文:互聯網江湖 作者:志剛
這年頭,不做大模型就不好意思說自己是科技公司。
這不,“百模”大战打了幾個月之後,又有新玩家入場了,京東、攜程都加入了大模型“战場”。
相比京東、攜程發發布大模型布,這兩天的大模型發生了一個更重量級的事情:Meta發布新一代AI模型LLama V2,並宣布LLama V2开源,並可直接商用。
傅盛發朋友圈評論:“這一下不知道多少公司笑醒在深夜,多少公司哭暈在廁所……”
據傳,LLama V2性能超過了GPT-4、Microsoft和Google的AI模型,能夠生成語言、代碼和圖像。最重要的,相比GPT4,LLama V2开源,並且可以直接商用。
消息一出,不少人都在感慨:一夜之間大模型變天了。
要說大模型行業變天,恐怕還有點早,但LLama V2开源可商用、再加上國內這么多大模型落地,“百模”大战,恐怕要迎來第一個“淘汰賽”階段。
“百模”大战之後,大模型邁進應用驅動階段
大模型賽道,做通用模型的都是大公司。
Open AI背後站在微軟,文心一言背後是百度,通義千問背後是阿裏,混元大模型背後是騰訊……再加上商湯、訊飛等“本土”玩家,留給後來者的舞台其實並不大。
而這個不大的舞台,如今卻顯得有些擁擠。此前一份國產大模型列顯示,目前國內的大模型已經有近百家。
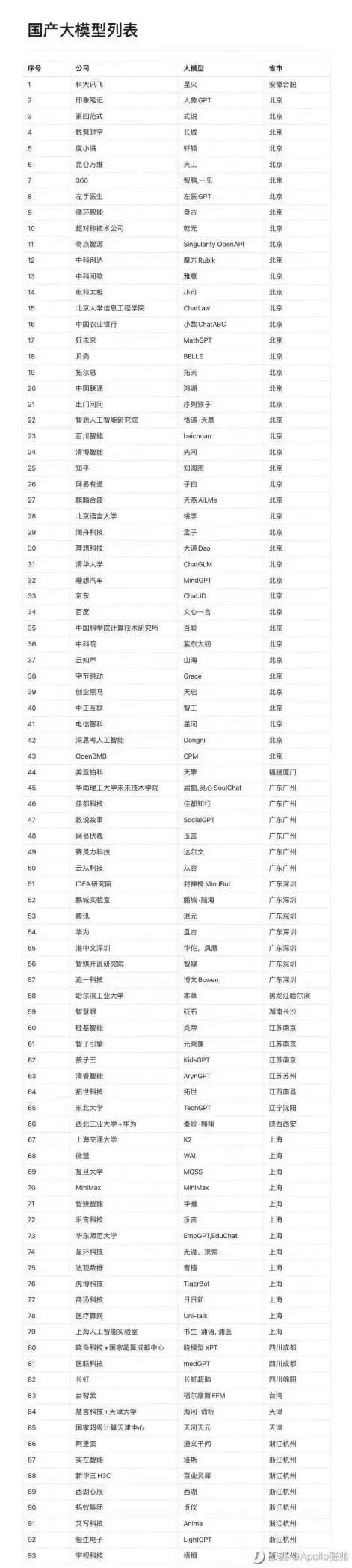
這么多大模型落地,說明AI大模型可能即將進入產品驅動階段。
互聯網江湖認爲,大模型的發展會經過三個階段。
第一階段,模型數據、數據爲核心的技術驅動階段。
從ChatGPT 到GPT3階段,大模型是由技術驅動,這時候關鍵是算法,和數據訓練。
GTP3之後,差距就在於數據量,這不難理解,這好比是一個有着超強學習能力的孩子,在咿呀學語之前,進步不大,一旦掌握了世界的“數據語言”,那么大模型的進展是飛速的。
而做通用大模型的玩家,需要盡快度過這個階段,並建立自己的核心優勢。
目前來看,百度文心、騰訊混元、阿裏通義千問、商湯大模型、以及訊飛火星等,國產主要大模型都走到這一階段。
這些大模型,都是大公司做出來的,能走到這個階段的大模型,要么算法更先進,要么有足夠的數據參數和訓練量。
以百度爲例,5月份上线的文心大模型3.5,能力已經超出ChatGPT 3.5,雖然官方沒有公布具體的數據量級,但大量的數據、算法優化訓練是必經之路。
這個階段,拼的其實就是硬實力,拼的是數據生態,人才技術和資金投入,創業公司很難真的從底層做起來。
第二階段,是產品驅動階段。
當國產大模型不斷湧現,“百模”大战的格局上演之後,行業其實就已經走到了產品驅動階段。
產品驅動階段,“百模”大战會經歷一輪淘汰賽。
大模型從業者普遍認爲,400 億-500億參數量級是模型能力“質變”的門檻。換言之,對於資本市場來說,百億參數量級之前,一些大模型項目很可能會首先遇到“生存問題”。也就是說,對於一些後來者、在遇到生存問題之前,必須要有足夠應用落地。
也因此,產品階段的大模型,核心在落地場景。
大模型其實沒有什么路线之爭,垂直或者通用,與其說是路线之爭,倒不如說是落地的場景之爭。
我們認爲產品驅動階段,大模型落地的重點在於,大公司底層做起,打造行業大模型基礎設施,在此之上,垂類的創業公司去做應用端的垂直創新。
其實現在已經有企業走在這條道路上了,比如商湯SenseChat大模型,在不少領域已經开始與品牌合作落地。
“表面上看通用大模型和垂直大模型代表了兩種技術方向,但實際上兩者相輔相成,可以並行發展。更強的通用大模型具備更強大的學習能力,可以快速融合不同行業領域的知識,支持垂直大模型的訓練和开發。”商湯科技相關人士表示。
在大模型領域,商湯扎根很深。
4月份,商湯“日日新SenseNova”大模型體系公布,並迅速落地。在自動駕駛行業,商湯構建了業內首個感知決策一體化的端到端自動駕駛解決方案UniAD,,使車道线的預測准確率提升了30%,預測運動位移的誤差降低了近40%,規劃誤差降低了近30%。
