
1989年,卡內基梅隆大學接到了美國軍方的一個研究課題,內容是當時看起來不可思議的自動駕駛。
爲此,研究人員給一輛翻新的軍用急救車,裝上了一個看起來像探照燈的碩大攝像頭,還配備了一台冰箱大小的處理器和一部5000W的發電機。
盡管設備簡陋、數據粗糙,比如據媒體報道當時車頂的攝像頭只能輸入30×32像素網格,但借助开創性的神經網絡,這輛名爲ALVINN的自動駕駛汽車最高速度能達到88km/h。

ALVINN被譽爲自動駕駛領域一個裏程碑項目。其最深刻的影響,正是用神經網絡替代人工代碼,成爲後來自動駕駛技術發展的一座燈塔。
此後數十年,自動駕駛技術沿着ALVINN的方向飛速發展,直到chatGPT問世,大模型走上舞台,成爲改變自動駕駛最大的一個變量。
在車端,大模型已經作用於自動駕駛的感知和預測環節,正在向決策層滲透;在雲端,大模型爲L3及以上自動駕駛落地鋪平了道路;甚至,大模型還將加速城市NOA落地。
而全球的下遊企業中,特斯拉毫無疑問是跑在最前面的少數。
今年8月特斯拉端到端AI自動駕駛系統FSD Beta V12版本的公开亮相,據稱可以完全依靠車載攝像頭和神經網絡,識別道路和交通情況並做出相應的決策。
這種端到端模型的感知決策一體化,讓自動駕駛直接從一端輸入圖像數據,一端輸出操作控制,更接近人類的真實駕駛。
但車企們努力接近端到端模型時才發現,想要超越必須先跟隨。
1
算法優先
讓大模型上車,特斯拉絕對是最激進的一個。
早在2015年,特斯拉就开始布局自動駕駛軟硬件自研,2016-2019年陸續實現了算法和芯片自研。隨後在2020年,特斯拉自動駕駛又迎來大規模升級:
不僅用FSD Beta替換了Mobileye的Autopilot 3.0,還將算法由原來的2D+CNN升級爲BEV+Transform。
Transformer就是GPT中的T,是一種深度學習神經網絡,優勢是可實現全局理解的特徵提取,增強模型穩定性和泛化能力。
BEV全稱是Bird’s Eye View(鳥瞰視角),是一種將三維環境信息投影到二維平面的方法,以俯視視角展示環境當中的物體和地形。
與傳統小模型相比,BEV+Transformer對智能駕駛的感知和泛化能力進行了提升,有助於緩解智能駕駛的長尾問題:
1)感知能力:BEV統一視角,將激光雷達、雷達和相機等多模態數據融合至同一平面上,可以提供全局視角並消除數據之間的遮擋和重疊問題,提高物體檢測和跟蹤的精度 ;
2)泛化能力:Transformer模型通過自注意力機制,可實現全局理解的特徵提取,有利於尋找事物本身的內在關系,使智能駕駛學會總結歸納而不是機械式學習。
2022年特斯拉又在算法中引入時序網絡,並將BEV升級爲佔用網絡(OccupancyNetwork),有效解決了從三維到二維過程中的信息損失問題。
從感知算法的推進來看,行業總體2022年及之前的的商業化應用主要爲2D+CNN算法。隨着ChatGPT等AI大模型的興起,算法已經升級至BEV+Transformer。
時間上特斯拉有領先優勢(2020年),國內小鵬、華爲、理想等均是今年才切換至BEV+Transformer。
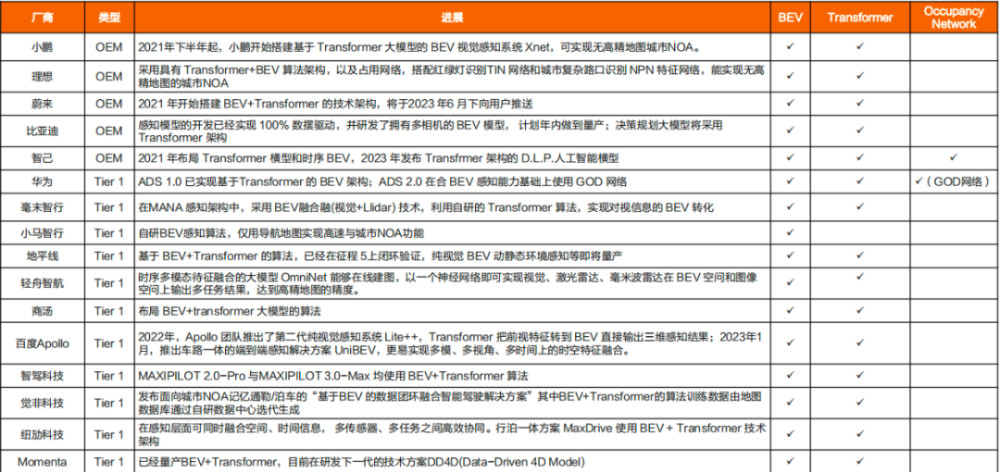
但不論是特斯拉還是國內主機廠,BEV+Transformer都仍只應用於感知端。
雖然學術界以最終規劃爲目標,提出感知決策一體化的智能駕駛通用大模型UniAD+全棧Transformer模型,不過受限於算法復雜性+大算力要求,目標落地尚無准確時間表。
2
算力競賽
