我們知道,大模型會編造不正確的答案,產生“幻覺”。
其實,在應用層面,還存在一個更隱蔽的“幻覺”,就是創業公司忽略了大模型落地所需要的長周期、重基建和工程化難度,帶來的“速成幻覺”。
隨着“百模大战”拉开序幕,大模型過剩帶來的市場擠壓,也給整個大模型生態帶來了行業洗牌的風險。

越來越多的人有了共識,基礎通用大模型競爭激烈,注定是少數人的遊戲。創業公司隨時可能倒掉,造成項目爛尾。
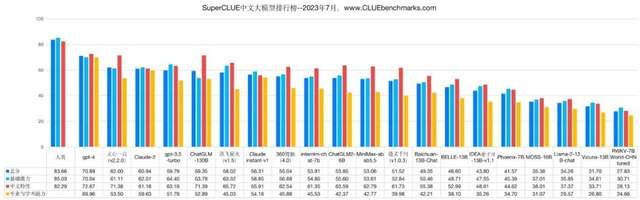
具備技術、產品和行業優勢的“第一梯隊”大廠,比如百度的文心大模型3.5,已經跟國內其他模型拉开了差距,具有了一定的先發優勢和市場打开度,更容易在這場白熱化競爭中生存下來。
既然大模型很難“速成”,那么創業公司的“幻覺”,又是從何而來的呢?
第一種“幻覺”:开源幹翻閉源
創業公司紛紛入局大模型,給它們勇氣的,不是梁靜茹,而是开源。
以Meta的Llama 2、智譜AI的ChatGLM爲代表的开源大模型,陸續免費並支持授權商用,這無疑是一件好事,讓創業公司不用重復造輪子,可以用开源大模型作爲基座模型,快速开發出相應的商用版本大模型或大模型應用。
开源的低門檻、低成本,帶來了“开源幹翻閉源”的幻覺。
爲什么說是幻覺?我們可以從企業視角爲出發點——即使有了开源模型,想要落地應用大模型,還有哪些必要條件?
一是雲基礎設施。
大模型落地需要進一步微調、訓練、運行,要在雲平台上運行。而創業公司跟OpenAI 、百度等閉源頭部公司的一大差距,就在於缺少跟雲平台的“緊耦合”。
衆所周知,OpenAI有微軟的大力支持,百度文心大模型背後是百度智能雲,這些大廠自研大模型,都對雲基礎設施的計算硬件集群、資源調度等,進行針對性的協調優化,大模型+AI雲的緊密配合,可以更高效地利用計算資源,降低大模型的邊際成本。
海外大模型开源社區的“明星”如Together會爲企業客戶提供开源模型及配套的雲平台,MosaicML也提供Mosaic Cloud 和多雲混合服務,國內的开源項目如ChatGLM,也選擇與多家雲廠商合作。
可以看到,开源項目跟雲平台的“松耦合”,會受到雲平台的配合度、商業政策等的影響,一旦後期出現資源漲價、利益分成、研發意向變化,都會給基於开源的大模型項目帶來商業化風險。
其次,是二次开發。
基於开源模型的創業公司,往往是在底座模型的基礎上做一些微調,靈活有余,但开源模型的分支多、變異快、創新迭代速度快,不承諾任何確定性,一般由程序員自組織來完成开發,這就導致基於开源的大模型穩定性不足,對客戶技術團隊二次开發能力要求很高,選型難度也很大。
目前看,第一梯隊的大廠推出的基礎大模型,更能滿足企業對大模型穩定性、可靠性的需求。
因爲閉源大模型,遵循的不是开源範式,而是工程範式,所以,會以保證开發質量爲前提,對用戶需求進行明確的描述,組織工程師按照規範的开發流程和周期,以確定的時間和預算,更好的控制开發質量,保證开發效率。
开源是一件好事,但开源並不是一把萬能鑰匙。如果不解決基礎設施、二次开發等瓶頸,創業公司也無法靠开源,快速取得成功。
第二個“幻覺”:三五個人幹翻大廠
因爲开源,創業公司和互聯網企業都可以叫賣大模型,這就產生了第二個“幻覺”:三五個人的創業團隊,就能幹翻AI大廠。
需要注意的是,“百模大战”帶來了白熱化的淘汰賽,同時,大模型還在以周爲單位進行迭代。
在激蕩的市場競爭中,具有長期研發能力和投入意愿的大廠,更容易保持動態的生長力和持久的話語權,體現在幾個方面:
一是模型本身的技術城池。
谷歌研發人員此前曾發文稱,因爲开源,谷歌和OpenAI都沒有護城河。這在長期看是對的,但大廠在大模型技術上的領先性,也是現實存在的優勢,這個技術代差,足以在大模型的商用周期中,爲大廠帶來顯著的競爭優勢。
而且,大模型具有數據上的“飛輪效應”,更早應用、更多用戶的大廠大模型,會不斷拉大效果差距。比如國內最早推向大衆的文心大模型,其3.5版本已經在一些基准測試中,超過了GPT3.5的表現,而宣稱達到GPT-3.5的Llama 2剛开源不久,因此目前國產开源大模型最多也就達到GPT-3的水平。
二是持續迭代的成長能力。
