
黃仁勳於 SIGGRAPH 2023 主題演講表示 Nvidia 為降低生成式 AI 門檻非常努力。生成式 AI 是這次大會毋庸置疑的主角,黃仁勳透露軟硬體及生態更新,總結就是盡力降低生成式 AI 門檻──讓大模型更實用。
買越多省越多2.0
硬體方面,Nvidia推出GH200超級晶片更新,或稱為HBM3E增強版,是世界第一款HBM3e處理器。由NVLink技術,互聯Grace Hopper超級晶片平台提供1.2TB快速記憶體,HBM3e 記憶體比HBM3快50%,平台總共提供10TB/秒組合頻寬,也就是說,記憶體容量增加3.5倍,頻寬增加3倍,平台有一144個Arm Neoverse核心、8petaflops的AI性能和282GB最新HBM3e記憶體伺服器,與台北電腦展公布的Nvidia MGX伺服器完全相容。
資料中心硬體快速向加速計算轉變,是黃仁勳一直強調的趨勢。比起CPU,GPU能效有更大優勢,黃仁勳舉例同樣1億美元成本,比起x86架構CPU,GH200能提供超過20倍能效提升。於是又可聽到黃仁勳名言:「The more you buy, the more you save.」買越多省越多,真是不忘初心。

▲ 黃仁勳演講PPT顯示,2,500張GH200組成的資料中心比CPU高20倍能效。
除了資料中心還公布兩套硬體,同樣針對大模型。一款是桌面級RTX工作站,包括最多4個RTX 6000 Ada GPU,單桌面工作站提供高達5,828tflops的AI性能和192GB GPU記憶體。另一款是OVX伺服器,有8個L40S GPU,每GPU搭配48GB記憶體,可提供超過1.45petaflops張量處理能力。
新RTX工作站執行8.6億個token的GPT3-40B需15小時,OVX伺服器只需7小時。OVX伺服器比A100推理性能提高1.2倍,訓練性能提高1.7倍,單精準度浮點(FP32)性能是A100近5倍。

▲ L40S GPU。
硬體更新有階段性,黃仁勳明白說:for everyone,Nvidia每個價格段都為潛在客戶準備好產品。除了伺服器和工作站,Nvidia還發表三款專業顯卡:RTX 5000、 RTX 4500與RTX 4000,採Ada Lovelace架構,顯存提升(RTX 4000有20GB GDDR6顯存,RTX 4500為24GB,RTX 5000最高32GB ),是Nvidia顯卡曾削弱的部分,現在顯存對大模型無比重要。另使用第四代Tensor Core,AI訓練性能比上一代快兩倍,並擴展支援FP8數據格式。
硬體最終組成強大陣容,囊括企業級客戶到個人使用者。但黃仁勳看來,想觸及每個人,Nvidia還需要「軟性工具」。
軟硬兼施
距離黃仁勳推出DGX Cloud才短短幾個月,降低使用者和開發者使用大模型門檻又有新動作。第一非常好猜,就是和Hugging Face合作。Hugging Face已和AMD、AWS等巨頭緊密合作,大家都看中整合開放模型優勢,Nvidia也不例外。
「點一下滑鼠即可叫Nvidia AI運算」,黃仁勳說,幾個月前發表的DGX Cloud和Hugging Face平台整合,用戶可於自己電腦啟動,然後擴展到工作站和資料中心。
二是Nvidia AI Workbench,開發人員可直接在PC和工作站創建、測試和客製預訓練大模型,模型、框架和軟體開發套件與資料庫整合成統一開發人員工具包,AI Workbench直接調用Nvidia算力資源,且完整支援Nvidia硬體──之前工作站和伺服器都支援AI Workbench終端測試微調。
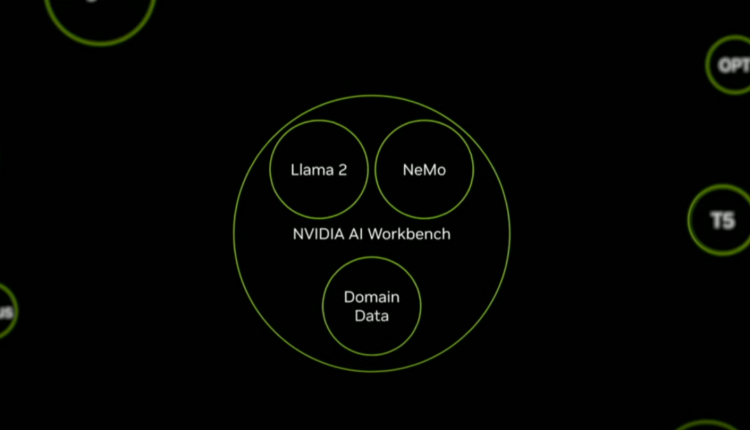
▲ 開發者原本分散各處的大模型開發工具與流程,現在Nvidia AI Workbench都可整合。
介面就是網站。截圖可看到終端計算機是消費級4090行動版顯卡。這簡化大模型操作流程,只需一台電腦就夠用。「每人都能做到」,黃仁勳說,某種意義講像大模型民主化。
另一個降低生成式AI部署門檻的服務是名為AI Enterprise 4.0的企業軟體平台,主要針對企業客戶。AI Enterprise 4.0包括NeMo大模型雲原生框架和集群管理軟體,幫助企業客戶管理從雲端到資料中心再到邊緣設備所有AI解決方案,整合至Google雲端和微軟Azure。
場景在哪裡
大模型最近頗有爭論的話題是,應用場景到底在哪裡?
這對善於從第一性原理出發的老黃來說恐怕不是問題,一方面有硬體技術,一方面有軟實力,Nvidia層次顯然更高──不是找場景,而是打造生態。因Nvidia看來沒什麼「垂直場景」,一切都可用生成式AI介入,承載者是Omniverse。
元宇宙對黃仁勳不是過氣名詞,而是連接虛擬與物理世界,並大大開發生成式AI潛力的工具。虛擬與現實轉換,Nvidia看中通用場景描述(Universal Scene Description,OpenUSD)的潛力。
黃仁勳把OpenUSD對虛擬世界的重要性與HTML之於2D網路相提並論。簡單來說,可把OpenUSD理解成通用描述3D場景語言──過去需非常複雜流程和不同工具才能做到。有了通用語言,不同人就能基於同背景建構3D世界,也就是元宇宙。

