在國內大模型競爭愈發競爭激烈、難落地的當下,智譜AI的模式有什么特殊之處?以及被資本追捧的它能給中國大模型帶來哪些不一樣的思考?
作者|鬥鬥
出品|產業家
對於智譜AI而言,很長一段時間裏,“衆星捧月”這個詞再合適不過。
前段時間,智譜AI的最新一筆融資再次引發了廣泛關注,成爲萬衆矚目的焦點。公开信息顯示,新一輪融資金額超過 25 億元人民幣,加上前幾輪融資,智譜AI市值已經突破百億。
更值得注意的是投資方的豪華陣容,包括社保基金中關村自主創新基金(君聯資本爲基金管理人)、美團、螞蟻、阿裏、騰訊、小米、金山、順爲、Boss 直聘、好未來、紅杉、高瓴等多家機構,以及包括君聯資本在內的部分老股東跟投。
在這場“百模大战”中,智譜AI無疑是被寄予衆望的一個。
然而,值得注意的是,就目前來看智譜AI能商用的ChatGLM3只有6B版本,對標GPT 3.5商用高參數版本仍有距離。尤其是在阿裏正式开源72B參數模型之後,智譜亦會面臨不小的壓力。
一些值得思考的問題是,智譜AI的優勢究竟是什么?未來發展的想象力在哪?以及其目前面臨的一些問題下,如何解題?挖掘其頻繁融資的另一面。
一、百億估值,憑什么?
從3月份开源第一代到現在7個月之後迭代到第三代,智譜AI發展十分迅猛。
在最新發布第三代基礎大語言模型ChatGLM3系列。官方表示該模型的性能較前一代大幅提升,是10B以下最強基礎大模型。
具體來看,按照MMLU排序,在所有規模的模型對比下,ChatGLM3-6B得分排序第9,但是前面8個模型最小的也是140億參數規模的Qwen-14B,如果按照GSM8K排序,ChatGLM3-6B-Base甚至排到第三,超過了GPT-3.5的57.1分。
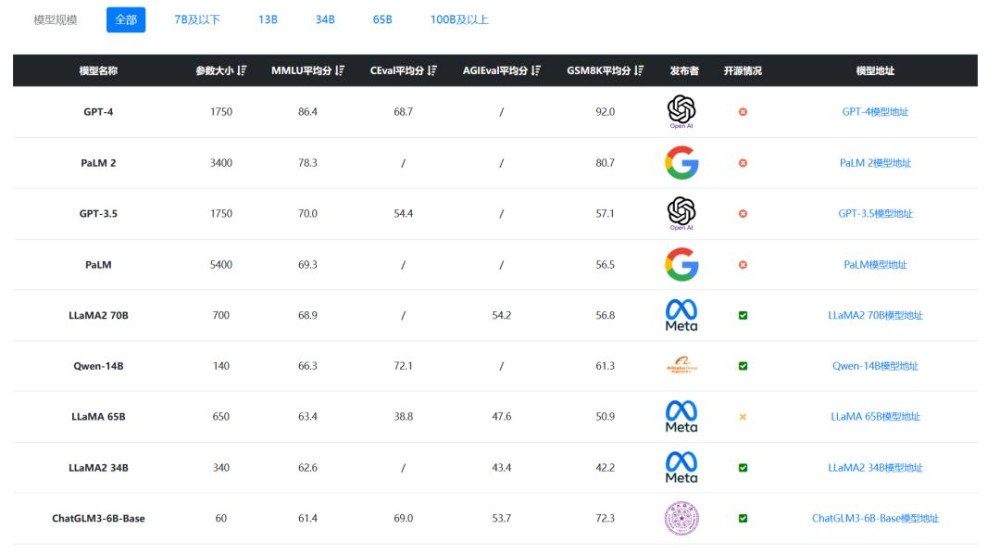
可見,智譜AI趕超OpenAI不是空穴來風。
想要深入挖掘智譜AI的優勢,就不得不從國產大模型發展、落地的諸多難題講起。
一項新技術的價值幾何,商業化變現是最直接的檢驗方式。在國內一衆大模型廠商中,可以說大部分都還處於講技術、講發展的階段。對於商業化落地,基本處於一個探索階段。
而智譜AI早在創業前就已經服務B端,目前客戶已經超過1000家。可見其產業落地、商業化變現更有前景。
大模型落地又一個極爲重要的前提,便是數據安全。智譜AI 作爲國內唯一全內資、國產自研的大模型企業,它推出的 GLM 國產芯片適配計劃,面對不同類型的用戶不同類型的芯片提供不同等級的認證和測試,可真正實現安全可控。
這個優勢,從某種意義上可以完全俘獲央國企以及有特殊要求的大型企業。“國企央企,想做模型能力或者接入,智譜都是無論如何都是繞不开的選項。”某業內人士對產業家說。
此外,還有人的因素。在一級市場,早期投資就是投人,這一點在所有初創公司都適用。智譜AI的“前身”是清華KEG(知識工程實驗室),CEO張鵬本科畢業於清華大學計算機系博士;董事長劉德兵師從高文院士,曾任清華數據科學研究院科技大數據研究中心副主任;總裁王紹蘭爲清華創新領軍博士。
