
ChatGPT 目前最多可以提取數千個單字,更大的 AI 模型如 Claude 2 能夠處理更多資料。由於訓練和運算 AI 模型的 GPU 記憶體限制,現階段無法處理大量資料輸入,然而 Google DeepMind 研究人員已經找到新方法克服問題。
Google DeepMind 一名研究人員 Hao Liu 以及新創公司 Databricks 技術長 Matei Zaharia、加州大學柏克萊分校教授 Pieter Abbeel 近日發表論文《》,揭曉一種幫助 AI 模型輸入更多資料的新方法,名為「Ring Attention」可消除 AI 模型運算的記憶體瓶頸,將數百萬個單字輸入 AI 模型進行運算。
在討論 AI 聊天機器人及其背後大型語言模型運算前,可先了解 token 以及輸入文字提示的 context window。token 是 AI 模型處理和產生文字的基本單位,可以代表一個單字或一個單字的一部分,通常 AI 模型開發商會透露支援多少 token 的上下文長度。context window 則是人們將問題、文字提示輸入 AI 模型的空間,分析處理後給予文字、表格等內容回覆。
舉例來說,OpenAI GPT-3.5 模型的上下文長度為 16K token, 模型則是 32K token。新創公司 的聊天機器人 Claude 2,支援多達 100K token 上下文長度,相當於大約 75,000 個單字,已經是一本書的文字量。
New paper w/ on transformers with large context size.
We propose RingAttention, which allows training sequences that are device count times longer than those of prior state-of-the-arts, without attention approximations or incurring additional overhead.
— Hao Liu (@haoliuhl)
▲ 加州大學柏克萊分校博士生、同時兼任 Google DeepMind 研究人員的 Hao Liu,提出 Ring Attention 新技術。
Hao Liu 提出的概念考量到,現代 AI 模型處理資料的方式需要 GPU 儲存內部輸出,資料傳遞到下一個 GPU 計算在重新運算,這需要大量記憶體,但實際上 GPU 記憶體不足以應付,限制了 AI 模型能夠處理的資料量,無論 GPU 效能有多高,都存在這種記憶體瓶頸。
然而 Ring Attention 形成一種環狀 GPU,將處理位元傳遞到下一個 GPU,同時從其他鄰近 GPU 接收類似區塊,以此不斷重複。「這有效消除各個裝置施加的記憶體限制」,論文對此解釋。
這代表人們應該能將數百萬個單字輸入 AI 模型的 context window,不再只有數萬個單字。理論上,未來許多書籍甚至許多影片可以一次輸入 context window,由 AI 模型加以分析。
按照目前做法,如果有一個 16K token 的 context window,以及依靠 256 個 NVIDIA A100 GPU 的 130B 參數 AI 模型,上下文長度僅限 16K token。然而透過 Ring Attention 技術,相同前提可以處理多達 4,000K token。
Hao Liu 提出的想法是原始 Transformer 架構翻版,Transformer 模型自 2017 年推出後徹底改變 AI 發展,成為 ChatGPT 以及近年來所有 AI 模型的基礎,例如 GPT-4、 或者 Google 計劃推出的 。
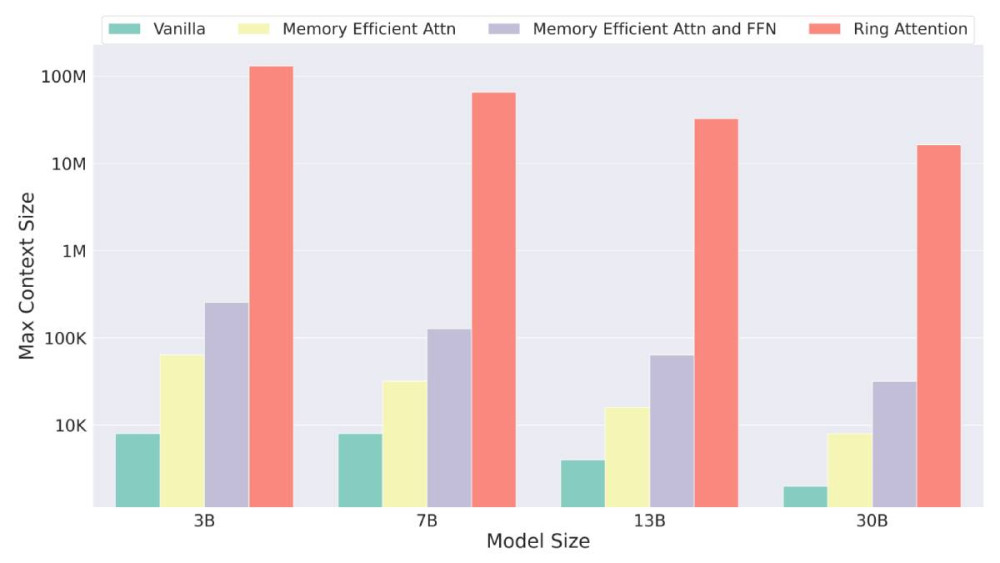
▲ Ring Attention 技術測試結果。(Source:)
與此同時值得思考的是,透過 Ring Attention 技術是否可以運用更少 GPU 處理更多 AI 工作負載,是否也意味著對 NVIDIA GPU 需求能夠進一步減緩?「Ring Attention 不會阻礙 GPU 銷售」,Hao Liu 否認這樣的論點,並認為科技公司和開發商運用新技術,對於發展大型語言模型能有更大膽的想像。
(首圖來源:)

標題:Ring Attention 技術克服記憶體瓶頸,AI 模型可處理數百萬字資料量
地址:https://www.utechfun.com/post/282067.html