
8月27日消息,在近日召开的Hot Chips 2024大會上,美國AI芯片初創公司SambaNova首次詳細介紹了其新推出的全球首款面向萬億參數規模的人工智能(AI)模型的AI芯片系統——基於可重構數據流單元 (RDU) 的 AI 芯片 SN40L。
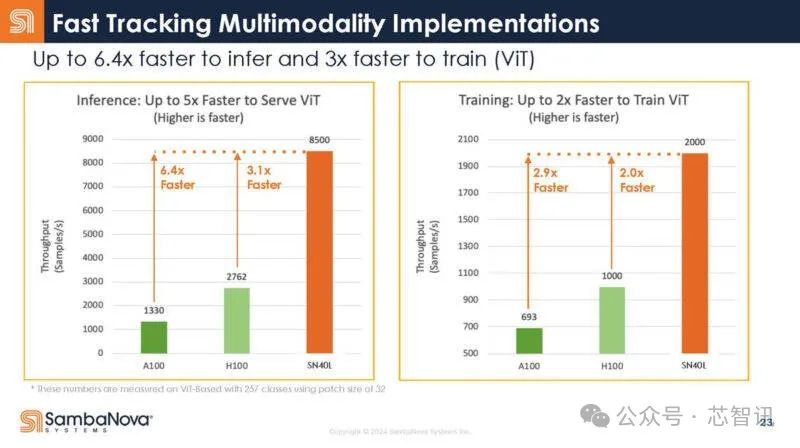
據介紹,基於SambaNova 的 SN40L 的8芯片系統,可以爲 5 萬億參數模型提供支持,單個系統節點上的序列長度可達 256k+。對比英偉的H100芯片,SN40L不僅推理性能達到了H100的3.1倍,在訓練性能也達到了H100的2倍,總擁有成本更是僅有其1/10。

SambaNova SN40L基於台積電5nm制程工藝,擁有1020億個晶體管(英偉達H100爲800億個晶體管),1040個自研的“Cerulean”架構的RDU計算核心,整體的算力達638TFLOPS(BF16),雖然這個算力不算太高,但是關鍵在於SN40L還擁有三層數據流存儲器,包括:520MB的片上SRAM內存,集成的64GB的HBM內存,1.5TB的外部大容量內存。這也使得其能夠支持萬億參數規模的大模型的訓練和推理。
SambaNova在推出基於8個SN40L芯片系統的同時,還推出了16個芯片的系統,將可獲得8GB片內SRAM、1TB HBM和24TB外部DDR內存,使得片上SRAM和集成的HBM內存之間的帶寬高達25.5TB/s,HBM和外部DDR內存之間的帶寬可達1600GB/s。高帶寬將會帶來明顯的低延時的優勢,比如運行Llama 3.1 8B模型,延時低於0.01s。

