端到端,還在卷什么?
近日,特斯拉發布了其“完全自動駕駛”軟件的最新版本FSDV13.2並完成首批交付,此次更新新增停車啓動、自動換擋、目的地自動泊車等功能,特斯拉自動駕駛工程師Arek Sredzki指出,該系統的端到端網絡現在允許車輛將乘客從一個停車位運送到另一個停車位 (P2P)。
特斯拉FSD的每一次重大更新,都引得各大智駕玩家第一時間的關注,一如2024年年初,特斯拉推送FSD V12的測試版本,將城市街道駕駛的軟件棧升級爲單一的端到端神經網絡。這一變化帶來的“風暴”,在遠隔重洋的中國,同樣掀起一股端到端的技術熱潮。
目前,一些致力於在自動駕駛領域取得領先地位的車企和智駕供應商,已經开始將端到端技術放在其宣傳的C位。
不出意外的是,對於“智駕第一梯隊”這一名頭,各大玩家抱有極大的興趣。就在2024年,湧現了一批號稱進入第一梯隊的車企或智駕供應商,無論其技術和產品能力有多花哨,端到端都成爲其中必不可少的一個關鍵詞。
端到端究竟有怎樣的“魔力”,而又有怎樣的貓膩呢?
端到端的路徑差異
端到端與傳統自動駕駛算法的主要差別在於系統架構和數據處理方式。傳統自動駕駛算法通常採用模塊化部署策略,將感知、預測、規劃和控制等功能劃分爲獨立的模塊,每個模塊獨立處理特定任務,信息逐級傳遞並可能被過濾或抽象,這種方式雖然結構清晰但存在誤差累積和信息丟失的問題。
而端到端架構則將整個駕駛過程視爲一個整體,通過一個統一的神經網絡模型直接從輸入的傳感器數據(如圖像、雷達信號等)映射到輸出的車輛控制指令,簡化了系統結構,減少了信息傳遞過程中的誤差,提高了系統的整體性和穩定性。
相較而言,端到端算法更側重於數據驅動,通過大規模數據集的訓練來優化模型性能,而傳統算法則更依賴於規則和有限的場景數據。
用一種比較通俗的說法,傳統的自動駕駛算法就像是分步驟做蛋糕,每一步都有專門的廚師負責,比如一個人負責打蛋,一個人負責加糖,另一個人負責攪拌,最後再由一個人來烤制。
在這種模式下,每個廚師都要把自己的工作做到最好,但過程僵化,他們之間可能不太知道其他人在做什么,信息傳遞可能出現偏差,有時候前面的廚師出了點小錯,後面的廚師可能沒法及時發現和調整,也浪費了時間。
