來自無錫的80後礦山管理者胡哥在閱遍衆多大模型的介紹視頻後,沒忍住對我問道:“大模型能做啥?”
這就是大模型的現狀——行業內火熱,圈外人發懵。這不禁讓人思考,大模型的時代真的到來了嗎?還是只是小圈層內的自嗨?
2023年以來,以ChatGPT、Midjourney爲代表的以內容生成爲導向的人工智能應用,引發了一輪又一輪的創新浪潮。
讓大模型技術深入生活生產的核心場景,降低使用AI的門檻,助力企業實現降本增效,成爲了各家AI、科技企業都在爲之努力的目標。
不過,從技術走向生產力談何容易。一方面,算力不足的問題一直存在,另一方面,大模型能力落地,也需要尋找更多的場景。
1
決勝大模型時代
算力、網絡、向量數據庫缺一不可
大模型應用場景日趨多樣,需求也隨着增加,進而倒逼着多元算力方面的創新,爲滿足AI工作負載的需求,採用GPU、FPGA、ASIC等加速卡的服務器越來越多。
根據IDC數據統計,2022年,中國加速服務器市場相比2019年增長44.0億美元,服務器市場增量的一半更是來自加速服務器。
這意味着未來算力一定是多元化的。
高性能、高彈性與高穩定的算力,對於網絡速度與穩定性要求也非常高,在訓練集群中,一旦網絡有波動,訓練的速度就會大受影響,只要一台服務器過熱、宕機,整個集群都可能要停下來,然後訓練的任務要重啓,這些事件會使得訓練的時間大大增加,所以投入在大模型的成本也會變大。
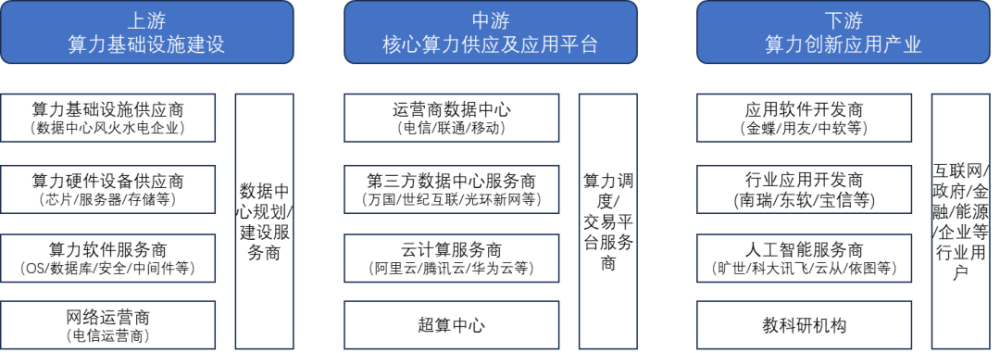
算力產業鏈,圖源:科智咨詢整理
另外,GPU服務器運營與分層次的排查也會更頻瑣,整體運維的難度與工作量也會高很多。
因此,雲所提供的穩定計算、高速網絡與專業的運維,可以爲算法工程師大大減輕基礎設施的壓力,讓他們把精力放在模型的構建與算法的優化上。
騰訊雲打造的面向模型訓練的新一代HCC高性能計算集群,搭載最新代次的GPU,結合多重加速的高性能存儲系統,加上3.2T超高互聯帶寬、低延時的網絡傳輸,整體性能比過去提升了三倍。

在大模型訓練場景,速度是核心,運算速度更快意味着一切繁復的運算和模擬會更快、更准確。結合騰訊自研的軟硬件技術,爲企業的AI計算、高性能計算需求提供算力底座。
另外,計算集群越大,產生的額外通信損耗越多。大帶寬、高利用率、信息無損,是算力集群面臨的核心挑战。
爲解決傳輸質效的問題,騰訊雲通過自研“星脈”高性能網絡,在軟件和硬件層面,如交換機、通信協議、通信庫以及運營系統等方面,都進行了升級和創新,帶來的計算效果提升也是明顯的。
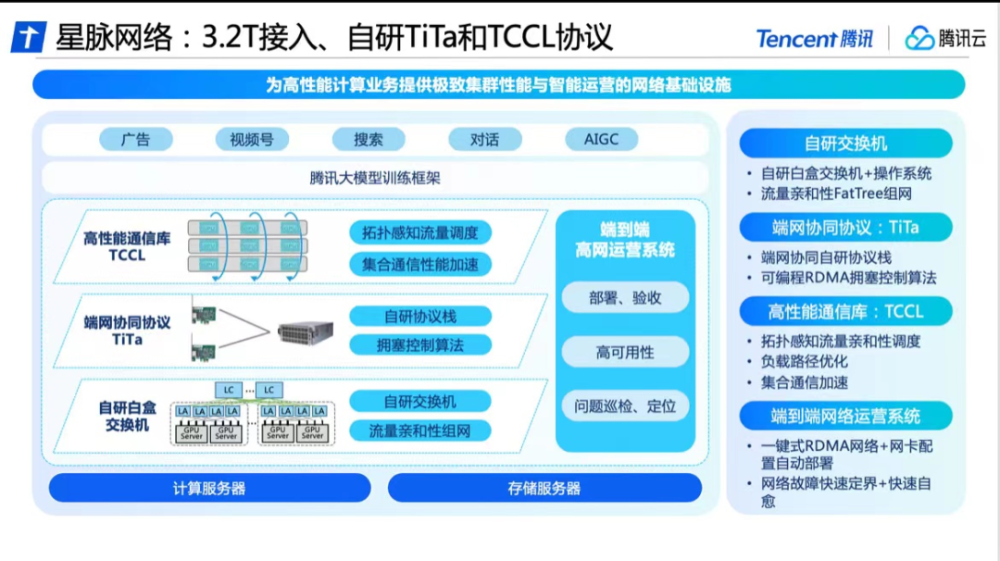
“星脈”能夠提升40%的GPU利用率,節省30%-60%的模型訓練成本,爲AI大模型帶來10倍的通信性能提升。
另外,目前的大模型都是預訓練模型,對於訓練截止日之後發生的事情一無所知。主要表現爲沒有實時的數據,並且缺乏私域數據或者企業數據。
而向量數據庫作爲一種專門用於存儲、管理、查詢、檢索向量的數據庫,可以通過存儲最新信息或者企業數據有效彌補了這些不足。
向量數據庫和大模型結合,可以降低企業訓練大模型的成本,提高信息輸出的及時性和准確度。最終大模型和向量數據庫的結合,會成爲一種通用的呈現形態或率先在垂直領域體現價值。
在擴展性方面,向量數據庫可以輕松地通過添加更多節點來擴展系統性能;在檢索方面,向量數據庫能夠實現低時延高並發檢索;在兼容性方面,向量數據庫不僅支持多種類型和格式的向量數據,還支持多種語言和平台的接口及工具。
騰訊雲向量數據庫(Tencent Cloud VectorDB),最高支持業界領先的10億級向量檢索規模,並將延遲控制在毫秒級。在大模型預訓練數據的分類、去重和清洗上,可以實現10倍效率提升。