▲ 透過OpenUSD構建共同3D場景,儘管來自不同工具和平台。
顯而易見,OpenUSD在Nvidia元宇宙願景佔重要地位,故Omniverse多重升級。
黃仁勳推出四個Omniverse Cloud API,方便開發人員無縫部署OpenUSD應用。最吸引人的是ChatUSD功能,顧名思義能用問答方式幫助開發者產生3D模型,現場示範為提出要求,ChatUSD就直接給你Python-USD程式碼腳本,直接就能使用!
另外生成式AI技術的API名為DeepSearch,是大語言模型代理(LLM agent),可快速搜尋無標記資料庫內容。另一方面,Omniverse本身大升級以支援OpenUSD,如少量程式碼就能快速開發本機OpenUSD 應用及允許用戶組建基於OpenUSD的大規模場景。
Nvidia看來,Omniverse因OpenUSD變強,能跨3D工具和應用虛擬這世界,代表生態搭建:既然大家都是用OpenUSD建構3D世界,那顯然數位孿生互連操作可以此為基礎達成。
故Nvidia元宇宙生態──被生成式AI和OpenUSD加持──更具規模,Adobe Firefly可為Omniverse的API提供給開發者,許多業界知名元宇宙和虛擬人開發者,Convai、Inworld AI和Wonder Dynamics都能夠借助OpenUSD通用標準與Omniverse連結。

Nvidia對元宇宙未來充滿自信。波士頓動力使用Omniverse模擬機器人互動,更多工業自動化案例,Volvo、賓士和BMW都是Omniverse客戶──實際投資建設高昂工廠前,可至Omniverse的虛擬世界檢查和測試物理世界定律。
步入融合
生成式AI熱度不退,Nvidia當然更有理由加柴添火,老黃是盡職盡責的商人,發表會說的最後一句話還「the more you buy, the more you save.」足見其不忘初心的商人本色。
想要硬體賣得好,股價再創新高,Nvidia不斷反覆改良產品,提升性能,打造更豐富的生成式AI產品陣容,另一方面還要降低大模型使用門檻:後者甚至只有Nvidia才能做到,因踩中絕佳方位:繪圖處理。為了讓機器文產圖,人類花了幾十年,最終Nvidia開發出顯卡,現在事實證明,圖形顯示並行計算恰好適用生成式AI,而虛擬世界也需要更強大的圖形技術和人工智慧幫助。
黃仁勳又舉例:全球最大廣告公司WPP藝術家透過Omniverse運用多種支援OpenUSD的工具,設計出比亞迪汽車數位孿生版──全球百餘區行銷活動都基於這些生成內容。五年前SIGGRAPH大會Nvidia發表支援光線追蹤的GPU,那時沒人想得到,人工智慧、虛擬世界、加速計算、雲端,會以如此迅猛的速度逐漸融合。
(本文由 授權轉載;首圖來源:)
延伸閱讀:

標題:Nvidia 又發表最強 AI 超算聯手 Hugging Face,黃仁勳開始收大模型稅了
地址:https://www.utechfun.com/post/247682.html