而端到端則像是有一個特級大廚,他能夠從准備原料开始,一直到蛋糕出爐,都親自掌控。這個大廚不需要別人告訴他每一步該怎么做,他自己就能根據整個蛋糕的最終樣子來決定現在應該做什么。這樣一來,他就能更好地協調整個過程,減少錯誤,並且能快速學習升級調整,做出更符合要求的“食物”。
按照樸素的想法來看,既然已經切換到端到端的技術競爭,那就從感知到決策規劃一步到位,而在實踐的過程中,行業已經出現了所謂的one model一體化端到端和分段式端到端的路徑選擇差異。
一段式方案從感知到預測規劃無縫銜接,確保信息的完整傳遞,避免了多段式方案中可能出現的信息丟失問題。並且由於所有處理步驟集成在一個模型中,系統的整體響應速度可能會更快,這對於實時性要求極高的自動駕駛場景尤爲重要。但一旦中間出現問題,整個系統就像一個“黑匣子”,難以進行精確調試。所有的處理步驟都緊密耦合在一起,使得問題的定位和解決變得更加復雜。
而“分段式端到端”,或叫“模塊化端到端”,通常將自動駕駛系統的感知和決策規劃兩個模塊分开,並在中間嵌入人工接口,以實現更靈活和可擴展的系統設計,但仍然保持端到端的整體性。值得注意的是,無論是分段式端到端還是一體式端到端方案,都實現了從基於規則的優化向數據驅動的擬合的轉變。這一轉變使自動駕駛系統從依賴機械規則开發代碼的模式,進化到了基於神經網絡的經驗直覺模式。
但在一些觀點看來,分段式端到端的上限會更低。商湯絕影CEO、商湯科技聯合創始人、首席科學家王曉剛更曾直言:“‘兩段式’方案就算再做10年,也成不了自動駕駛的‘ChatGPT’。”
前不久,黑芝麻智能公布其端到端算法參考模型,黑芝麻智能也指出:“現階段量產的端到端系統,相當一部分採用了分段式架構,即將端到端系統分成幾個不同的模塊級聯而成。雖然這些模塊也使用AI模型進行工作,但各模塊之間仍存在人爲定義的接口來傳輸數據,這就必然導致有一定的信息損失,加上不同模塊經常採用獨立訓練的模式,其效果並非全局最優。”
黑芝麻智能的端到端智駕系統,採用了One Model的架構。一端可輸入攝像頭、激光雷達、4D毫米波雷達、導航地圖等信息,另一端直接輸出駕駛決策所需要的信息,即本車的預期軌跡。