2016年,因輔助駕駛致死事故和Mobileye分道揚鑣的特斯拉,找到英偉達定制了算力爲24TOPS的計算平台 Drive PX2,由此开啓了車企瘋狂追求算力的神奇序幕。
繼Drive PX2之後,英偉達在6年時間內發布了三代智能駕駛芯片,從Xavier、Orin再到Thor,算力從30TOPS一躍升到2000TOPS,足足增長了83倍,比摩爾定律還要快。
上遊如此“喪心病狂”的堆算力,歸根結底還是因爲下遊有人买單。
一方面,隨着智能汽車上的傳感器規格和數量提升,帶來數據層面的暴漲。
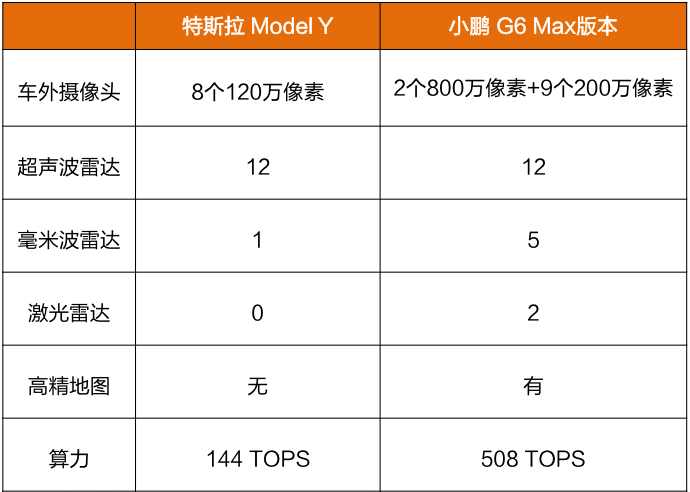
以特斯拉Model Y和小鵬 G6 Max爲例,後者因配置了更多傳感器,所需算力達到了前者的3.5倍。
當一輛自動駕駛車輛每天可以產生數TB,甚至數十TB數據,數據處理能力即爲自動駕駛技術驗證的關鍵點之一。
另一方面,“大模型化”也讓智能駕駛算法的芯片算力愈發喫緊。
上汽人工智能實驗室曾測試,實現L2級自動駕駛只需10Tops以下的算力,即便是實現L4級自動駕駛也只需100Tops左右的算力。而下遊企業暴漲的算力需求,實際也另有原因。
一個是雲端算力。
自動駕駛系統前期和後期开發依賴大量環境數據輸入,對算法進行訓練與驗證,同時仿真測試中場景搭建與渲染也需要高算力支持。
而且特斯拉引領的神經網絡Transformer又是一個資源消耗大戶,毫末智行數據顯示,Transformer在訓練端所需算力是CNN的100倍。
如此一來,下遊企業想要獲得算力要么自建智算中心(特斯拉),要么與雲服務商合作,最不濟的全部外採,包括算法、計算資源、應用服務等。
國內主流主機廠/自動駕駛廠商的智算中心雖然都已上线,但因自建成本較高,國內主流自動駕駛廠商大多採取合作模式/採購模式,比如吉利星睿、小鵬扶搖都是阿裏雲,毫末和理想則是火山引擎。但從長期成本優勢來看,仍具備較高的自建傾向。
還有一個則是NOA。
現實中主機廠具備城市NOA高階智能駕駛功能的車型,算力大多在200-500TOPS左右。
但NOA從高速道路向城市道路拓展(高速道路-城市快速路-城市主幹道-城市次幹道-城市支路)的過程中,人流越密集(每天僅25%的人出行途徑高速,而城市道路則是100%)的道路環境復雜度更高,物體識別、感知融合和系統決策的算力需求就越高。
沐曦首席產品官孫國梁就指出,在車端部署大模型並能實現既定任務,算力至少要達到300~500TOPS。模型優化或可降低算力要求,但考慮到未來場景復雜度和數據量增加,以及視覺感知佔比增加(相對基於規則),車端算力或將翻倍達800TOPS以上。
3
感知升級
光大證券有一個判斷,認爲L2/L2+級向L3級高階智能駕駛邁進的三大要素重要性排序分別是數據>算法>硬件,而後階段向更高階智能駕駛邁進的排序或爲硬件>=算法>數據。
理論依據在於,實現L3級智能駕駛的關鍵在於全面感知,主要依賴海量+長尾場景數據驅動算法升級優化;其中,無圖場景覆蓋還需低线城市數據(vs.當前車載算力已基本滿足L3-L4級需求)。
而當前階段,海量+長尾場景數據的獲取就要依靠車載傳感器(攝像頭)的大幅升級。
根據Yole報告,自動駕駛L1-L3所需的攝像頭數量翻倍增長,比如L1-L2級僅需前後兩顆攝像頭,到L3就要20顆。
而實際上,主機廠爲後續OTA升級預留冗余,單車攝像頭配置遠超本級所需的攝像頭數量,如特斯拉Model 3搭載9顆,蔚來、小鵬、理想車型達到10-13顆。
此外,因大模型對感知數據的精細化要求,高分辨率圖像數據可以作爲深度學習模型中更新和優化其架構的參數的數據源,尤其是前視攝像頭,需要解決的場景最多,目標識別任務最復雜,比如遠距離小目標識別、近距離目標切入識別。