天眼查APP顯示,商湯科技2021年在香港上市,彼時上市募資55億港元。

科大訊飛落地也很快。此前科大訊飛曾表示,隨着星火認知大模型的不斷迭代,其診後康復管理平台將逐步實現對所有病種、病程的精細化管理等能力。科大訊飛的大模型最大的特點是更C端,有自己的產品矩陣,接入大模型之後,更容易觸達C端用戶。
大模型領域,最先產生商業價值不一定是通用的ChatGPT4,反而更可能產生在應用端走得更快的領域。
實際上,在科技進步的浪潮中,並不是所有的價值都會被先發的企業拿走,技術商業化的價值,往往會被更成熟的企業拿走的更多。
就像微信不是最先出現的社交應用,但無疑是最成功的。
第三個階段,是用戶驅動階段。
有了場景之後,最重要的是能夠獲得用戶的認可。從過去AI技術的落地來看,由ToB到ToC,是大模型落地的最終路徑。所以,首先爲大模型买單的一定是B端。
不過,從底層商業邏輯上,誰是最終的“受益者”,也就會是最終的“买單者”,說到底,大模型應用的最終結果還是要服務用戶。長期來看,也最終會走到用戶驅動的階段。
只不過,與現在大家所熟知的移動應用不同,“大模型應用”的用戶驅動會更快更直接,因此,有大量C端用戶的公司(百度、阿裏、騰訊)的進展速度可能會超出想象。
大模型應用爆發的黎明,商業化拐點已至?
雖然大模型很火,但真正躬身下沉的玩家都是大公司,投資市場的交易數量與去年淡季沒有什么變化。
很明顯,市場有顧慮。
比如,現在下場了,將來如何退出?大模型畢竟是個需要長期投入的項目,募資難,想要退出也難。再比如,比較有潛力的大模型項目其實都在大公司手裏,這不是說創業公司沒有機會,但市場還是在觀察。
“大模型的終局會是什么呢?我認爲對於大模型來說,終局會集中在少量的幾個大模型”。百度集團副總裁吳甜表示。
吳甜認爲,大模型產業生態可類比芯片代工廠,把大數據、大算力、大算法都封裝,建設自動化、數字化、標准化的生產模式。
一方面,從底層做起來的大模型,成本非常高,需要多年積累。另一方面,應用層面,幾個少量大模型,就會有非常廣泛的應用生態。換句話來說,其實並不需要那么多大模型來做重復的應用。
大模型領域,可能也會有一個新的“二八定律”:兩成的大模型玩家掌握真正的底層核心技術,而八成的大模型企業都在各個領域創新,去做大模型的應用。
可以預見的是,Meta的LLama V2大模型开源、放开商業化之後,大模型應用端的創新會迎來一個高潮,而國內大模型產品集中爆發,應用端也會迎來許多的新變化。
過去的十年,以用戶關系爲中心,互聯網完成了內容消費、服務消費、商品消費的中心化。
大家看視頻到抖音、快手、B站,买東西到淘寶京東拼多多,本地生活到餓了么美團。於是,搜索廣告之後,短視頻、本地生活、電商,成了互聯網技術創造價值的主要方式。
而大模型,正在用新技術和新交互,重新改變價值的創造方式。
這種改變分爲幾個方面:
一、過去的互聯網是分發內容,而大模型則是在分發的過程中創造內容;
你向大模型發出一個提問,AI不是事先給出答案,而是在實時生成答案,這樣的信息交互方式,本身是分發,也是在創造。
如果應用到廣告領域,就可以通過大模型實時生成廣告,廣告內容、呈現方式觸達用戶更精准,不再是所謂的“精准投放”而是真正意義上的“一對一”的制作、傳播廣告。
在過去,一千讀者心中有一千個哈姆雷特,而在未來,一千個用戶面前同時展示的,則是一千個不同定制的品牌廣告。用戶更能接收到品牌關鍵信息,廣告的轉化率也就更高。
在廣告領域,已經有相關的嘗試,百度基於大模型推出“擎舵"、騰訊推出“混元”,阿裏媽媽的AIGB出價模型,都是這個方向上的應用嘗試。
進一步來看,這種“黑鏡”式的信息分發、創造,可能會改變整個互聯網的內容生產邏輯。