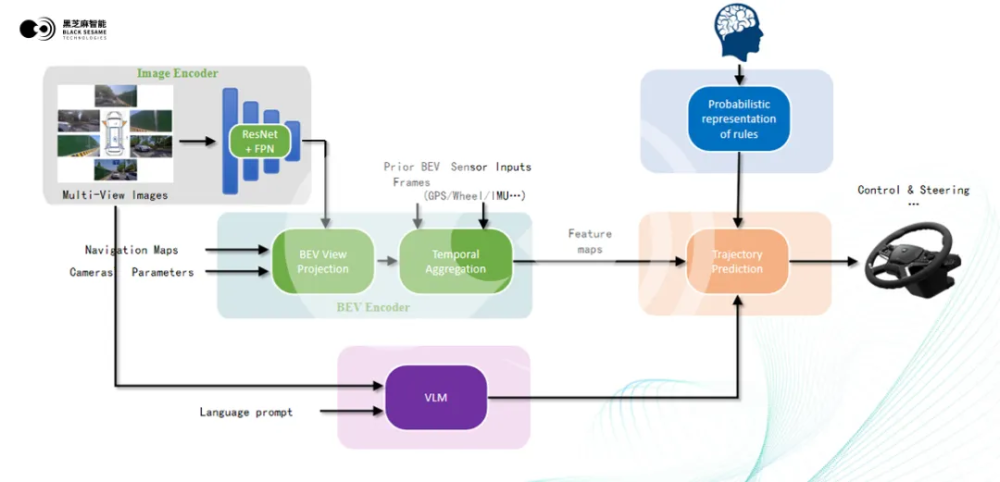 圖源:黑芝麻智能
圖源:黑芝麻智能
目前,大部分行業人士認爲,一段式端到端开發難度較大,但一旦模型訓練完成,能力會非常強大,能夠全面理解和應對復雜場景。而分段式端到端,技術復雜度相對較低,更容易逐步推進和實現,也有可能適合當前技術水平和資源條件。
就實際部署狀況來看,聲稱已部署或即將部署一段式端到端的車企和供應商包括Momenta、智己、廣汽豐田、理想、商湯科技、元戎啓行等,兩段式的代表則有小鵬、極氪,以及華爲鴻蒙系等玩家。
今年10月,智己宣布攜手Momenta,聯合打造“一段式端到端直覺智駕大模型”,此“一段式端到端直覺式智駕大模型”,基於“長短期記憶模式”獨特架構打造,據介紹其能將模型訓練成本節省10-100倍,同時大幅提升迭代速度。
 圖源:智己
圖源:智己
據Momenta CEO曹旭東透露,Momenta在去年已經實現了兩段式端到端,感知的端到端和規控的端到端,今年上半年又實現了一段式端到端。
博世智能駕控中國區總裁吳永橋告訴蓋世汽車,從兩段式端到端逐步過渡到一段式端到端,最終實現世界模型的應用,這一路线圖逐漸成爲業內共識。能夠按照這一路线順利發展下去的關鍵在於資金支持和長期战略定力。
據吳永橋判斷,到明年,在國內應該只有1-2家企業能夠實現一段式端到端。
從VLM到VLA
爲進一步提升端到端系統決策的准確性和靈活性,目前,行業裏流行的做法是端到端+VLM架構。
因爲駕駛時需要多模態的感知交互系統,用戶的視覺、聽覺以及周圍環境的變化,甚至個人情感的波動,都與駕駛行爲密切相關,所以端到端+VLM的技術架構中,端到端系統負責處理感知、決策和執行的全過程,而VLM則作爲輔助系統,提供對復雜交通場景的理解和語義解析。
這種架構下,兩個模型相對獨立工作,VLM主要在特定情況下爲端到端系統提供建議或補充信息。
以理想端到端與VLM相結合的雙系統架構方案爲例,其基於丹尼爾·卡尼曼(Daniel Kahneman)在《思考,快與慢》中提出的人類兩套思維系統理論,將端到端系統(相當於系統1)與VLM視覺語言模型(相當於系統2)融合應用於自動駕駛技術方案中,旨在賦予車端模型更高的性能上限和發展潛力。