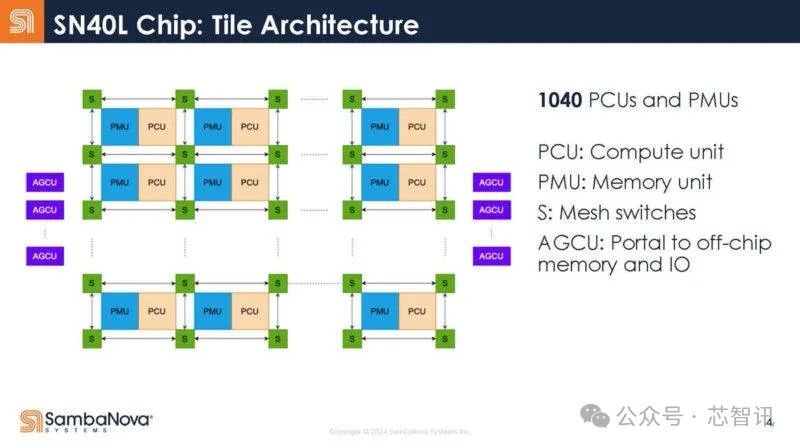
下圖是SambaNova SN40L的內部結構,包括:計算單元(PCU)、存儲單元(PMU)、網狀开關(S)、片外存儲器和IO(AGCU)。
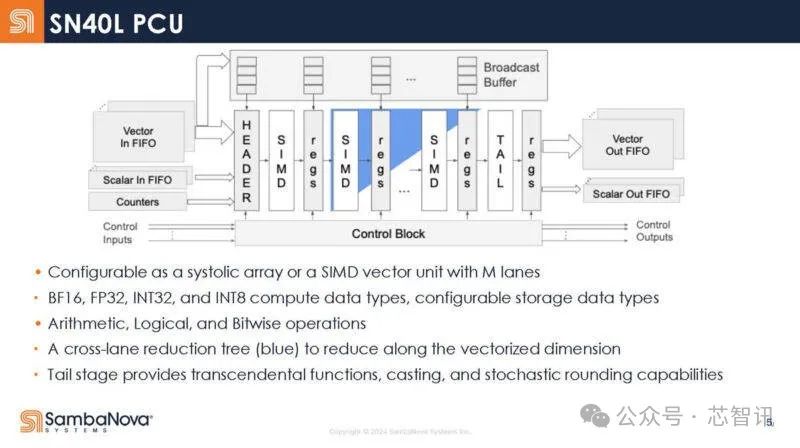
SN40L 內部的計算單元(PCU)的內部架構,它具有一系列靜態階段,而不是傳統的獲取/解碼等執行單元。PCU可以作爲流媒體單元(從左到右的數據)運行,藍色是交叉車道減少樹。在矩陣計算操作中,它可以用作收縮陣列。支持BF16、FP32、INT32、INT8等數據類型。
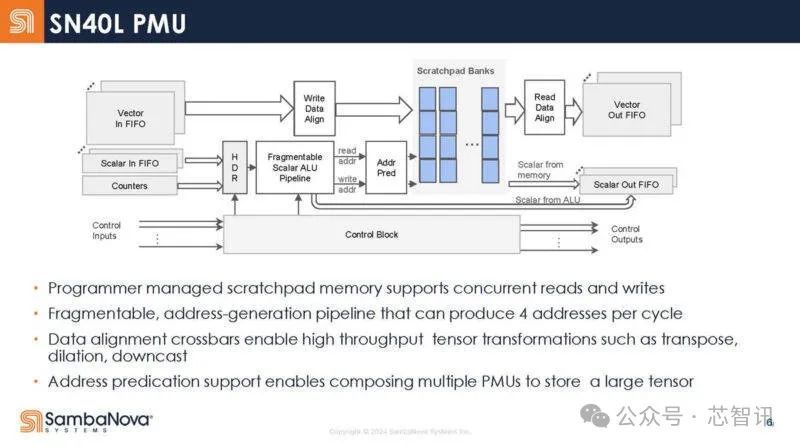
下圖是SN40L 的高級存儲單元框架圖。這些是可編程管理的暫存區,而不是傳統的緩存。
SN40L 的網狀網絡擁有三種物理網絡,包括矢量網絡、標量網絡和控制網絡。
AGCU單元用於訪問片外存儲器(HBM和DDR ),而PCU用於訪問片內SRAM暫存區。
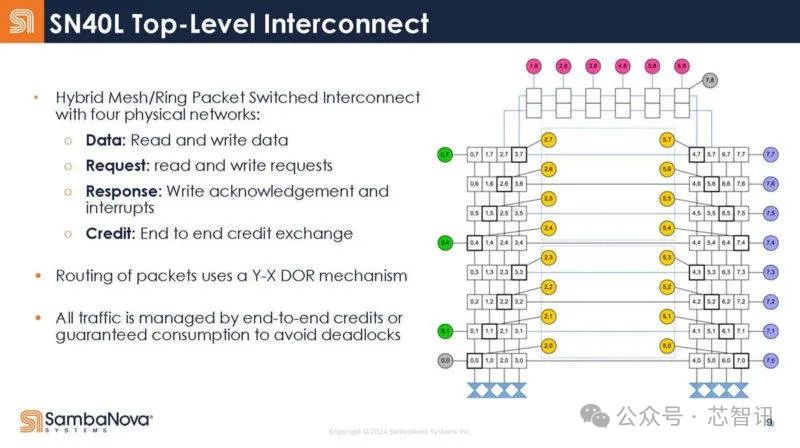
下圖是SN40L 的頂層互聯結構:
SN40L 的關鍵核心在於其可重構數據流架構,可重構數據流架構使其能夠通過編譯器映射優化各個神經網絡層和內核的資源分配。
下面是一個例子,說明Softmax是如何被編譯器捕獲,然後映射到硬件的。
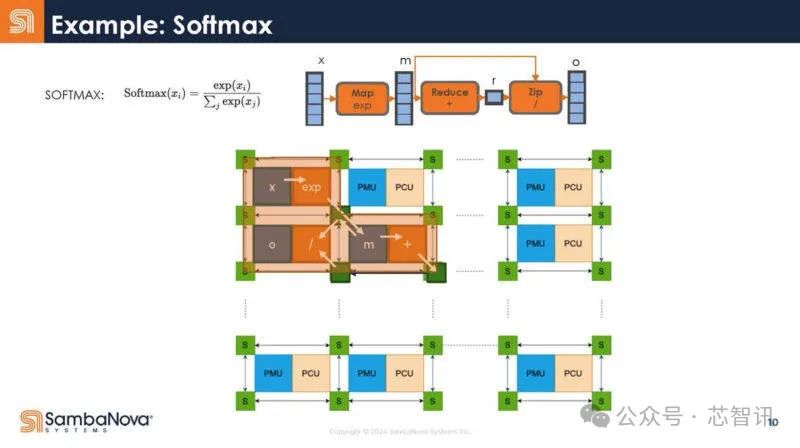
可以看到,將它映射到大語言模型(LLM)和生成式AI的Transformer模型,下面是映射。在解碼器內部,有許多不同的操作。
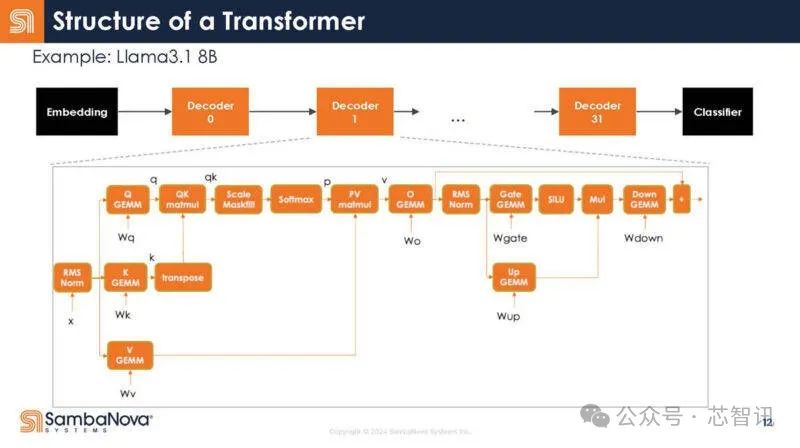
下圖是解碼器放大圖。每個方框內都是一個操作符。同時,通常可以運行多個操作符,並把數據保存在芯片上以便重用。

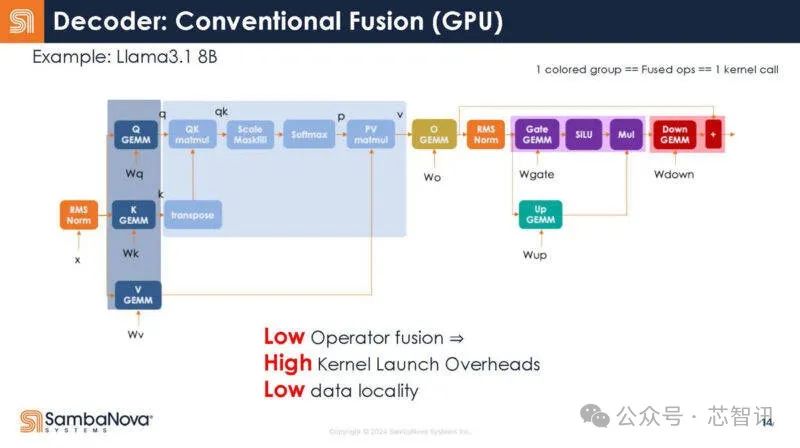
以下是SambaNova對運算符如何在GPU上融合的猜測,不過他們也指出這可能不准確。
在RDU中,整個解碼器是一個內核調用。編譯器負責這種映射。
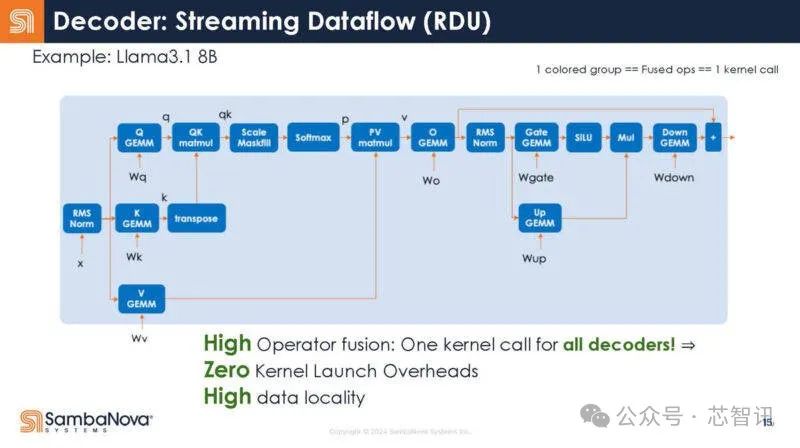
解碼器作爲RDU上的單個內核。

回到Transformer的結構,下圖展示了解碼器的不同功能。可以看到,每個函數調用都有啓動开銷。
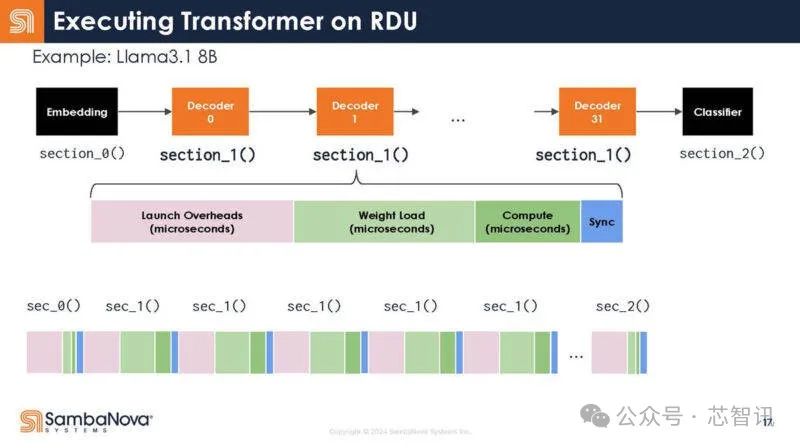
不是32個調用,而是寫成一個調用。
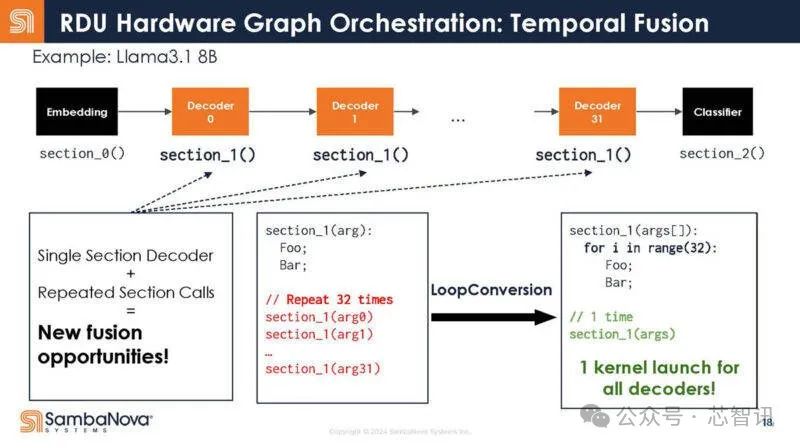