二、大模型的交互設計,有新的商業化機會;
大模型的應用,淺層的是強調功能性,深層的是改變成本結構。
一個基本的判斷是,大模型商業化應用首先會改變的一定是廣告、營銷行業,因爲廣告行業對用戶獲取信息的方式變化更敏感。
因此,在營銷、內容創造等行業,一些新的商業機會可能會被發現。
幾乎可以確定的是,在初期的應用階段,商業化的機會一定與交互有關。
比如,Copy.AI和Jasper這兩個營銷創意工具,以GPT-3作爲底層接口實現了持續的規模化變現。他們提供了交互界面和插件、API接口,讓大模型能更好的去服務某個領域的客戶。
當然,這只是解決最基本的功能性問題,大模型真正的價值在於改變垂直行業的成本結構,比如自動駕駛大模型的商業化價值,就是在於改變了人們的出行成本結構。
營銷只是一個方面,商業化方面,其實還是得看具體細分領域的應用。
對於不同的領域,大模型會不斷的被垂直細分,去滿足更小、更細微的場景應用。而這些更細微,更小的場景,可能會有率先商業化的機會。
比如,文本生成,比如圖片生成。能夠先讓編劇、漫畫家的工作變得更容易?能不能把文案從做PPT的日常循環中給解放出來,這些細小的場景,能夠率先變現。
大公司,和創業公司,在應用層差別可能不是很大,應用層是創業機會最多的大模型領域,未來行業內也可能會跑出幾家專注於大模型應用的公司。
互聯網江湖認爲,新技術應用,找到專有價值鏈要素,嵌入行業,是一個必經之路。因此在應用上,找場景的公司,比練算法、堆參數的公司更有機會。
大模型的成功有階段性質變,就像是GPT3到GPT4,但接下來這種變化會越來越不明顯。也就是說,數據訓練的邊際收益會降低,
大模型能力的進階需要數據量做支撐,而商業化則需要考慮成本問題,如何解決這個問題,頗爲關鍵。
商業化拐點已至,大模型的商業化短期看B端,長期機會可能還是在C端。
大模型,有點像前幾年火的ToB,不僅是要看自身的成熟度,也得看行業端的適配。
大模型的成本很高,商業化首先就要到合適的場景中,並且能夠真正賺到錢,只有真正在AI應用場景中掙到錢,並且能夠真正與行業適配,大模型才有商業化的競爭力。
能夠承載大模型商業化的,只有降本需求更迫切的B端。
事實也的確如此,以商湯爲例,在金融領域,商湯與銀行、保險、券商等客戶展开合作,利用數字人進行智能客服、智慧營銷等工作,並通過接入大語言模型能力,提供投研分析、研報撰寫等新功能,試圖幫助銀行金融機構降本增效。
在醫療領域,商湯中文醫療語言大模型“大醫”,也能夠提供導診、問診、健康咨詢、輔助決策等多場景多輪會話能力。
進一步來看,B端之外,未來的大模型也可能會承載更多的商品和服務分發。
移動生態中,觸達用戶的方式其實就是網頁、APP、小程序,那么未來的大模型生態中,如果用大模型來分發內容,那么流量的分發會更加去中心化。
實際上,一旦語言大模型成熟,並且有了足夠多的用戶習慣,那么,承載商品與服務分發的APP、小程序,可能就會被大模型取代。
也就是說,在ToB應用的階段之後,未來大模型長期的價值和商業化機會,更多其實還是在C端。
只不過,以當下的視角來看,很難去定義AI應用的“新場景”,這就像是當你身處90年代,你不可能預測到如今的微信、抖音崛起。
如今的大模型也同樣如此。
結語:
從公元元年到18世紀,人類經濟增長曲线幾乎是平的,也只有在近三百年才出現工業革命,近幾十年才有了信息技術。
人類歷史上第一台計算ENIAC最初誕生,並不是用於個人計算,而是用於大量軍用數據的計算,但數十年後,它卻徹底改變了人們的生活方式。
如今的大模型,就如同當年的ENIAC。
當泡沫散去,大模型究竟是不是“比互聯網更偉大”的機會?或許人們心中早已有了答案。
原文標題 : “百模大战”即將迎來一輪應用淘汰賽
標題:“百模大战”即將迎來一輪應用淘汰賽
地址:https://www.utechfun.com/post/246793.html