解決了算力之困後,端側大模型將有可能最先引爆本輪AI革命的盈利點。
算力和數據的天花板,決定了本輪的AI熱潮究竟能走多遠。
但不幸的是,對國內而言,其中的算力天花板,離“到頂”已經越來越近。
就在8月初,美籤署最新行政令,禁止美國對中國計算機芯片等敏感技術進行一些新投資,重點將在限制美國資本對於中國半導體設計軟件和制造硬件的投資。

此消息一出,不少人頓感:國內算力危矣!
而機警的大廠,也开始了各自未雨綢繆的准備。
《金融時報》的一篇報道稱,國內包括阿裏、字節在內的科技巨頭,已經訂購50億美元的英偉達的A800芯片,來面對訓練大語言模型需要的算力挑战。

按照此前媒體報道,目前中國企業GPU芯片持有量超過1萬枚的不超過5家,擁有1萬枚A100的至多1家。
那么,在愈發緊張的算力之下,中國AI的前途、命運將如何發展?
短期來看,算力之困對於業內,似乎是個無解的問題。然而,技術的發展,有時就像生物的進化,當一種技術在面臨“生存挑战”時,也會由於選擇壓力而發生一系列的突變。
而對國內而言,這樣的突變方向,也許就是分散於各個終端裏的端側大模型。
01 端側大模型,如何解算力之困?
端側大模型的發展,對國內算力突圍有着怎樣的意義?這還得從目前雲計算的需求說起。
當下,面對大模型高昂的算力成本,許多致力於涉足AI領域,但卻算力匱乏的企業,往往都選擇了租用雲算力的方式,來滿足訓練需求。
在此背景下,昇騰AI集群這樣的雲服務平台也趁勢而起,成爲了孵化國內各個大模型的“母工廠”。

然而,即使是雲計算本身,也需要大量的GPU支撐。
如果雲服務商無法獲取足夠的GPU資源,那么它們也無法爲國內AI企業提供高效、可靠的雲計算服務。
而端側AI最重要的意義,就在於分擔了目前國內雲計算的壓力。
倘若我們將十幾億分散的智能手機,當成了一個個潛在的、擁有大量闲置算力的移動計算單元,那么部署在手機中的端側AI,就能在這些設備闲置時間裏,將這些碎片化、分布式算力利用起來,產生頗爲可觀的規模效應。
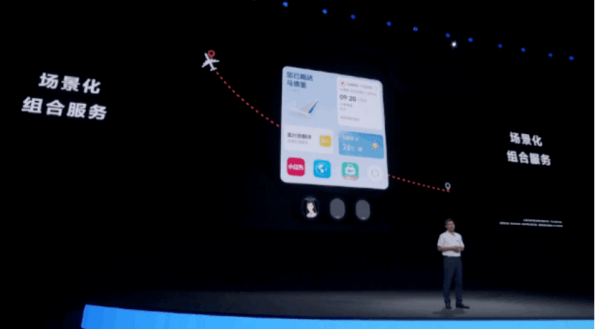
鴻蒙4中出現的手機大模型
具體來說,聯邦計算,就是這樣爲人熟知的分布式計算方式之一。
所謂聯邦計算,簡而言之,就是在數據源(例如用戶設備)上進行模型的局部訓練,然後將這些局部模型的參數或更新聚合到中央服務器上,形成一個“全局模型”。
相比於集中式的訓練,這種分布式的方式可以更好地利用各個設備的計算能力,降低中央服務器的算力需求。
在這樣的過程中,依靠終端設備(例如手機)的龐大數量規模,每個“全局模型”的訓練成本,在無意中便被不斷攤薄了。
因爲每個“小模型”的訓練只需要消耗端側設備的計算資源,而不需要傳輸大量的原始數據到雲端。這樣,就可以節省網絡帶寬和雲端存儲空間,也可以減少雲端服務器的計算壓力。