大模型落地不是一蹴而就的,企業應用大模型也不能上馬後很快不了了之,後續的算力成本、數據工程負擔、每一次迭代的資金壓力,很快就成爲困擾很多大模型公司的頭疼問題。
目前,已經有不少曾經想走商業閉源路线的大模型創業公司,直接宣布退出競爭。光年之外中途離場,被美團接手;Hugging Face專注賣算力資源和咨詢業務,做大模型更多是“面子工程”。科大訊飛等企業的財報表現,也會直接影響到市場對其“是否有錢繼續做大模型”的信心。
從成長性看,有資金實力、基礎設施完整、商業表現良好的大廠,才能陪企業用戶走得更遠。
比如“文心一言”3月16日推出以來,在一個月內完成4次迭代,將推理成本降爲原來的十分之一,離不开百度在大模型上的長期投入,以及人、錢、卡、基建等多種方面的儲備,才讓文心一言可以持續進化,在高速迭代的大模型競爭中保持領先。
三是完善的工具鏈。
沒有人會否認,大模型是拿來用的,不是爲了當擺設或“公關效應”的。
要用,就要考慮到技術和場景的適配。不同行業和企業對於大模型落地的需求,可能是完全不同的,這種差異化,需要更完善、全面的配套工具,來降低應用門檻。舉個例子,行業+大模型需要進行專有數據的清洗、標注、向量化等工作,這個過程是非常復雜的。
三五人的創業團隊,很難將主要研發力量,放在开發這些看上去技術含量不高、但對用戶十分重要的工具上。
這時候,百度等大廠長期押注AI的優勢就凸顯出來了,已經沉澱了從數據集、模型訓練、开發部署等整套流程的工具,並且开箱即用,把大模型到產業落地的門檻不斷降低,從而开啓增長飛輪。
四是長期積累的行業Knowhow。
大模型產業化,走向ToB和ToG是大勢所趨,要求對行業Knowhow有深層次的理解。因此,政企客戶在大模型選型時,非常看重廠商的成功案例和行業服務經驗。
AI大廠在產業已經深耕多年,因此大模型的商業开發度更高。目前,百度“文心大模型+飛槳深度學習框架”的組合已與300多家客戶合作,在400多個企業場景中取得良好測試效果,並打造了10多個行業大模型。
與之相比,還沒有走通產業場景的創業公司,在技術體驗、功能創新、工程能力等細節上,可能還需要花費更多時間去摸索。
從這些角度看,頭部大模型已經建立起了較爲明顯的優勢,並且還在持續進化。三五人的創業公司,想要在高速迭代的大模型競爭中幹翻大廠,需要補的課有點多。
第三個“幻覺”:大模型能“賺快錢”
創業公司通過“資金換規模”的短平快战略,上市融資再套現離場,來兌現投資回報,已經越來越難了,在大模型領域並不現實。那么,另一條路就是通過ToB客戶付費,來完成大模型的商業化。
衆所周知,ToB行業要幹苦活累活。
企業客戶在業務場景中接入大模型,可能帶來一系列復雜的整合動作,是一個體系化工程,這就要求大模型廠商不能單一快節奏地交付,而要提供解決方案式的整體能力,以及長時間的更新運維服務。
一個項目的交付、運維、迭代、回款等,可能以年計,是無法快進快出的。所以,大模型下沉到行業,必須打消“賺快錢”的念頭,以長期主義的心態來做生意。
構建服務團隊、形成服務基因,對創業公司及其背後的投資機構的耐心和定力來說,是不小的考驗。
與之相比,大廠在長期走向ToB/ToG市場的過程中,已經經歷了客戶的捶打,鍛煉出了更加成熟的服務鐵軍,也證明了自身的定力。
以百度爲例,對於不同行業,有深入了解客戶的交付、運維和保障專屬團隊,在大模型落地應用時,能夠給予更具針對性的方案,從而減少無效支出,讓大模型更好地幫助企業提質增效。
大模型廠商不能一心只想“賺快錢”,要沉下心來走向產業深處。同樣的,企業引入大模型也不能一心只“圖便宜”,要從智能化轉型升級的這個生命周期出發算總账,綜合考慮改造、交付、運維等多項成本。

大模型強大的理解能力和泛化能力,會加速產業智能化的進程,也讓AI企業和創業公司發現了新的機會。
就像啤酒總是伴隨着泡沫,在一擁而上的大模型創投熱潮中,創業公司和企業客戶也很容易陷入“速成幻覺”。
大模型走向產業的長路,更需保持冷靜和理性,警惕“爛尾”風險。希望大家真正飲下的,是用時間和技術沉澱的精釀,而非隨時可能消失的“泡沫”。
原文標題 : 大模型應用,必須警惕“速成幻覺”
標題:大模型應用,必須警惕“速成幻覺”
地址:https://www.utechfun.com/post/242902.html