如何呢?
我可以分享兩個真實的見聞故事:
一個是“面子”。在中國-老撾的邊境城市,當地工作人員帶我們參觀了位於火車站附近的“智慧展示中心”。我們發現,這個展示中心的作用,確實是“展示”,我們到大屏幕前觀看完兩部宣傳片,就沒能再深入了。
另一個是“裏子”。當我們走到日常運行的貨車檢查站,一個工作人員對着鏡頭侃侃而談,告訴我們5G+AI的應用如何落地,讓貨車一站式通關,避免了層層卡驗,將每輛車的平均通關時間從8分鐘縮短到4分鐘。從技術規劃到落地效果,講的非常清晰,帶着一種很了解一线實際情況才有的揮灑自如。
對此,不同的人可能會有不同的解讀角度。
AI應該樂觀嗎?好像是的,它已經抵達了最遙遠的邊境线,在n线城市落地。AI應該悲觀嗎?也有點道理,有效的AI應用似乎就那么多,作爲“典型案例”存在,而如果沒有AI場景的遍地开花,那么建好的AI基礎設施發揮的作用,確實就是擺在那裏,作爲“展示”。
今天,三、四线城市的AI探索,處於一個智能化需求特別多、特別分散的階段,只能一個場景一個場景地滲透。而這也是本地AI企業和开發者的機會,也有越來越多的人看到了這些地方存在的無數個被AI改變的可能性。

在當地走訪時,本地AI企業提到一句話:通過一個場景,探索出一些模式,應用到整個行業,一個個場景的智能化,拼起來就是整個行業的智能化。
他們確實也是這樣做的。
這些微小而分散的需求,是AI大廠和巨頭不愿意觸碰,做了也投入回報比很低的場景,被當地企業一個接一個地解決着。
比如雲南开發出的越南語、老撾語、緬甸語、柬埔寨語、泰語等南亞東南亞語言的掃描筆、AI翻譯機;幫助企業無需寫字段調用API,就能根據不同的使用場景,比如經營分析會、領導參觀匯報、財務數據上報等,實時生成任意需求BI的垂類大模型;爲麻醉科提供高效智能排班服務的大模型等。
大模型狂奔這一年,已經從價值炒作階段進入到價值沉澱階段,有大模型廠商提出了“不作詩、只做事”的理念。那么,誰來做事呢?
這些在小城市做AI的人,用一個個場景的拼圖,拼出了大模型“有用”的答案。而AI的小城故事,還會在這片土地一直講下去。
原文標題 : 打卡智能中國(七):AI的小城故事
標題:打卡智能中國(七):AI的小城故事
地址:https://www.utechfun.com/post/306055.html