文 | 智能相對論
作者 | 陳泊丞
今年以來,MoE模型成了AI行業的新寵兒。
一方面,越來越多的廠商在自家的閉源模型上採用了MoE架構。在海外,OpenAI的GPT-4、谷歌的Gemini、Mistral AI的Mistral、xAI的Grok-1等主流大模型都採用了MoE架構。
而在國內,昆侖萬維推出的天工3.0、浪潮信息發布的源2.0-M32、通義千問團隊發布的Qwen1.5-MoE-A2.7B、MiniMax全量發布的abab6、幻方量化旗下的DeepSeek發布的DeepSeek-MoE 16B等等也都屬於MoE模型。
另一方面,在MoE模型被廣泛應用的同時,也有部分廠商爭先开源了自家的MoE模型。前不久,昆侖萬維宣布开源2千億參數的Skywork-MoE。而在此之前,浪潮信息的源2.0-M32、DeepSeek的DeepSeek-MoE 16B等,也都紛紛开源。
爲什么MoE模型如此火爆,備受各大廠商的青睞?在开源的背後,MoE模型又是以什么樣的優勢使各大主流廠商成爲其擁躉,試圖作爲改變AI行業的利器?
MoE模型火爆的背後:全新的AI解題思路
客觀來說,MoE模型的具體工作原理更接近中國的一句古語“術業有專攻”,通過把任務分門別類,然後分給多個特定的“專家”進行解決。
它的工作流程大致如此,首先數據會被分割爲多個區塊(token),然後通過門控網絡技術(Gating Network)再把每組數據分配到特定的專家模型(Experts)進行處理,也就是讓專業的人處理專業的事,最終匯總所有專家的處理結果,根據關聯性加權輸出答案。
當然,這只是一個大致的思路,關於門控網絡的位置、模型、專家數量、以及MoE與Transformer架構的具體結合方案,各家方案都不盡相同,也逐漸成爲各家競爭的方向——誰的算法更優,便能在這個流程上拉开MoE模型之間的差距。
像浪潮信息就提出了基於注意力機制的門控網絡(Attention Router),這種算法結構的亮點在於可以通過局部過濾增強的注意力機制(LFA, Localized Filtering-based Attention),率先學習相鄰詞之間的關聯性,然後再計算全局關聯性的方法,能夠更好地學習到自然語言的局部和全局的語言特徵,對於自然語言的關聯語義理解更准確,從而更好地匹配專家模型,保證了專家之間協同處理數據的水平,促使模型精度得以提升。
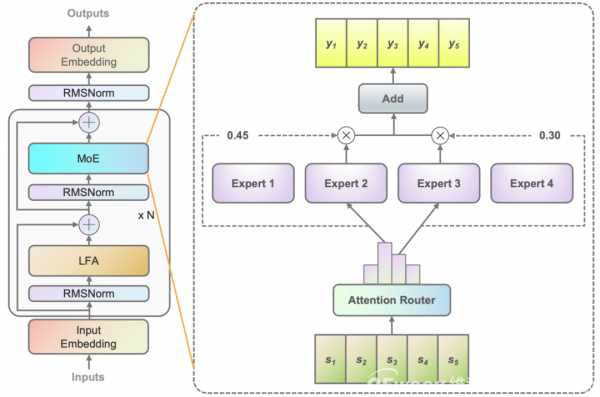
基於注意力機制的門控網絡(Attention Router)
拋开目前各家廠商在算法結構上的創新與優化不談,MoE模型這種工作思路本身所帶來的性能提升就非常顯著——通過細粒度的數據分割和專家匹配,從而實現了更高的專家專業化和知識覆蓋。
這使得MoE模型在處理處理復雜任務時能夠更准確地捕捉和利用相關知識,提高了模型的性能和適用範圍。因此,「智能相對論」嘗試了去體驗天工3.0加持的AI搜索,就發現對於用戶較爲籠統的問題,AI居然可以快速的完成拆解,並給出多個項目參數的詳細對比,屬實是強大。
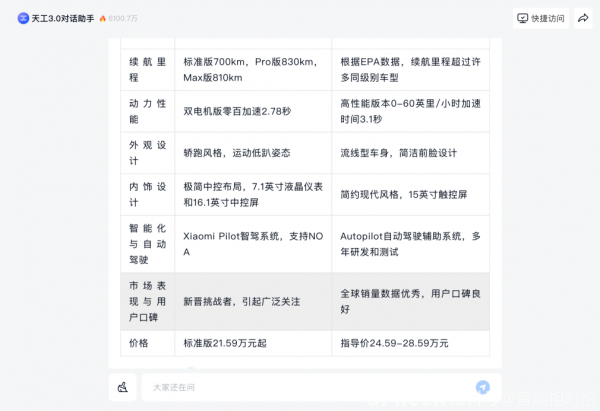
天工AI搜索提問“對比一下小米su7和特斯拉model3”所得出的結果
由此我們可以看到,AI在對比兩款車型的過程中,巧妙地將這一問題拆解成了續航裏程、動力性能、外觀設計、內飾設計、智能化與自動駕駛、市場表現與用戶口碑、價格等多個項目,分別處理得出較爲完整且專業的答案。
這便是“術業有專攻”的優勢——MoE模型之所以受到越來越多廠商的關注,首要的關鍵就在於其所帶來的全新解決問題的思路促使模型的性能得到了較爲顯著的提高。特別是伴隨着行業復雜問題的湧現,這一優勢將使得MoE模型得到更廣泛的應用。
各大廠商爭先开源MoE模型:解決AI算力荒的另一條路徑
开源的意義在於讓MoE模型更好的普及。那么,對於市場而言,爲什么要選擇MoE模型?