爲了對更遠距離的目標進行識別和監測,車載攝像頭就要向800萬像素或更高升級。典型如百度Apollo,就已聯合索尼、聯創與黑芝麻智能,全球首創了超1500萬高像素車載攝像頭模組。
而在提高感知能力這件事上,還有兩個所有車企都想繞开的坎,高精地圖和激光雷達。
高精度地圖作爲先驗信息,可以給自動駕駛提供大量的安全冗余,在數據和算法尚未成熟之前,主機廠依賴程度較高。而脫圖的原因也比較好理解:
1)高精地圖存在更新周期長、成本高、圖商資格收緊等弊端,限制了高階自動駕駛大規模商業化的可能性。
2)構建數據閉環,形成對算法模型的迭代升級反哺車端。
至於如何脫圖,特斯拉的辦法是引入車道线網絡及新的數據標注方法,國內自動駕駛頭部公司則採取車端實時建圖方案,通過安裝在車輛上的相機等傳感器來構建車輛行駛過程中周圍的環境地圖。
目前小鵬、華爲等頭部主機廠發布無高精地圖的高階智能駕駛方案,並定下量產時間表,華爲、毫末、元戎啓行等自動駕駛公司也加入其中,自動駕駛算法“重感知,輕地圖”趨勢明確。
激光雷達則是因爲成本問題。
激光雷達在距離和空間信息方面具有精度優勢,搭載激光雷達的多傳感器融合感知方案可通過互補達到全環境感知能力,爲高級別自動駕駛提供安全冗余。
但激光雷達也的確是成本大戶,早些年除了特斯拉,幾乎所有成熟的無人駕駛技術方案都採用了64位激光雷達,它的成本約人民幣70萬元,一個小雷達抵得上一輛車甚至幾輛車。
特斯拉利用佔用網絡來實現類似激光雷達的感知效果,國內主機廠由於機器視覺算法的缺失,預計仍將激光雷達作爲重要的補充傳感器,由此可減少在視覺領域所需積累的數據量。
另外4D成像毫米波雷達或將完全替代3D毫米波雷達,有望對低线激光雷達形成替代。
與激光雷達相比,4D成像毫米波雷達部分指標近似達到16线激光雷達性能,但成本僅爲激光雷達十分之一。
特斯拉基於全新的自動駕駛硬件HW4.0,首次在S/X的車型上搭載了4D毫米波雷達。除特斯拉外,價格在40萬元以下的理想車型和價格在70萬以上的寶馬車型、以及通用收購的Cruise自動駕駛服務車均於近兩年完成了4D毫米波雷達布局。同時大陸、採埃孚等汽車Tier-1巨頭基本完成對該領域的布局。
4
尾聲
8月,馬斯克親自上线开啓了一場FSD Beta V12的試駕直播,45分鐘內FSD Beta V12系統在行駛全程進展非常順利,能夠輕松繞過障礙物,識別道路各種標志。
馬斯克激動地表示:
V12系統從頭到尾都是通過AI實現。我們沒有編程,沒有程序員寫一行代碼來識別道路、行人等,全部交給了神經網絡。
而這一切是建立在巨量的「視頻數據」和1萬個H100之上。
遺憾的是,這兩個战略性資源都不是國內主機廠能夠輕易追趕上的。
參考資料
[1] 你知道么,自動駕駛竟然已存在27年?佚名
[2] 智能駕駛芯片算力越大就越好嗎,遠川汽車評論
[3] 大模型應用下自動駕駛賽道將有哪些變化?天風證券
[4] AI大模型應用於汽車智能駕駛梳理:吐故納新,如日方升,光大證券
[5] ALVINN探祕:一輛來自1989年的自動駕駛汽車,雷鋒網
[6] 爆火的ChatGPT,能讓自動駕駛更快實現嗎?鈦媒體
[7] 馬斯克直播試駕特斯拉FSD V12!端到端AI自動駕駛,1萬塊H100訓練,新智元
免責聲明:本文基於已公开的資料信息或受訪人提供的信息撰寫,但解碼Decode及文章作者不保證該等信息資料的完整性、准確性。在任何情況下,本文中的信息或所表述的意見均不構成對任何人的投資建議。
原文標題 : 大模型上車,特斯拉帶了個好頭嗎?
標題:大模型上車,特斯拉帶了個好頭嗎?
地址:https://www.utechfun.com/post/274895.html