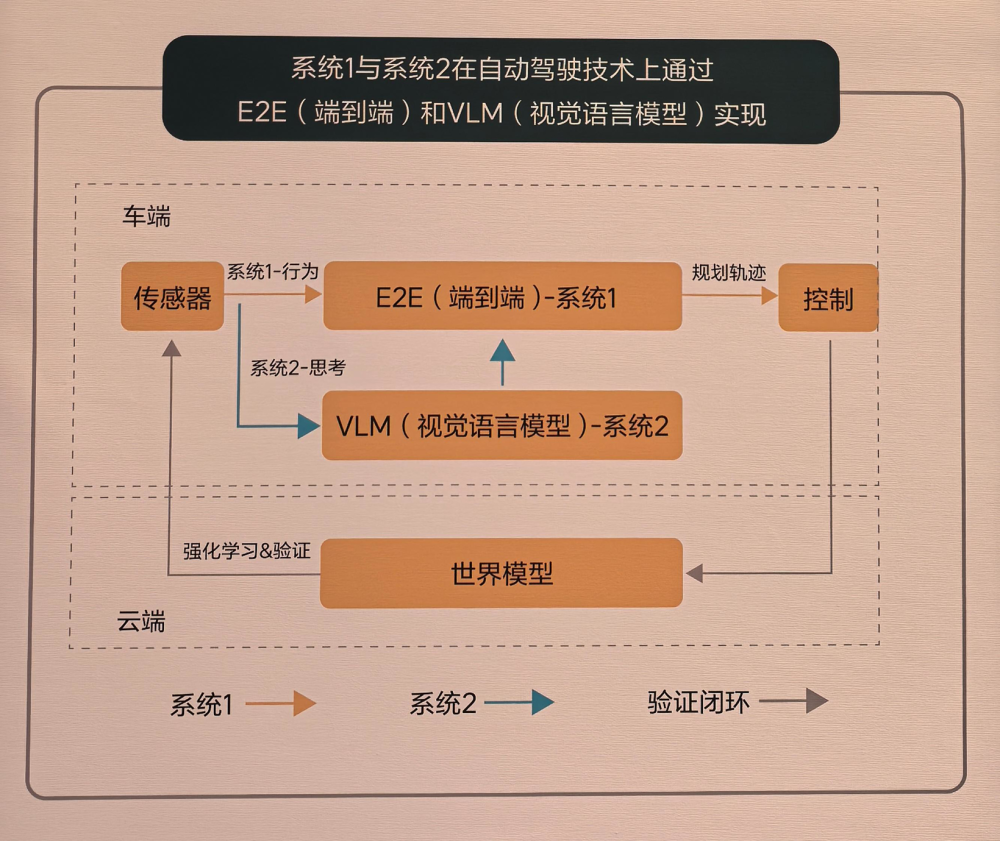
其中,系統1,即端到端模型,是一種直覺式、快速反應的機制,它直接從傳感器輸入(如攝像頭和激光雷達數據)映射到行駛軌跡輸出,無需中間過程,是One Model一體化的模型。系統2,則是由一個22億參數的VLM視覺語言大模型實現,它的輸出給到系統1綜合形成最終的駕駛決策。
理想方面表示,VLM整體的算法架構由一個統一的Transformel模型組成,將提示詞(Prompt)文本進行Tokenizer編碼,然後將前視120度和30度相機的圖像以及導航地圖信息進行視覺信息編碼,通過圖文對齊模塊進行模態對齊,統一交給Transformer模型進行自回歸推理。
與此同時,許多觀點認爲端到端+VLA是端到端+VLM的下一個階段。端到端+VLA的技術架構將端到端系統與多模態大模型更徹底地結合,形成一個統一的模型框架。在這種架構下,多模態大模型不僅包含視覺和語言處理能力,還融入了動作控制,使得整個系統能夠更全面地理解和響應復雜的駕駛環境。
元戎啓行CEO周光告訴蓋世汽車,VLM可以想象成一個新手司機在开車,旁邊有個教練通過語言不斷指導他如何駕駛,比如“左轉”、“減速”等。這就像當前的端到端1.0版本,雖然比完全由新手獨自駕駛更安全一些,但並不是最佳方案。
而VLA則相當於讓教練親自來开車,顯然這種方式比學員跟着教練學要更加高效和安全。簡而言之,從VLM到VLA的進步就像是從有人指導的初學者變成了經驗豐富的老手直接操作,後者相對更爲先進且可靠。
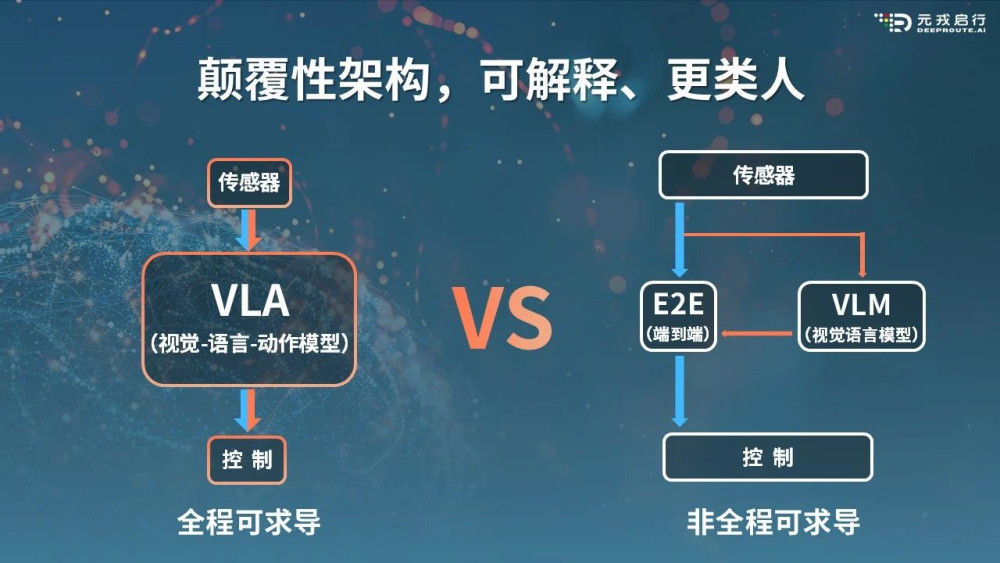 圖源:元戎啓行
圖源:元戎啓行
“VLM到VLA最大的不同可能在於推理能力,尤其是在時間層面的推理。例如,基於規則的系統可能只有1秒的推理能力,端到端1.0可能有7秒,而VLA則能達到幾十秒的推理能力。”周光說到。據悉,元戎啓行將基於英偉達Thor芯片進行VLA模型的研發,模型預計將於2025年正式推出。