但僅有硬件遠遠不夠,下一代的AI需要在硬件和算法方面都進行創新,大模型要想突破至下一站,需要對落地的途徑進行重新審視。
2
大模型的中場战事,產業化應用正提速
從今年3月百度率先發布語言大模型生成式AI產品“文心一言”後,各大科技互聯網巨頭紛紛入局,國內大模型瞬間遍地开花。包括阿裏、華爲、商湯科技、科大訊飛、360、騰訊等,紛紛推出各類大模型。

圖源:來源:ImfoQ發布的大模型評測報告
人工智能正在進入大規模落地應用關鍵期。
在IDC近日發布的《中國人工智能公有雲服務市場份額2022》報告中,騰訊雲憑借其2022年在計算機視覺、對話式AI等領域的領先優勢,營收增速達到 124.6%,成爲國內收入增速最快的公有雲廠商。
企業擁抱大模型的方式和路徑正在重構,可以預見,大模型能力落地和核心就是應用場景。
此前,騰訊對外表示,其自研的騰訊混元大模型目前已經進入公司內應用測試階段。自身的企業級應用已經率先基於騰訊自研的混元大模型,針對不同的應用場景提供了更智能的服務,也爲用戶提高了工作效率。
騰訊雲、騰訊廣告、騰訊遊戲、騰訊金融科技、騰訊會議、騰訊文檔、微信搜一搜、QQ瀏覽器等多個騰訊內部業務和產品,已經接入騰訊混元大模型測試並取得初步效果,更多業務和應用正在逐步接入中。
在行業落地方面,如何面向廣泛客戶群體的同時,又能給出針對性的解決方案,騰訊雲試圖在兩者的特質上給出答案。
其打造的大模型一站式服務平台MaaS(Model-as-a-Service)內置多個高質量行業大模型,涵蓋金融、傳媒、文旅、政務、教育等多個行業場景。騰訊雲TI平台已經全面接入Llama 2、Falcon、Dolly、Vicuna、Bloom、Alpaca等20多個主流模型。
基於這些基礎模型,騰訊雲的客戶只要加入自己的場景數據,就可以生成契合自身業務需要的專屬模型;同時也可根據自身業務場景需求,適配不同參數、不同規格的模型服務。
具體而言,是基於騰訊雲此前發布的高性能計算集群HCC、自研星脈計算網絡架構、向量數據庫這些技術底座,以及包含了數據標注、數據訓練、加速組件等在內的TI平台,搭建面向垂類行業的大模型平台。垂類行業企業在其中進行挑選,再針對性進行數據精調,將其升級爲企業專屬大模型。
在一周後的9月7日,2023騰訊全球數字生態大會將在深圳正式开幕,此次大會的主題爲“智變加速,產業煥新”,屆時大會對雲計算、大數據、人工智能、SaaS等核心數字化工具做出新的進展公布,可以看出當下騰訊雲在各領域的實踐狀況。
3
寫在最後
一家致力於AI聲音克隆領域創業者趙子清告訴奇偶派,雖然自己平時在批量處理一些文件、需要寫一個簡單的程序時會使用ChatGPT,但像他這樣頻繁利用GPT的人,其實僅限於有技術背景的從業者,大部分創業者在大模型問答嘗鮮後活躍度都不高。
根據調查,在大模型的創業公司中,超過80%的從業者對大模型有着深入的理解和使用經驗,而在普通人群中,僅有不到5%的人了解大模型。對大模型有限的了解,造成了國內大模型創業的局限性。
但與大部分人只知道Chat的情況不同的是,各行各業中都存在着亟需大模型能力來提升生產力的場景,而利用大模型能力提升效率,是各大廠商追求的目標,也是未來發展的方向。
而騰訊也將於一周後爲我們展現其在人工智能領域的最新進展,究竟有哪些行業、哪些從業人員將被大模型從繁雜的工作中“解放”出來,就讓我們一起拭目以待吧。
原文標題 : 大模型發展到現在,如何才能真正走向生產力?
標題:大模型發展到現在,如何才能真正走向生產力?
地址:https://www.utechfun.com/post/256562.html