換句話說,這意味着調用开銷減少了,因爲只有一個調用,而不是多個調用。結果,增加了芯片對數據做有用工作的時間。
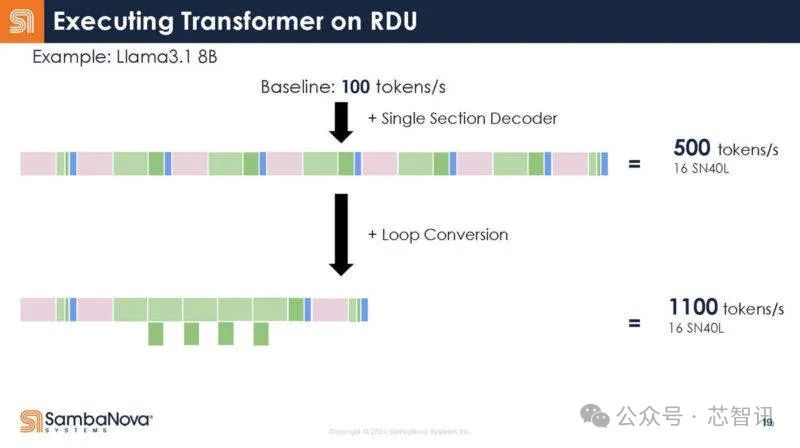
SambaNova 首席執行官兼創始人 Rodrigo Liang 表示:“借助數據流,你可以不斷改進這些模型的映射,因爲它是完全可重構的。因此,隨着軟件的改進,你獲得的收益不是增量的,而是相當可觀的,無論是在效率方面還是在性能方面。”
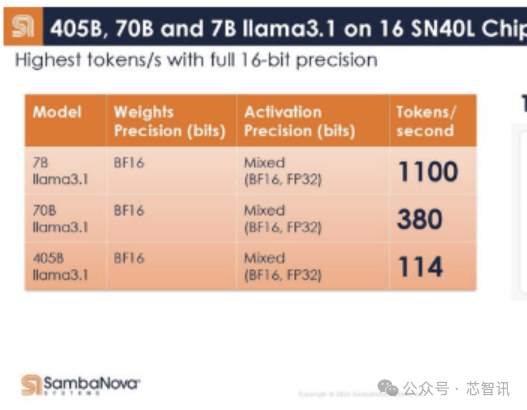
下面是SambaNova的16個SN40L芯片系統在Llama3.1 405B/70B/7B上的表現,在Llama 3.1 7B模型下,以完全的16bit精度運行,其每秒的Token生成數竟然高達1100個。這比此前Groq推出的基於LPU(號稱推理速度是英偉達GPU的10倍,功耗僅1/10)的服務器系統在Llama 3 8B上的最快基准測試結果每秒生成800個Token還要快。即使是在Llama3.1 405B模型上,以完全的16bit精度運行,16個SN40L芯片的系統每秒Token生成數也能夠高達114個。而在Llama 3.1 7B模型下,其每秒的Token生成數更是高達1100個。由於內存容量限制,與其最接近的競爭對手需要數百塊芯片來運行每個模型的單個實例,因爲 GPU 提供的總吞吐量和內存容量相對較低。
