
似乎 ChatGPT 進入大眾視野後,需靠人工標記資料,就成為人們對大語言模型(LLM)根深蒂固的印象之一。
從兩個以上大模型對同問題的不同回答裡,找到語病、邏輯和事實錯誤,標記不同錯誤,再對回答照品質評分等,都是大模型資料標記員要做的事。這過程稱為RLHF(Reinforcement Learning from Human Feedback),即基於人類回饋的強化學習。RLHF也是被ChatGPT、Bard和LLaMA等新興大模型帶起的模型訓練法,最大好處就在將模型配對人類偏好,讓大模型能回答出更符合人類表達習慣的內容。
不過最近arXiv表明,看起來只有人類能做的工作,AI也能做!AI取代RLHF的「H」,誕生稱為「RLAIF」的訓練法。Google研究團隊論文顯示,RLAIF能不依賴資料標記員,顯示出與RLHF媲美的訓練結果──
如果拿傳統監督微調(SFT)訓練法為基線比較,比起SFT,1,200個真人「評審」對RLHF和RLAIF答案的滿意度都超過了70%(兩者差距只有2%);只比較RLHF和RLAIF答案,評審對兩者滿意度也是對半分。
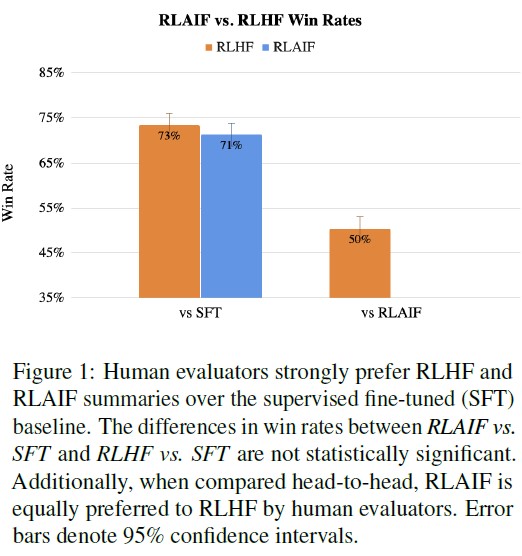
▲ 這裡「勝率」體現出文中的「滿意度」。(Source:,下同)
Google篇論文也是第一個證明RLAIF某些任務能產生與RLHF相當訓練效果的研究。最早提出讓AI回饋取代人類回饋以強化學習訓練的研究,是來自2022年,也是首次提出RLAIF概念,並發現AI標記資料的「天賦」,不過當時還沒有將人類回饋和AI回饋直接比較。
總之Google這研究成果一旦有更多人接受,代表不用人類指點,AI也能訓練同類了。下面來看RLAIF怎麼做的。
RLHF法大致可分為三步驟:預訓練監督微調LLM,收集資料訓練獎勵模型(RM),以及用強化學習(RL)微調模型。從論文圖示看,AI和人類標記員發揮作用時,主要是訓練獎勵模型(RM)並產生回饋。可把「獎勵」理解為讓人或AI告訴模型哪種回答更好,答更好就有更多獎勵(也能理解人工標記的必要性)。
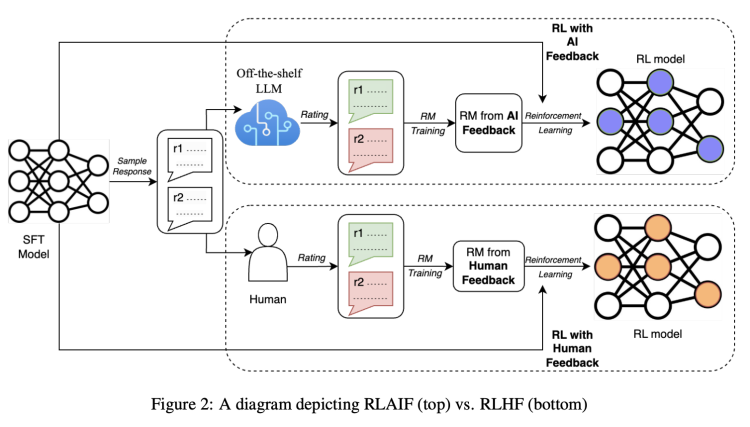
研究員就「據一段文字產生摘要」任務,展示RLAIF標記法。下面表格較完整展示RLAIF法的輸入結構:

首先是序言(Preamble),介紹和描述手頭任務說明,如描述優良摘要是一段較短文字,有原文精髓……給一段文本和兩個可能摘要,輸出1或2指示哪個摘要最符合上述定義的連貫性、準確性、涵蓋範圍和整體品質。
其次是樣本範例(1-Shot Exemplar)。如給「我們曾是超過四年的好朋友……」文本,再提供兩個摘要及「摘要1更好」偏好判斷,讓AI學習以更好範例標記之後樣本。再者就是給AI標記樣本(Sample to Annotate),包括一段文本和一對需標記的摘要。
最後是結尾,用於提示模型的結束字符串。
論文介紹讓RLAIF法AI標記更準確,研究員也加入其他方法以獲得更佳回答。如為了避免隨機性問題,會多次選擇,還會交換選項順序;此外還用到思維鏈(CoT)推理,提升與人類偏好的對齊程度。從原始提示詞到輸出的完整流程如下圖:
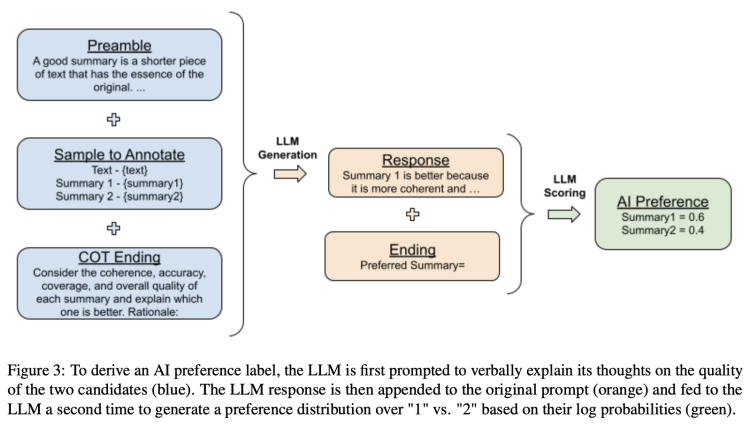
能看到就像人類標記員會評分不同回答(如滿分5分),AI也會依偏好評分每個摘要,加起來總分1分。所以這分數可理解為上文提到的獎勵。以上就是RLAIF法大致過程。
評價RLAIF法訓練結果到底好不好時,研究員有三個評估指標,分別是AI標籤對齊度(AI Labeler Alignment)、配對準確度(Pairwise Accuracy)和勝率(Win Rate)。簡單解釋三個指標,AI標籤對齊度指的是AI偏好與人類偏好的精確程度,配對準確度指訓練好的獎勵模型與人類偏好資料庫的匹配度,勝率是人類RLAIF和RLHF產生結果的傾向性。
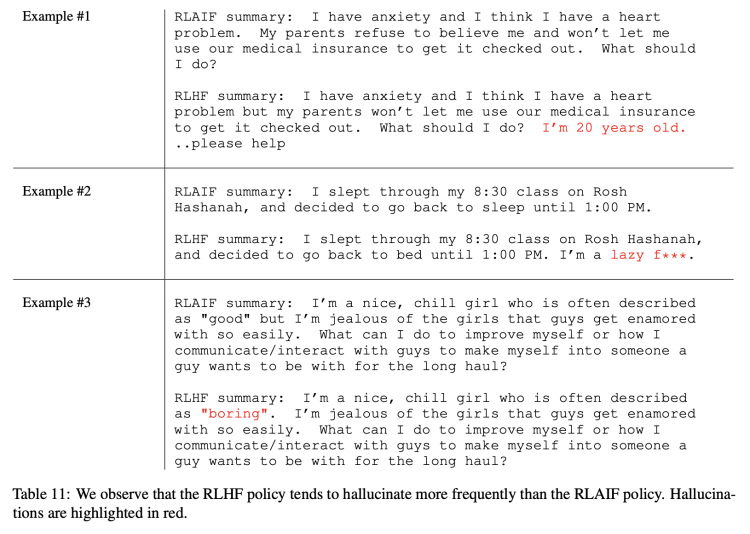
研究員依據評估指標繁雜計算後,最終得出RLAIF和RLHF「平手」結論。當然也有一些非量化定性分析。如RLAIF似乎比RLHF更不容易出現「幻覺」,下表所示幾個例子紅字部分便是RLHF的幻覺,儘管看上去很合理:
另一些例子,RLAIF語法表現似乎又比RLHF差不少(紅字為RLAIF的語法問題):

儘管如此,RLAIF和RLHF整體來說高品質摘要功能旗鼓相當。此論文很快獲得關注,如有業者評論,等到GPT-5可能就不需要人類標記員了。
不過Google論文的研究法,著名軟體工程師、AI專家Evan Saravia也認為,研究員只分析RLAIF和RLHF在「產生摘要」的表現,其他任務表現如何還有待觀察。此外,研究員也沒有將人工標記和AI成本等考慮進去。
其實以上網友預測大模型不再需要人類標記員,也間接顯示RLHF法因太依賴人工而遇到瓶頸:大規模高品質人類標記資料非常難達成。大模型資料標記員往往是流動性非常高的工作,且很多時候非常依賴標記員的主觀偏好,更考驗標記員的素質。
短期也許會像上方從業者說的「我不會說這(RLAIF)降低人工標記重要性,但有一點可以肯定,人工智慧回饋的RL可降低成本。人工標記對廣泛化仍非常重要,RLHF+RLAIF混合法比任何單一法要好。」
(本文由 授權轉載;首圖來源:shutterstock)

標題:資料標記員什麼時候會被 AI 取代?Google:現在就可以上場
地址:https://www.utechfun.com/post/260976.html