總體來看,智譜AI具備了落地經驗、人才完備、資金充足、技術到位等天時地利人和的條件。這種條件也使其在一種大模型廠商的賽跑中,率先脫穎而出。然而這只是表象。
路徑選擇上,不同於比較主流的 GPT,智譜 AI 採用的是 GLM,智譜AI提出了全新的GLM(通用語言模型)路徑。訓練效率比GPT更高,也能理解更復雜的場景。
在大模型落地層面,其沒有選擇推出行業大模型,而是說服行業客戶在通用大模型基座上做微調。在CEO張鵬看來,只有一定規模的通用大模型,才能實現類人的認知能力湧現。
此外,爲了提高大語言模型作爲AI Agent的表現和能力,清華大學和智譜AI推出了一種新的方案——AgentTuning,可以將有效增強开源大語言模型作爲AI Agent的能力。
智譜AI獲得資本和互聯網巨頭青睞的原因,不僅僅是因爲其技術,更在於其在路徑、模式、策略上的選擇,以及對自身大模型底層定位的明確。
用CEO張鵬的話來說,智譜AI的全线產品與 OpenAI 的產品已經做到了對標。
那么,就當下而言,除了被驗證的路徑和模型,智譜AI有沒有其它待完成的拼圖?
二、商業化、AI开源和避不开的資金
通過智譜AI商用授權的模型版本來看。目前僅限於6B,即60億參數。而從OpenAI开源模型來看,GPT-3 爲具有 1750 億參數的自回歸語言模型,OpenAI 已將其部分开源;GPT-3.5具有 1375 億參數,同樣有一部分已經被开源。
更值得注意的是,阿裏最近也开源了72B參數的模型。要知道目前的大模型應用,多處於大力出奇跡階段,更大的參數,意味着更好的落地效果。
可以發現,雖然智譜AI作爲國內第一开源大模型,有着較強的技術架構,但對標OpenAI以及國內大廠商業授權的模型規模上來看仍有一些距離。且隨着阿裏更大參數的开源模型發布,智譜AI在6B模型上的優勢或將變弱。
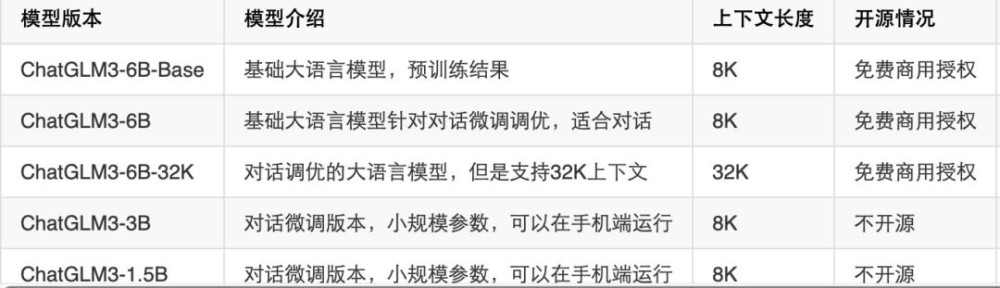
而想要補齊這個短板,則需要大量的資金支持。
“如果智譜AI背後也能有一個像微軟這樣的金主,會十分亮眼。”某業內人士對產業家直言。
事實上,隨着智譜AI大模型能力持續提升,訓練參數自然也需要提升,對算力、存儲等需求也會增加。這在資金上以及資源調度上將會是一個巨大的難題。
粗略來看,私有化部署一個130b規模的大模型,一年費用接近4000萬,但這4000萬花出去能帶來多少價值,卻是一個未知數。在AI大模型部署方面,目前小企業付費能力弱,大企業要么自研,要么還處於了解、認知階段,商業化落地較難。
資金從哪來,是一個亟待解決的問題。
“智譜开源6b模型有一部分原因是爲了告訴市場,我這有更好的,看你愿不愿意花錢。”某業內人士對產業家說。對於智譜AI而言,开源6B展示實力,以及拉投資是較爲明顯的解法。
而另一個解法,則是擴大“朋友圈”。
衆所周知,互聯網巨頭在計算、存儲能力以及數據資源方面有着較大地優勢。而對於智譜AI而言,這些都需要其投入大量的資金去搭建。與巨頭的合作,可以很大程度上降低研發成本、提高研發效率。此外,智譜 AI 還可以借助雲廠商的市場地位和渠道,推廣自身的人工智能技術和服務。