SN40L在Llama 3.1 70B模型上進行批量推理和吞吐量縮放表現,隨着批量大小的變化,吞吐量接近理想規模。
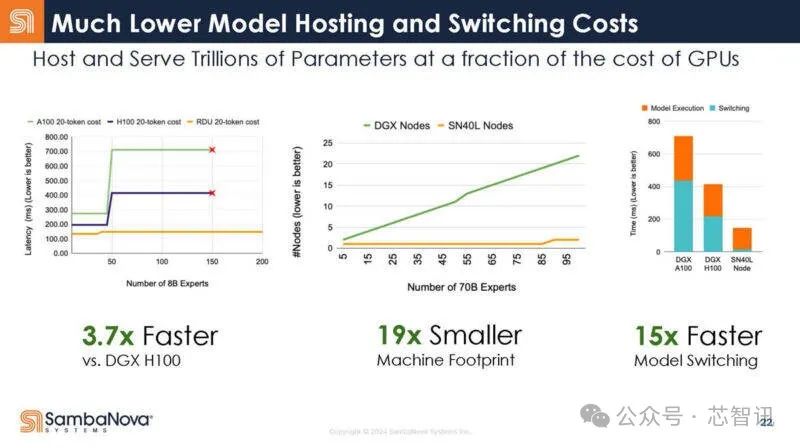
據SambaNova 介紹,基於8個SN40L芯片的標准AI服務器系統在運行80億參數的AI大模型時,速度達到了基於8張英偉達H100加速卡的DGX H100系統的3.7倍(每生成20個Token所耗費的時間),而整個系統所佔用的空間也只有DGX H100的1/19,模型切換時間也僅有DGX H100系統的1/15。
在芯片推理性能方面,SN40L達到了英偉達H100的3.1倍;在訓練性能方面,SN40L也達到了英偉達H100的2倍。
總結來說,SambaNova 可以在8個SN40L芯片的系統上運行數百個大模型(在16個SN40L芯片的系統上可以同時運行多達 1000 個 Llama 3 7B大模型),同時還能夠保持很快的響應速度,擁有完全精度。更爲關鍵的是,其總擁有成本比競爭對手低 10 倍(雖然未明確是哪款競品芯片,但從前面的對比來看,應該說的是H100)。
“SN40L的速度展現了Dataflow的魅力,它加速了 SN40L 芯片上的數據移動,最大限度地減少了延遲,並最大限度地提高了處理吞吐量。它比 GPU 更勝一籌——結果就是即時 AI,”SambaNova Systems 聯合創始人、斯坦福大學知名計算機科學家 Kunle Olukotun 表示。
