來源:半導體行業觀察
當超大規模計算設備和雲計算構建者規模較小、Arm 集體未能衝擊數據中心且 AMD 尚未走上復興之路時,英特爾控制着新計算引擎進入數據中心的節奏。
本周,英特爾首席執行官帕特·基辛格被罷免,亞馬遜網絡服務公司在拉斯維加斯舉辦了年度 re:Invent 大會,有 60,000 人親臨現場,400,000 人在线參會,由此可以看出,誰在超大規模和雲計算提供商的技術推廣速度上佔據主導地位,這一點非常明顯。
他們還能控制何時不推出新技術,因爲他們不必像其他芯片設計公司那樣有新產品可以出售。他們不像英特爾、AMD 和 Nvidia 那樣向 ODM 和 OEM 銷售計算引擎,而是創建虛擬化實用程序並直接向客戶出售原始容量的訪問權限。從很多方面來看,這是一個更加順暢和容易的業務。
如果您昨晚深夜聆聽了 AWS 公用計算高級副總裁 Peter DeSantis 的开幕主題演講,以及今天 AWS 首席執行官 Matt Garman 和母公司亞馬遜首席執行官 Andy Jassy 的主題演講,那么您可能和我們一樣,正在等待有關未來計算引擎的一些公告,例如 Graviton5 服務器 CPU、Inferentia3 AI 推理加速器或 Trainium3 AI 訓練加速器。
可惜的是,除了 Garman 的一張幻燈片展示了 Trainium3 採用 3 納米工藝蝕刻而成(大概是來自台灣半導體制造公司)之外,其性能是 Trainium2 的兩倍,並且每瓦性能比 Trainium2 高出 40%,並沒有關於未來 AWS 將推出自主研發硅片的談論。
Garman 補充說,Trainium3“將於明年晚些時候推出”,這可能意味着它將在 2025 年 re:Invent 大會上推出。早在 6 月,就有傳言稱 AWS 高管證實 Trainium3 將突破 1,000 瓦,這絲毫不會讓我們感到驚訝。Nvidia 的頂級“Blackwell”B200 GPU 的峰值功率爲 1,200 瓦。
這仍然比我家裏其他人使用的吹風機的瓦數要低,而且四十多年來我都不需要吹風機了。所以我們還沒有感到驚慌失措。但它也有十幾個白熾燈泡,這是一個奇怪的想法,特別是如果你從來沒有等到它們冷卻足夠長的時間再把它們拿出來,而我們通常沒有這樣做。
我們有點驚訝,上個月的 SC24 超級計算會議上,我們還沒有看到針對 HPC 應用的 Graviton4E 深度分類,這將與 AWS在 2021 年 11 月對普通 Graviton3和2022 年 11 月對增強型 Graviton3E所做的一樣。Graviton4 可以說是市場上最好的基於 Arm 的服務器 CPU 之一,當然也是最適合任何人使用的 CPU,它於 2023 年 11 月問世,並於今年 9 月進行了內存提升。
AWS 對其 CPU、AI 加速器和 DPU 的年度發布節奏幾乎沒有任何壓力,如果你仔細查看 Nvidia 和 AMD 的 GPU 路线圖,就會發現它們的核心產品仍然每兩年發布一次,第二年會針對第一年發布的 GPU 進行內存升級或性能調整。
AWS 的硅片开發節奏看起來是兩年,中間會有一些波動。Graviton1 實際上是增強版的“Nitro”DPU 卡,它不算數。正如 DeSantis 在 2018 年推出 Graviton1 時的主題演講中所說,Graviton1 是“向市場發出的信號”,旨在測試客戶終於准備好在數據中心使用 Arm CPU 的想法。2019 年,隨着 Graviton2 的推出,AWS 採用了台積電的現代 7 納米工藝,並使用 Arm Ltd 的“Ares”N1 內核創建了一款 64 核設備,該設備可以完成有用的工作,而且與在 AWS 雲上運行的英特爾和 AMD 的 X86 CPU 相比,性價比高出 40%。
兩年後,Graviton3 問世,它採用了 Arm 功能更強大的“Zeus”V1 內核,盡管“只有”64 個內核,但可以突然承擔更大的任務。兩年後,Graviton4 問世,我們認爲它縮小到了 4 納米 TSMC 工藝,將 96 個“Demeter”V2 內核塞進插槽,與十幾個 DDR5 內存控制器搭配使用,內存帶寬爲 537.6 GB/秒。與 Graviton3 相比,Graviton4 的單核性能提高了 30%,內核數量增加了 50%,一般來說,性能提高了 2 倍,根據我們在此處的定價分析,性價比提高了 13% 到 15%。在實際基准測試中,Graviton4 有時可提供 40% 以上的性能
坦率地說,AWS 必須花兩年時間才能從處理器設計中收回這筆巨額投資。因此,在本周的 re:Invent 2024 大會上期待任何有關 Graviton5 的消息是不合理的——如果不是貪婪的話。不過,DeSantis、Garman 或 Jassy 還是可以透露一些消息的。
AWS 的高層確實在主題演講中提供了一些有關 Graviton 的有趣統計數據。AWS 計算和網絡服務副總裁 Dave Brown 展示了這張非常有趣的圖表,它在一定程度上解釋了爲什么英特爾最近幾個季度的財務狀況如此糟糕:

粗略地說,AWS 四項核心服務(Redshift Serverless 和 Aurora 數據庫、Kafka 的托管流和 ElastiCache 搜索)下約一半的處理都在 Graviton 實例上運行。在剛剛過去的 Prime Day 購物活動中,亞馬遜租用了超過 250,000 台 Graviton 處理器來支持該操作。
“最近,我們達到了一個重要的裏程碑,”布朗繼續說道。“在過去兩年中,我們數據中心中超過 50% 的 CPU 容量都來自 AWS Graviton。想想看。Graviton 處理器的數量比所有其他類型的處理器加起來還要多。”
這正是微軟多年前所說的想要做的事情,也正是我們所期望的。從長遠來看,X86 是一個具有傳統價格的傳統平台。就像之前的大型機和 RISC/Unix 一樣。RISC-V 最終可能會對 Arm 架構產生這種影響。(我們會看到,但具有开源和可組合塊且有專家監督的开源 ISA 似乎是一條道路。看看 Linux 如何徵服操作系統並將 Windows Server 變成傳統平台。)
Garman 表示,這讓我們大致了解了 AWS 內部 Graviton 服務器群的規模:“Graviton 正在瘋狂增長。讓我們來看一下背景。2019 年,整個 AWS 的業務價值爲 350 億美元。如今,AWS 集群中運行的 Graviton 數量與 2019 年所有計算量一樣多。這是相當令人印象深刻的增長。”
我們很想知道 2019 年服務器機群的規模以及現在的規模。我們認爲可以誠實估計的是,Graviton 服務器機群的增長速度比 AWS 本身更快,而且可能差距很大。這對英特爾的傷害比對 AMD 的傷害要大得多,因爲多年來 AMD 的 X86 服務器 CPU 一直比英特爾更好。
Trainium將給AMD和Nvidia帶來一些壓力
Garman 之所以會談論 Trainium3,唯一的原因是 AI 訓練(以及日益增長的推理)對高性能計算的需求增長速度遠遠超過任何人能夠提供的計算引擎。隨着 Nvidia 加大其“Blackwell”B100 和 B200 GPU 的投入,以及 AMD 明年擴大其“Antares”MI300 系列的規模,如果 AWS 希望客戶能夠放心地將他們的 AI 工作負載移植到 Trainium,它就不能表現出不致力於加速其 AI 芯片的決心。因此,才有了 Trainium3 的傳聞。
也就是說,我們確實希望 AWS 能在明年 11 月或 12 月 re:Invent 大會召开之前對 Trainium3 發表一些其他評論,因爲其他所有公司(谷歌和微軟是最重要的公司)都將在 2025 年對其自主研發的 AI 加速器發表一些評論。
與 Graviton 系列一樣,我們認爲 Trainium 系列從現在开始也將以兩年爲周期推出。這些設備價格昂貴,AWS 必須將 Trainium 开發成本分攤到盡可能多的設備上,才能實現財務目標——就像 Graviton CPU 一樣。與 Gravitons 一樣,我們認爲 AWS 一半的 AI 訓練和推理能力將在其自主研發的 Annapurna Labs 芯片上實現的一天並不遙遠。從長遠來看,這對 Nvidia 和 AMD 來說意味着麻煩。尤其是如果谷歌、微軟、騰訊、百度和阿裏巴巴都做同樣的事情的話。
AWS 不會傻到試圖在 GPU 加速器市場與 Nvidia 競爭,但就像谷歌的 TPU、SambaNova 的 RDU、Groq 的 GroqChip 以及 Graphcore 的 IPU 一樣,這家雲計算構建者絕對認爲它可以構建一個收縮陣列來進行差異化的 AI 訓練和推理,並爲雲客戶增加價值——並且與僅僅購买 Nvidia GPU 並完成它相比,它可能會有更好的利潤率或至少更多的控制權。
正如我們上面指出的那樣,AWS 高管並沒有對 Trainium3 發表太多評論,但他們對 Trainium2 在 UltraServer pod 中的 Trn2 實例中可用感到非常興奮。
早在 2023 年 12 月,去年的 re:Invent 大會之後,我們就詳細介紹了 Trainium2 及其前身 Trainium1 以及用於 AI 推理的配套 Inferentia1 和 Inferentia2 加速器的架構。(您可以在此處閱讀。)本周,AWS 進一步介紹了使用 Trainium2 加速器的系統的架構,並展示了它爲基於它們擴展和擴展其 AI 集群而構建的網絡硬件。
那么,讓我們做一些展示和講述。
以下是 DeSantis 展示 Trainium2 卡的情況:

正如我們去年指出的那樣,Trainium2 似乎有兩個芯片在單個封裝上互連,可能使用 NeuronLink 芯片到芯片互連,該互連基於用於將 Trainium1 和 Trainium2 芯片相互連接的結構互連,以便在其共享的 HBM 內存之間一致地共享工作。
Trainium2 服務器有一個頭節點,該節點帶有一對主機處理器(大概是 Graviton4,但 DeSantis 沒有說),並與三個 Nitro DPU 相連,如下所示:

下面是計算節點的頂視圖,前端有四個 Nitro,後端有兩個 Trainium2,採用無线設計以加快部署速度:

兩個交換機托架、一個主機托架和八個計算托架組成了 Trainium2 服務器,該服務器使用 2 TB/秒的 NeuronLink 電纜將 16 個 Tranium2 芯片互連成 2D 環面配置,每個設備上的 96 GB HBM3 主內存與所有其他設備共享。每台 Trainium2 服務器都有 1.5 TB 的 HBM3 內存,總內存帶寬爲 46 TB/秒(即每張 Trainium2 卡略低於 3 TB/秒)。此節點在密集 FP8 數據上的性能爲 20.8 千萬億次浮點運算,在稀疏 FP8 數據上的性能爲 83.3 千萬億次浮點運算。(AWS 在稀疏數據上的壓縮率爲 4:1,而 Nvidia 的“Hopper”和“Blackwell”GPU 的壓縮率爲 2:1,Cerebras Systems 晶圓級引擎的壓縮率爲 10:1。)
其中四台服務器互連,形成 Trainium2 UltraServer,該服務器在 64 個 AI 加速器上擁有 6 TB 的總 HBM3 內存容量,總內存帶寬爲 184 TB/秒。該服務器具有 12.8 Tb/秒的以太網帶寬,可使用 EFAv3 適配器進行互連。UltraServer 服務器在密集 FP8 數據上的運算速度爲 83.2 千萬億次,在稀疏 FP8 數據上的運算速度爲 332.8 千萬億次。
以下是 DeSantis 展示 Trn2 UltraServer 實例背後的硬件:

機架頂部埋着許多電线,後面有一對交換機,它們組成了 3.2 Tb/秒 EFAv3 以太網網絡的端點,該網絡將多個 Tranium2 服務器相互連接以創建 UltraServer pod,並將 pod 相互連接並與外界連接:

不要以爲這就是網絡的全部。如果你想運行大規模基礎模型,你需要的加速器遠不止 64 個。爲了將擁有數十萬個加速器的機器連接在一起,進行英雄訓練,AWS 設計了一種網絡結構(可能基於以太網),稱爲 10p10u,其目標是在整個網絡的延遲低於 10 微秒的情況下,提供每秒數十 PB 的帶寬。
10p10u 網絡結構機架的外觀如下:

上面的配线架中的布线非常復雜,因此 AWS 發明了一種光纖主幹電纜,其管理的電线數量壓縮了 16:1,因爲它將數百個光纖連接放在一根粗管中。這使得配线架更簡單,如下所示:

右側的接线架使用的是光纖主幹電纜,而且更加整潔,體積也更小。需要管理的連接和线路越少,錯誤就越少,這對於快速構建 AI 基礎設施至關重要。
據我們所知,這個 10u10p 網絡不僅專門用於 AI 工作負載,而且 AI 工作負載顯然正在推動其採用。DeSantis 展示了與 AWS 創建的舊以太網(可能速度較慢)相比,它的發展速度有多快。請看一看:
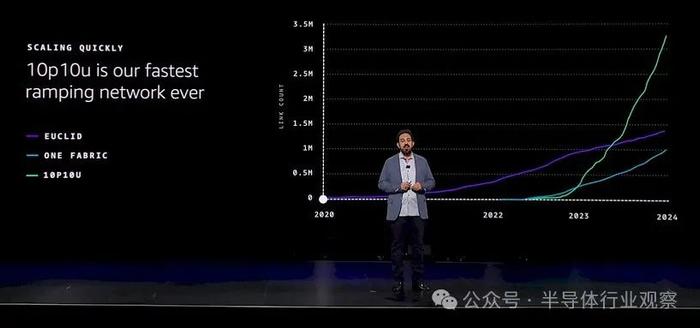
假設這是累積鏈接數,這是唯一有意義的計算,較舊的 Euclid 網絡結構(大概是 100 Gb/秒)在四年內逐漸增加到近 150 萬個端口。名爲 One Fabric 的網絡與 10u10p 網絡在 2022 年中期推出的時間大致相同,我們假設其中一個使用 400 Gb/秒以太網,而 10u10p 幾乎肯定基於 800 Gb/秒以太網。但這些都是猜測。One Fabric 有大約 100 萬個鏈接,而 10u10p 看起來有大約 330 萬個鏈接。
總而言之,Garmin 表示,與 AWS 雲上基於 GPU 的實例相比,Trn2 實例的性價比將提高 30% 到 40%。我們以前在哪裏聽說過這些數字?哦,對了……Graviton 在 AWS 雲上比 X86 具有性價比優勢。
當然,AWS 可以隨心所欲地擴大外部計算引擎和其自主研發引擎之間的差距。如果它希望 Trainium 在不久的將來成爲其 AI 訓練隊伍的一半,那么這可能是保持正確差距的正確方法。
最後一件事。作爲主題演講的一部分,DeSantis 和 Garman 都談到了 AWS 正在構建的代號爲 Project Ranier 的超級集群,以便 AI 模型合作夥伴 Anthropic(亞馬遜迄今已向其投入 80 億美元)擁有用於訓練其下一代 Claude 4 基礎模型的機器。Garman 表示,Project Ranier 將擁有“數十萬”個 Trainium2 芯片,其性能將是 Claude 3 模型所用機器的 5 倍。
參考鏈接
https://www.nextplatform.com/2024/12/03/aws-reaps-the-benefits-of-the-custom-silicon-it-has-sown/
特別聲明:以上文章內容僅代表作者本人觀點,不代表新浪網觀點或立場。如有關於作品內容、版權或其它問題請於作品發表後的30日內與新浪網聯系。標題:這些芯片,幹成了
地址:https://www.utechfun.com/post/451268.html