作者:一號
GPT-4最強的對手出現了。

北京時間12月7日凌晨,谷歌CEO“劈柴”突然發布重磅AI殺手鐗——Gemini。就在前幾天,還有消息說Gemini要推遲一個月才上线,結果現在這么突然地發布,着實讓AI圈料不到。以谷歌以往的實力,不用想,這又是AI界的一個“不眠之夜”。
在去年ChatGPT發布不到兩周,谷歌就拉響了「警報」來應战,好不容易搞出來的Bard,在首次亮相的時候卻出現了失誤,讓谷歌市值一夜蒸發了1000億美元。
而且,GPT(Generative Pre-training Transformer)還是基於Transformer开發的,而這個Transformer模型最早還是谷歌提出來,要想谷歌心甘情愿地服輸,可不是那么容易。
果然,這一年的時間裏,關於Gemini的消息就層出不窮,有的說谷歌大腦和DeepMind部門合並,幾乎耗盡谷歌內部算力資源,就是爲了背水一战,和OpenAI決战。
不過前段時間,OpenAI的發布會把AI界炸了一圈,還上演了一出“宮鬥劇”,甚至還傳出讓人浮想聯翩的Q*,谷歌都沒一點新消息,差點就讓人以爲AI圈的王者已定。
就在一個月之前,英偉達科學家Jim Fan就曾說過,“人們對谷歌Gemini的期望高得離譜!谷歌要想重奪當年AlphaGo的輝煌,Gemini不僅要100%達到GPT-4的能力,還要在成本或者速度上比GPT-4更好。”

生來就是全才
還好,從Gemini公布的演示視頻來看,它沒讓人失望。
“Gemini,從第一天起就是多模態大模型——跨越文本、圖像、視頻、音頻和代碼的無縫推理。”這是谷歌官網上,介紹Gemini的第一句話。