值得一提的是,在基於SN40L芯片的系統之上,SambaNova 還構建了自己的軟件堆棧,其中包括今年2月28日首次發布的擁有1萬億參數的Samba-1 模型,也稱爲 Samba-CoE(專家組合),其使得企業能夠組合使用多個模型,也可以單獨使用,並根據公司數據對模型進行微調和訓練。
在芯智訊看來,SN40L相比目前的一些AI芯片來說,擁有着顯著的優勢,比如其可重構的數據流架構,可以調整硬件來滿足各類工作負載要求,使得其可以很好的處理圖像、視頻及文本等不同的數據類型,適合多模態AI應用。但是,相對於英偉達的GPU可以靈活的處理各種模型來說,SN40L在靈活性上還是要略遜一籌,因爲相關模型必須要經過專門的調整才能在其上面運行。而且,英偉達強大的CDUA生態對於其來說也是一大挑战。
不過,在AI模型參數越來越大,所需的芯片數量和資金成本越來越高的背景之下,SN40L在性能和成本上的優勢,以及可以輕松實現對於萬億參數大模型的支持,因此也有着與英偉達直接競爭的機會。或許正因爲如此,SambaNova也獲得了資本的青睞,目前已經累計獲得了超過10億美元的融資。
編輯:芯智訊-浪客劍
 海量資訊、精准解讀,盡在新浪財經APP
海量資訊、精准解讀,盡在新浪財經APP
標題:又一位英偉達"殺手"亮相:性能是H100數倍,成本僅1/10,支持萬億參數模型!
地址:https://www.utechfun.com/post/415401.html