更重要的是,與雲端GPU這類高成本的訓練方式相比,由於端側AI芯片往往是針對特定的AI應用和算法,進行優化和定制,因此其往往有着相對更明確的“回血”途徑。
例如,前段時間,爆火的妙鴨相機,大家應該都聽說了。在其最受追捧的初期,成千上萬的用戶湧進應用中,高峰期一度有4000-5000人排隊,需要等待10多個小時才能出片。
之後,是阿裏雲進行了緊急擴容,才勉強應對了這暴漲數百倍的算力需求。
但倘若用戶不用在雲端等待,而是直接在本地,或者通過端雲協同的方式,就能實現這樣的生成效果呢?
一種可能的方式,是先在端側生成低分辨率的圖片,之後再上傳到雲端,用較少的資源對圖片進行清晰化處理。
如此一來,既降低了雲端算力的負擔,又在一定程度上保障了生成的質量、效率。
在當下的AI應用开發中,开發者不僅需要支付雲端大模型API接口的成本,還得自己租用服務器,保證密鑰安全。
如果是文字生成類AI,文字量大的話,相應的token也是一筆不小的开支。
而隨着算力門檻的降低,衆多AI應用的开發者,將不再被雲端算力的成本所縛,而只需調用端側大模型提供的开放API,就可以快速开發各類AI應用。
在此基礎上,一個开放的、多樣化的AI應用生態,就隨着端側大模型的普及,而應運而生了。
02 以“偏”補“全”的端側芯片
AI應用井噴的時代似乎近在眼前,但要想讓每台手機都標配一個大模型,前面還有道難以回避的門檻——硬件基礎。
由於芯片架構不同,在端側部署時,往往需要對模型網絡結構進行一通修改才能勉強“上車”。
具體來說,目前GPT這類主流AI所使用的Transformer架構,往往部署於雲端服務器。

這是因爲GPU對於MHA結構(Transformer中的多頭注意力機制)計算支持更友好。而端側AI的芯片,則主要側重於CNN(卷積神經網絡)的結構。
如果將前者強行轉移到端側,帶來的一個明顯問題,就是模型精度下降。
那么有沒有什么辦法,能讓大模型在進行端側化改造的同時,仍能保證其精度呢?
愛芯元智推出的端側芯片AX650N,似乎提供了一個可能的路线。
AX650N芯片擁有自研混合精度NPU和愛芯智眸AI-ISP兩大核心技術,其對Transformer結構的網絡進行了專門的優化,在其NPU中增加了專門用於自注意力計算的單元,可以大幅提升Transformer網絡的運行速度和准確率。

憑借着這類針對端側的優化技術,AX650N已經做到了在端側部署原版Swin Transformer只需要5分鐘,而跑起私有模型,只要1個小時就能搞定。
但盡管如此,受限於架構和內存,這樣的優化,僅僅只是針對視覺大模型方向而言的,因爲從硬件算力上來說,端側AI芯片,始終難以做到GPU芯片那樣“面面俱到”的通用性、兼容性。
既然如此,國內的大模型之困,是否就指望不上它了?
其實不然,從量的角度來講,邊緣側、端側的需求一定比雲側更大,畢竟邊緣側、端側設備會更多。
而在這衆多的需求中,只要使用了大模型的終端(如手機、智能音箱),能做到兩點,那么國內大模型在應用層,就有盤活的可能。
其中第一點,就是夠降低人們獲取信息、知識的成本。

倘若以後人們打开手機或者其他終端,就能獲得一個諸如私人醫生和律師、廚師的AI助理,能爲我們提供成本低廉、快速的咨詢服務,那么人們就會對其產生依賴。
因爲從行爲學上來說,人總歸是有惰性的。
雖然目前的某些律所,也能爲人們提供免費的咨詢服務,但這其中卻包含了無形的時間成本、溝通成本。
正如互聯網出現後,雖然人們仍能通過紙制地圖進行導航,但大部分人卻再也離不开手機上的定位功能一樣。
從某種程度上說,壓縮了各種知識、智能的端側模型,將會重復這一過程。
第二點,則是個性化功能的普及。

在“前AI時代”,個性化定制的大規模推廣,是一件不可想象的事。
在沒有AI技術支持的情況下,實現個性化定制通常需要大量的人力和時間投入。爲每個用戶提供個性化的產品或服務,往往需要大量的人工處理。
然而,隨着本輪AI革命的到來,人們已經在應用層,看到了AI用於個性化、定制化服務的可能。
例如character.Ai一類的應用,支持用戶根據自己的需求、偏好,量身定制一個“AI伴侶”。
試想一下,倘若這樣的定制化服務進入到了端側,端側大模型就能不斷收集用戶數據,再進行反饋、訓練,並最終打造出一個獨一無二的、貼身的AI助手。
而這樣量身定制的體驗,顯然比大規模的標准化服務,更具吸引力。
03 總結
盡管在模型規模、性能等方面,端側大模型目前還遠無法與雲端大模型相比,但分布式的算力格局,以及龐大的規模效應,都將大大降低目前國內雲端算力的負擔。
而在算力成本降低之後,大量基於API接口的AI應用,也得以通過一個個部署在本地的端側大模型不斷湧現。
在應用大爆發的背景下,一些捕捉到先機的應用,就會基於端側大模型實時響應、個性化定制的功能,引爆本輪AI革命真正的盈利點。
而這,正是無數人在這股AI浪潮中苦苦追尋的。
原文標題 : 端側AI,如何化解國內算力之困?
標題:端側AI,如何化解國內算力之困?
地址:https://www.utechfun.com/post/250949.html