不過,开發端到端+VLA模型顯然更需要大量的資源投入,包括算法研發、數據收集與處理、模型訓練等,這會增加企業的研發成本。現在許多企業採取逐步推進的策略,先在現有技術上進行優化和完善,再決定是否逐步引入新的技術元素。
理想汽車智能駕駛技術規劃高級總監文治宇透露:“目前我們的研發團隊和數據團隊在做相關的嘗試,是不是有可能幫助解決一些智能駕駛的問題。關於這個方向我們後續也會持續跟進,也期待未來幾年行業能夠一起取得的進展。”
數據發生器:世界模型
盡管切換到端到端帶來的好處行業是普遍認可的,但是由此帶來的挑战也是顯而易見的。其中首要的是對數據要求的高漲。商湯絕影指出,端到端智駕模型對於高質量數據的需求呈指數級的增長。然而,受限於高階智駕的量產規模、算力資源,目前大多數車企和智駕公司都面臨相同的問題,即高質量駕駛數據的獲取難度大、效率低、成本高。
王曉剛說到:“智駕高端局的競爭不止是車端模型的比拼,端到端的決战,战場在雲端。”爲此,商湯絕影在前不久升級發布了“开悟”世界模型。
 圖源:商湯絕影
圖源:商湯絕影
據介紹,“开悟”世界模型,可以滿足端到端模型訓練和仿真對於數據質量的高要求。可以支持多樣化的自動駕駛場景及Corner case的可控生成。在真實的基礎上,开悟生成的場景視頻,時間最長爲150秒、分辨率可達1080P、視角可以實現11V。
在這種情況下,世界模型在自動駕駛算法的开發體系中更多以數據生成器的角色存在。
今年的NIO IN 2024蔚來創新科技日上,蔚來也發布了其智能駕駛世界模型——NWM。該模型是一個具有全量理解數據、長時序推演和決策能力的智能駕駛世界模型。它能夠在100毫秒內推演出216種可能發生的場景,並尋找到最優決策。
 圖源:蔚來
圖源:蔚來
理想也在運用雲端世界模型對其快慢雙系統進行能力的訓練和考試,從而使這套系統能夠快速迭代。
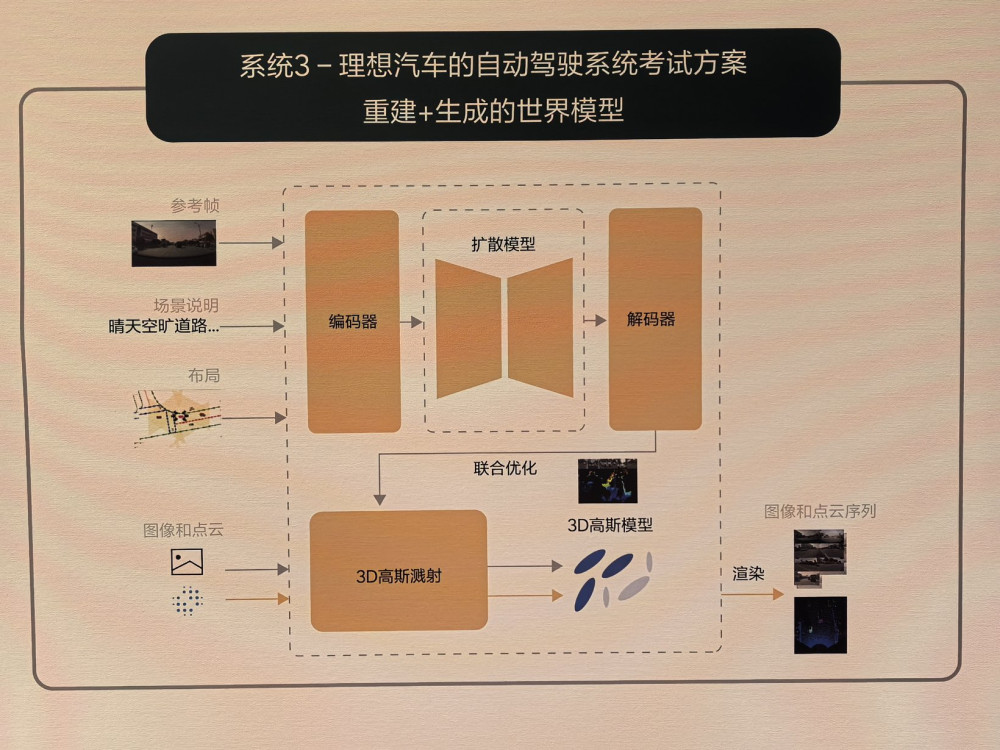
而在去年的計算機領域的國際頂級會議 CVPR 上,特斯拉 AI負責人Ashok Elluswamy早已明確提到,特斯拉正在試圖構建一個更加通用的世界模型,它能夠預測未來,能夠幫助神經網絡自主學習,能夠像一個神經網絡模擬器發揮作用,甚至能夠以AI的方式生成3D空間。