與ChatGPT通過升級迭代,逐步加上視覺、音頻等多模態能力,形成“合體金剛”的路徑不同,Gemini生來就是一位全才。它從第一天起就被設計成原生多模態結構,文本、圖像、音視頻能力從最开始就一起訓練,從這一點上來看,Gemini的學習更像人類。這就意味着,Gemini可以無縫調動多模態能力,抽象和理解、操作和組合不同類型的信息。
舉個例子,如果你同時上傳一張圖片給ChatGPT和Gemini,那么ChatGPT的處理將會是這樣的,先借助GPT-4V認出來圖裏是什么,然後轉成文本交給GPT去進行語義理解,然後再作回答;而Gemini則可以基於圖像直接進行理解並回應,不用進行不同模型之間的調動。因此,在實操過程中,Gemini可以減少信息的丟失,回應也可以更加迅速和絲滑。
這從谷歌給到的演示視頻中便可以看出:

演示者一邊畫畫,Gemini就可以一邊辨認,並且用自然、流利的語音和演示者對話,在演示者拿出藍色的玩具鴨實物後,它還會幽默的回應:“看起來藍色的鴨子比我想象中更常見。”
很顯然,這樣的體驗更接近漫威中的“賈維斯”——一個高級人工智能,能與人類自如地進行交互。
而這樣的體驗,離不开Gemini的原生多模態架構。
Gemini VS GPT-4
除了擁有令人驚嘆的原生多模態能力,在性能上,Gemini也是相當強悍。
按照尺寸的不同,Gemini共有“中杯”、“大杯”還有“超大杯”三種,即Ultra、Pro和Nano三個不同的版本。它們在性能和適配任務上的側重點各有不同。
·Gemini Ultra —規模最大且功能最強大的模型,適用於高度復雜的任務,預計2024年初推出。
·Gemini Pro — 適用於各種任務的最佳模型,已經被用在了谷歌聊天機器人Bard的升級版上。
·Gemini Nano — 可以在端端側設備上運行的高效模型,已經可以跑在谷歌Pixel 8 Pro手機上了。
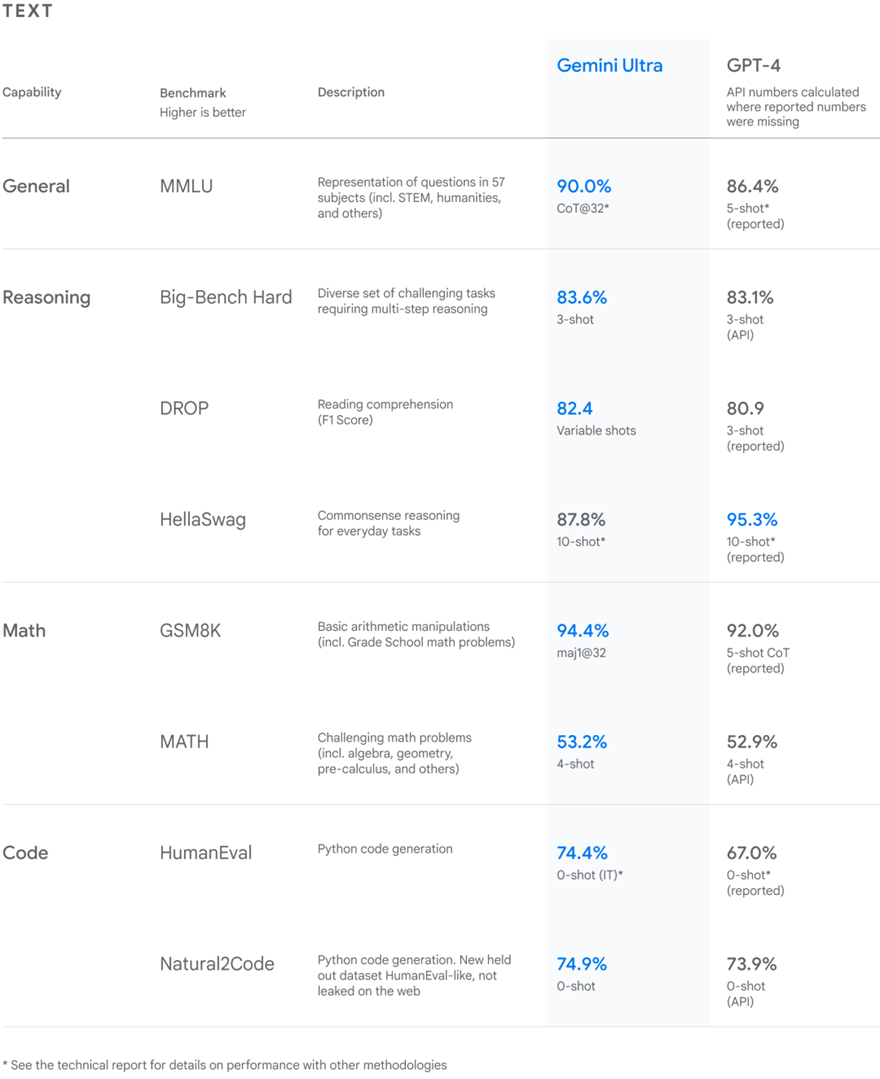
