作者:一號
編輯:美美

圖片來源:由無界 AI生成
從手機到大模型,國內產品爲啥都這么熱衷跑分?
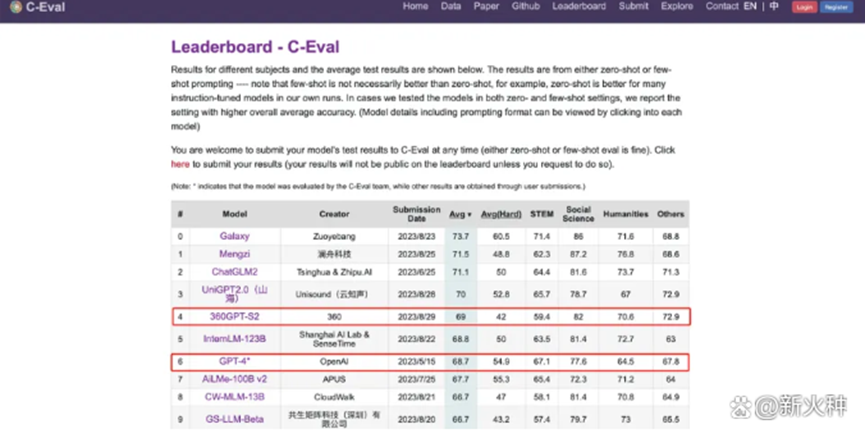
IDCAI大模型技術能力評估,12項指標,7項滿分,文心大模型3.5“大滿貫”;360智腦在SuperCLUE評測中多項能力位列國產大模型第一,某些方面甚至跑贏了GPT-4;誇克大模型在C-Eval和CMMLU兩大權威評測榜單中名列第一,顯示出其在寫作、考試等部分場景中甚至優於GPT-4......

今年以來,國產AI大模型發展趨勢之迅猛,不得不讓人感慨。截至目前,國產大模型數量已經超過了200個,而且,這些大模型紛紛表現不俗,從百度文心一言到阿裏巴巴的誇克大模型,國產AI在各類評測榜單上的表現引人注目。有人對此評價,“跑分沒輸過,體驗沒贏過”。
這種似曾相識的“跑分”現象,不禁讓人想到手機市場裏類似的做法。這種在評測中名列前茅、表現出色,但實際用戶體驗一言難盡的情況,究竟意味着什么?
爲何跑分與體驗不符?
回顧手機市場,“跑分沒輸過,體驗沒贏過”這句話最开始就是從手機圈中興起的,各大廠商通過不斷疊加定語,來讓自己獲得第一;還有的手機會自動識別跑分軟件,針對性地开啓性能模式,讓自己的跑分數據好看些,從而實現“作弊”。用戶买到跑分高的手機後,實際體驗並不是那么回事。
而在AI大模型領域,評估標准則相對公平,並且是同意的,其中包括MMLU(用於衡量多任務語言理解能力)、Big-Bench(用於量化和外推LLMs的能力),以及AGIEval(用於評估人類級任務的能力)。

目前國內廠商經常飲用的榜單就是SuperCLUE、CMMLU和C-Eval,其中C-Eval是由清華大學、上海交通大學和愛丁堡大學合作構建的綜合性考試評測集,CMMLU則是MBZUAI、上海交通大學、微軟亞洲研究院共同推出,至於SuperCLUE,則是由各大高校的AI專業人士設立的。
盡管大模型的評測標准相對公平,但其仍有一定的局限性,實際的測評之中總會出現問題,其中一個最大的問題就是“考題泄露”。
大模型評測的一個主要方法就是做題。爲了讓評測相對透明公开,避免暗箱操作,評測機構通常會將評測的方法、標准甚至是題庫對外公开。例如C-Eval榜單在上线之初就有13948道題目,由於題庫有限,並且更新頻率不是特別高,這就給了一些大模型刷題“鑽空子”的機會。
我們都知道,如果在考試之前知道會考哪些題目,那考生完全可以做針對性的學習,大模型也一樣,並且大模型最擅長的就是記憶。在評測之前,把題庫直接加入大模型的訓練集,訓練之後的大模型就能在評測中表現得比實際能力更好,甚至跑出一些誇張的成績,例如1.3B的模型在某些任務上超越了10倍體量的大模型。
那么這樣的評測結果,跟實際體驗一定會很不相符。
爲何熱衷於跑分?
無論是國產手機廠商還是AI大模型公司,他們對跑分的熱衷,本質上是一種營銷策略。跑分成績容易被量化、對比,因此成爲了向公衆展示技術實力的便捷手段。這種做法在短期內可能會吸引消費者和投資者的注意,但它也可能引起誤導,使人們過分關注理論性能,而忽視了實際應用中的體驗和效能。
這種營銷策略的問題在於,它可能導致公司本末倒置,過分投入於提高特定測試的分數,而非真正的技術創新。在手機行業,這可能意味着優化設備性能以提升特定跑分軟件的測試成績;在AI領域,則可能表現爲優化模型以應對評測榜單的特定題目。這種做法雖然能在短期內提高產品在評測榜單上的排名,但卻可能忽視了產品在真實使用環境中的性能和用戶體驗。
這種以跑分爲核心的營銷策略需要被重新審視。盡管高分成績在營銷中具有吸引力,但它們並不總是反映產品的真實價值。對於消費者而言,理論上的高性能與日常使用中的實際體驗之間往往存在差距。因此,無論是手機行業還是AI領域,公衆和行業都應該更加關注產品在真實世界中的表現。
要放棄跑分嗎?
從隋唐的科舉到今天的高考,從國內的四六級到國外的托福雅思,考試在時間和空間的維度上,都是一種相對公平的衡量機制。因此,大模型評測作爲大模型的“考試”,同樣不能被輕易拋棄。
倘若評測相對准確、靠譜、權威,那么對於所有的大模型公司來說都是好事。研發者可以通過評測結果了解自家大模型的優缺點,查漏補缺,找到正確的方向鑽研算法、提升技術、加強訓練,不斷攻克,進行優化迭代,從而讓產品更具有競爭力。
對於AI大模型开發者而言,榜單的排名不應該成爲最終目的,真正的挑战在於如何將先進的技術轉化爲實際應用中的有效工具,這不僅僅是一場分數的競賽,更是對技術創新和實用性的追求。我們期待一個更加全面和科學的評測體系的出現,這不僅能正確評估AI模型的實際能力,還能促進整個行業向着更加健康、理性的方向發展。
原文標題 : 新火種AI | 跑分沒輸過,體驗沒贏過,大模型刷分何時休?
標題:跑分沒輸過,體驗沒贏過,大模型刷分何時休?
地址:https://www.utechfun.com/post/299981.html