Ashok Elluswamy強調,特斯拉之所以能夠構建上述基礎大模型,主要得益於特斯拉擁有龐大的數據體量和強大的算力基礎。
值得注意的是,端到端對算力的要求可能並沒有想象的那般龐大,周光指出,端到端跟VLA的算力要求沒有語言大模型那么大,因爲它們本身是要部署到端側的AI。“今天我們講的車端的端到端+VLA跟真正的大語言模型比起來,只是個小網絡。”周光說到。
盡管並非所有企業都有特斯拉一般的數據和算力規模,但並沒有打消諸多玩家的競爭積極性,周光坦言:“算力、車隊數量、數據等對系統能力的提升很關鍵,但前提是算法足夠優秀,關鍵點還是企業的模型能力。”
端到端的研發推進固然困難重重,諸多企業也正在拿出自家的拿手好戲尋求解決方案,至於對於大模型可解釋性方面的顧慮,似乎已經愈發消減。與能夠顯著提升的性能相比,可解釋性成爲一個次要考量因素,而且,目前各家實行的端到端方案,基本上都有兜底規則進行安全冗余。
奇瑞汽車副總經理&大卓智能CEO谷俊麗表示:“我們面臨的是越來越大的AI模型,它需要龐大的數據和算力支持,所有核心研發的能力將變成三大要素:數據、雲計算以及頂級AI科學家。其他則是圍繞量產體系的構建,更重要的是產品定義的能力。”
今年奇瑞全球創新大會上推出的智駕大模型,也是通過雲端世界模型生成豐富場景,形成感知大模型加規劃大模型模擬人腦行爲決策,預計將實現兩段式端到端方案量產上車:2025年進一步整合感知大模型和規劃大模型實現一段式端到端大模型量產上車;到2027年實現基於VLA多模態大模型量產。
可以預見的是,端到端的落地或將促進其依賴的上遊工具鏈和芯片等技術的加速發展,以及進一步提升了數據和AI人才的重要性,可能會催生新的產業分工和商業模式。
至於端到端是否就是自動駕駛的終極方案,行業衆說紛紜。王曉剛也曾對蓋世汽車說到:“端到端技術並非終點,未來還有通用人工智能、多模態等新技術不斷湧現和突破。”
這一輪端到端的技術競爭,無論是卷數據、卷算法、卷人才,或許只是爲了在愈發猛烈的淘汰賽中,卷出一個未來。
(本文來自於蓋世汽車Gasgoo)
標題:端到端,還在卷什么?
地址:https://www.utechfun.com/post/451369.html