拋开性能來說,MoE模型更突出的一點優勢則在於算力效率的提升。
DeepSeek-MoE 16B在保持與7B參數規模模型相當的性能的同時,只需要大約40%的計算量。而37億參數的源2.0-M32在取得與700億參數LLaMA3相當性能水平的同時,所消耗的算力也僅爲LLaMA3的1/19。
也就意味着,同樣的智能水平,MoE模型可以用更少的計算量和內存需求來實現。這得益於MoE模型在應用中並非要完全激活所有專家網絡,而只需要激活部分專家網絡就可以解決相關問題,很好避免了過去“殺雞用牛刀”的尷尬局面。
舉個例子,盡管DeepSeek-MoE 16B的總參數量爲16.4B,但每次推理只激活約2.8B的參數。與此同時,它的部署成本較低,可以在單卡40G GPU上進行部署,這使得它在實際應用中更加輕量化、靈活且經濟。
在當前算力資源越來越緊張的“算力荒”局面下,MoE模型的出現和應用可以說爲行業提供了一個較爲現實且理想的解決方案。
更值得一提的是,MoE模型還可以輕松擴展到成百上千個專家,使得模型容量極大增加,同時也允許在大型分布式系統上進行並行計算。由於各個專家只負責一部分數據處理,因此在保持模型性能的同時,又能顯著降低了單個節點的內存和計算需求。
如此一來,AI能力的普惠便有了非常可行的路徑。這樣的特性再加上廠商开源,將促使更多中小企業不需要重復投入大模型研發以及花費過多算力資源的情況下便能接入AI大模型,獲取相關的AI能力,促進技術普及和行業創新。
當然,在這個過程中,MoE模型廠商們在爲市場提供开源技術的同時,也有機會吸引更多企業轉化成爲付費用戶,進而走通商業化路徑。畢竟,MoE模型的優勢擺在眼前,接下來或許將有更多的企業鬥都會嘗試新的架構來拓展AI能力,越早开源越能吸引更多市場主體接觸並參與其中。
但是,开源最關鍵的優勢還是在於MoE模型對當前算力問題的解決。或許,隨着MoE模型被越來越多的企業所接受並應用,行業在獲得相應AI能力的同時也不必困頓於算力資源緊張的問題了。
寫在最後
MoE大模型作爲當前人工智能領域的技術熱點,其獨特的架構和卓越的性能爲人工智能的發展帶來了新的機遇。不管是應用還是开源,隨着技術的不斷進步和應用場景的不斷拓展,MoE大模型有望在更多領域發揮巨大的潛力。
MoE模型的本質在於爲AI行業的發展提供了兩條思路,一是解決應用上的性能問題,讓AI有了更強大的解題思路。二是解決算力上的欠缺問題,讓AI有了更全面的發展空間。由此來看MoE模型能成爲行業各大廠商的寵兒,也是水到渠成的事情。
*本文圖片均來源於網絡
原文標題 : 晉升業內新寵兒,MoE模型給了AI行業兩條關鍵出路
標題:晉升業內新寵兒,MoE模型給了AI行業兩條關鍵出路
地址:https://www.utechfun.com/post/396059.html