根據谷歌給到的資料,從自然圖像、音頻和視頻理解,再到數學推理,Gemini Ultra的性能在32個常見的大語言模型(LLM)研究和开發的學術基准測試中,拿下了30個SOTA。
其中,它在通用、推理、數學和編程等大方向的成績如下:
更讓人驚奇的是,在MMLU(大規模多任務語言理解)任務上,Gemini Ultra的得分達到了90.0%,超越了人類專家89.8%的成績,首次達到了超越人類專家水平。
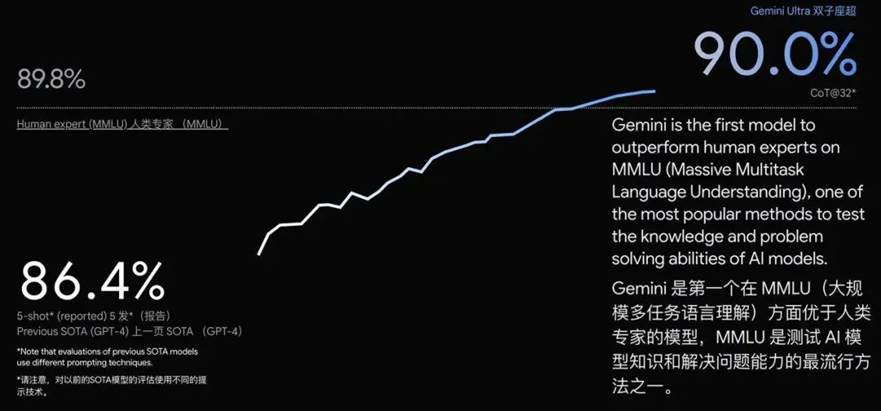
MMLU測試包括數學、物理、歷史、法律、醫學等57個學科,主要是用來考察大語言模型世界知識和解決問題的能力,而在這些學科中的每一個,Gemini都達到了甚至超過了行業專家的水准。
在圖像基准測試中,Gemini Ultra在不使用OCR(對象字符識別)來提取圖像文本進行下一步處理的情況下,表現優於GPT-4V。
各種測試都表明,Gemini在多模態處理上表現出了強大的能力,並且在更復雜的推理上也有很大的潛力。
實際能力被質疑
然而,在模型發布後不久,就有人在谷歌給到的60頁技術報告中發現了一些“小技巧”。
在MMLU測試中,Gemini的結果下面用灰色小字標注着CoT@32,這表示,這個結果是使用了思維練提示技巧,嘗試了32次後選出來的最好結果,而對比GPT-4,則是無提示詞技巧,只嘗試了5次的結果,這測試結果,變量確實控制得不是很好。

而且在顯示超越人類專家的示意圖裏,比例尺上也有問題,讓人以爲超越了人類專家很多,但實際上並沒有相差多少。
HuggingFace的技術主管Philipp Schmind“修復”了這張圖,表示實際上應該是這樣:

並且,在谷歌給到的一篇解釋多模態交互過程的博客中,似乎表明了演示視頻裏,Gemini實時互動並不是真的,而是使用了靜態圖片,通過多段提示詞拼湊,最後再剪輯視頻,才達到了演示視頻裏的效果。
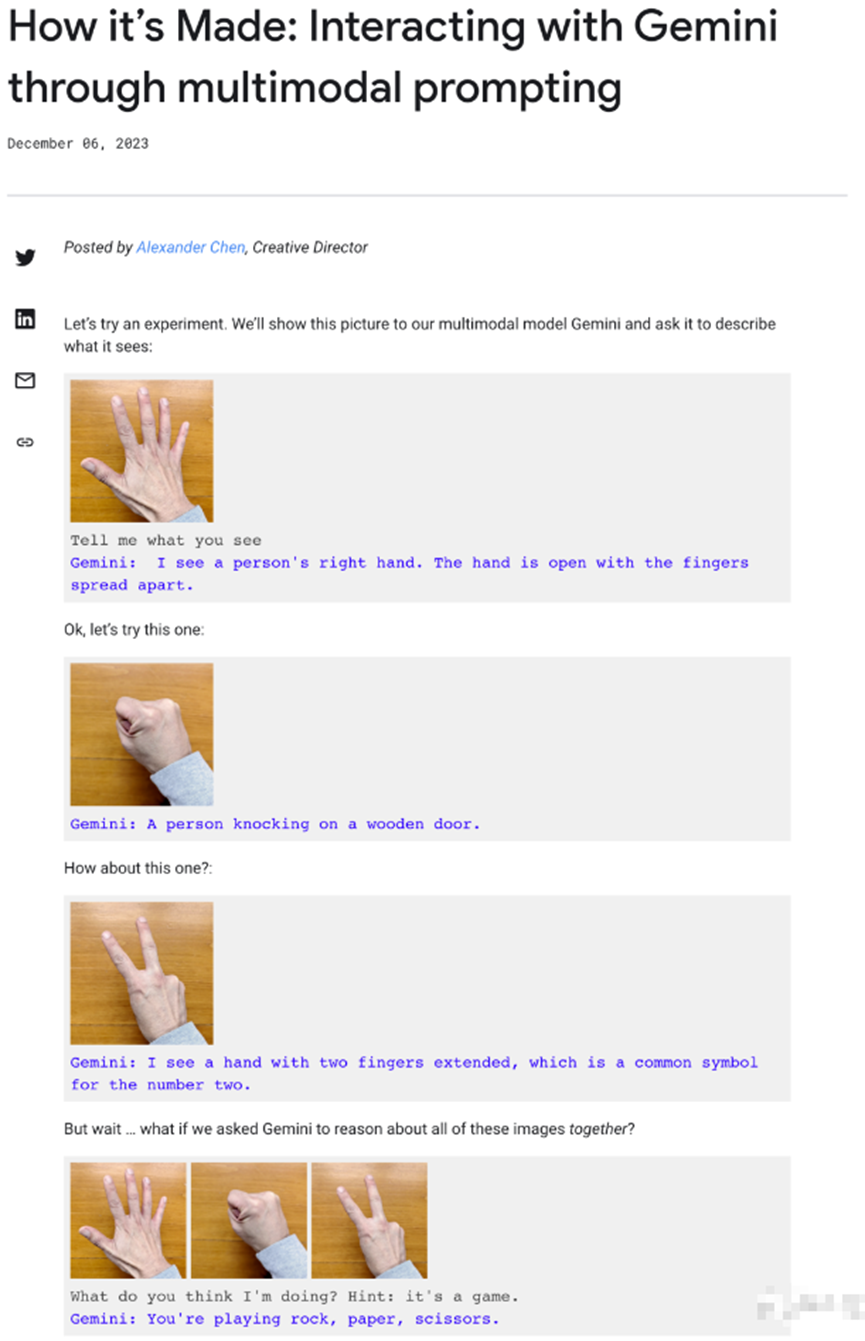
不管谷歌是不是有意使用“障眼法”,Gemini的發布無疑給看似穩定的AI界帶來了一些“動蕩”。
並且,谷歌還宣布推出了迄今爲止最強大、最高效、最可擴展的TPU系統:Cloud TPU v5p,Gemini正式在此基礎上訓練的,這意味着谷歌將有能力拜托英偉達的算力限制,也算給了AI芯片市場帶來了一些變化。

大模型的多模態探索
隨着ChatGPT通過升級迭代,擁有了多模態能力,以及Gemini所展現出來的原生多模態能力,我們可以清晰地感受到,AI大模型浪潮已經進入了一個全新的階段,即從大語言模型轉向多模態模型。後者將更符合人類和世界交互最自然的方式:用眼睛看,用耳朵聽,用嘴巴說,用文字記錄與決策。
多模態領域的技術探索,與互聯網媒介形式的變化也十分吻合,即從文字媒體,再到
音視頻媒體。如今,隨着抖音以及TikTok等短視頻平台的興起,視頻已經成爲了我們這個信息時代的主流。
根據思科的年度互聯網報告,視頻已經佔據了互聯網超過80%的流量。
很明顯,如果一個AI大模型不具備識別圖像以及音視頻的能力,那么其訓練數據將會跟不上信息迭代的速度,其能力也將大打折扣。
現如今,在多模態模型道路的探索上,除了GPT,Gemini也加入了進來,不知道未來Meta的Llama還有馬斯克的Grok等等,是否也將加入角逐?
原文標題 : 新火種AI|谷歌深夜發布復仇神器Gemini,原生多模態碾壓GPT-4?
標題:谷歌深夜發布復仇神器Gemini,原生多模態碾壓GPT-4?
地址:https://www.utechfun.com/post/301208.html