另一邊,由於大模型需要部署在雲上,按照數據運行付費,越多的用戶使用模型和資源,對雲算力的需求量就越大,雲廠家的收入也就隨之增加。且雲廠商則可以借助智譜 AI 的技術實力,提升自身在人工智能領域的競爭力。
總體而言,對於雲廠商而言,可以拉動自身雲收入;對於大模型廠商,可以減少基礎設施的投入,可謂一石二鳥。
目前,智譜AI已經與阿裏、騰訊、美團等企業展开一系列合作。
從這點來看,智譜AI之所以“衆星捧月”,更在於其开放、融合的商業模式,在國內大模型競爭愈發競爭激烈、難落地的當下,智譜AI的模式更能推動大模型的落地以及加速大模型生態的發展。
智譜AI的這種模式,也爲其自身以及國內大模型未來的發展業態帶來了一些新的想象力和思考。
三、國產大模型未來在哪裏?
“模型能开除一半人,企業才會考慮用。”在與某行業人士的溝通中,其表達了對當下大模型商業化路途之遠的觀點。
客觀來看,目前國內大模型的業態,屬於百花齊放,已經开始出現同質化的特徵。這不僅會造成算力等基礎設施的非合理化使用,更或造成非良性的競爭。
目前,大模型落地進程較慢,加上仍舊如春筍般往外冒的大模型創業熱潮,必將產生大量泡沫。對於國內大模型廠商而言,以生態之力,各司其職推動大模型商業化落地,無疑是一個最佳選項。
事實上,目前國內外主流大模型在算法層面尚不存在代際差,但是在算力和數據方面存有差距。
通過大力支持通用領域國內頭部科技企業研發自主可控的國產大模型,同時鼓勵各垂直領域在大模型基礎上,利用开源工具構建規範可控的自主工具鏈,既探索“大而強”的通用模型,又研發“小而美”的垂直行業模型,就可以逐漸構建基礎大模型和專業小模型交互共生、迭代進化的良好生態。
在大模型生態愈發完善下,也將帶來一些新的變化。
首先是模型質量的提升。隨着技術的進步和資源的投入,未來的大模型將具有更高的精度、更強的理解能力和更廣泛的適用性。這不僅意味着它們能夠更好地理解自然語言,還能夠進行更多的復雜任務,如翻譯、推理、創作等。
其次是更豐富的應用領域。除了傳統的文本處理之外,大模型也將在語音識別、圖像生成、視頻理解和推薦系統等領域發揮更大的作用。這意味着我們可以在更多的場景中享受到AI帶來的便利。
此外,未來大模型將更加定制化,能夠更好地滿足用戶的個性化需求。用戶可以根據自己的實際需求選擇合適的模型,並進行定制化配置。這將使用戶能夠更加靈活地利用大模型來解決自己的問題。
在大模型生態中,數據將變得更加共享和开放。機構和企業之間可能會加強合作,共享優質數據資源,從而促進大模型技術的發展。這種合作將爲大模型的开發和應用提供更加廣闊的空間。
新的科技浪潮襲來,就必然需要一些企業承擔一些使命。着眼當下,技術架構是大模型走出來的重要標准;遙看未來,想要站在AI大模型浪潮之上,生態構建力愈發重要。
原文標題 : 百億估值背後,起底智譜AI
標題:百億估值背後,起底智譜AI
地址:https://www.utechfun.com/post/306046.html