作者:小巖
編輯:彩雲
4月19日,Facebook母公司Meta重磅推出了Llama3。
即便大家現在對於大廠和巨頭頻繁迭代AI模型的行爲已經見怪不怪,Meta的Llama3仍舊顯得與衆不同,因爲這是迄今最強大的开源AI模型。
Meta推出了重磅級產品Llama,顯然是劍有所指的,其中的寓意也很明顯,即是要在激烈的行業競爭中追趕領先者OpenAI。由此,我們也能看出Mata在AI領域的雄心壯志。

成爲最強开源模型,Llama3究竟是怎樣煉成的?
之所以說Llama3是“最強开源”,是因爲它在模型架構,預訓練數據,擴大預訓練規模以及指令微調方面都做出了重要的調教。
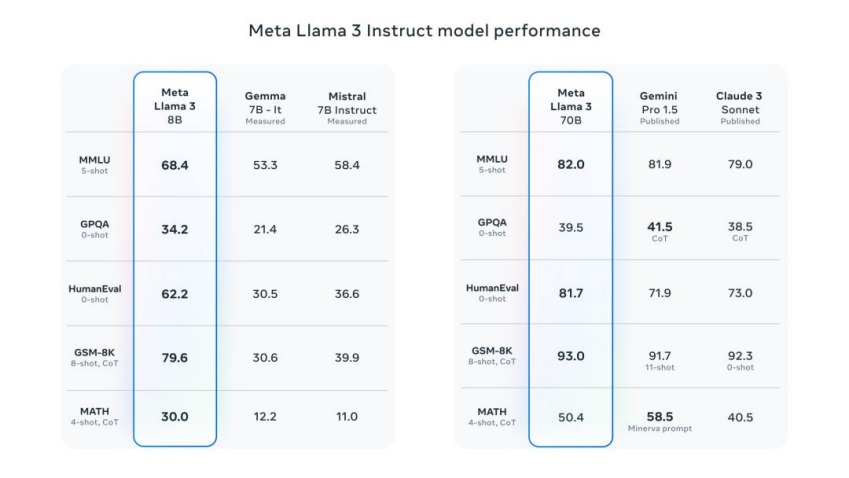
在模型架構方面,Llama 3 採用了相對標准的純解碼器 transformer 架構。與 Llama 2 相比,Llama 3更進行了幾項關鍵改進。Llama 3 使用了一個 128K token 的 tokenizer,它能更有效地編碼語言,從而大幅提高模型性能;Meta還在 8B 和 70B 大小的模型中都採用了分組查詢關注,以便提高Llama3的運行效率;此外,Meta還在8192 個 token 的序列上對模型進行了訓練,並使用掩碼來確保自注意力不會跨越文檔邊界。
訓練數據方面,Meta 表示,要訓練出最佳的語言模型,最重要的是策劃一個大型且高質量的訓練數據集。根據數據現實,Llama 3 在超過 15T 的 token 上進行了預訓練,訓練數據集是 Llama 2 的7倍,包含的代碼數量達到了Llama 2 的4倍。爲了應對多語言使用情況,Llama 3 的預訓練數據集中有超過5%的部分是高質量的非英語數據,涵蓋 30 多種語言。而爲了確保Llama 3始終在最高質量的數據上進行訓練,Meta還开發了一系列數據過濾管道,諸如啓發式過濾器,NSFW 過濾器,語義重復數據刪除方法,文本分類器等,以便更好的預測數據質量。與此同時,Meta還進行了大量實驗,確保 Llama 3 在各種使用情況下都能表現出色,包括瑣事問題,STEM,編碼,歷史知識等。
在擴大預訓練規模方面,爲了讓Llama 3 模型有效利用預訓練數據,Meta 爲下遊基准評估制定了一系列詳細的 scaling laws。這些 scaling laws 使他們能夠選擇最佳的數據組合,並就如何更好地使用訓練計算做出最佳決定。更重要的是,在實際訓練模型之前,scaling laws允許他們預測最大模型在關鍵任務上的性能,這有助於 Llama 3 在各種用例和功能中都能發揮強大的性能。
在指令微調方面,爲了在聊天用例中充分釋放預訓練模型的潛力,Meta 對指令微調方法進行了創新,在後期訓練方法中結合了監督微調(SFT),拒絕採樣,近似策略優化(PPO)以及直接策略優化(DPO)。
官方表示即將推出400B+版本...开源的400B+足夠令人期待。
此次Llama3的發布,還有一點惹人矚目,那就是Meta官方表示,即將在不久的未來推出400B+版本。
Meta 官方表示,Llama 3 8B 和 70B 模型只是 Llama 3 系列模型的一部分,他們後續還將推出更多版本,其中就包括模型參數超過 400B 的 Llama 3 版本,這一版本目前仍在訓練中。

在接下來的幾個月中,Meta會持續推出新功能:屆時會有更多的模態;更長的上下文窗口;更多不同大小版本的模型;更強的性能等。關於Llama 3研究論文也一應推出。
另外,Llama 3 模型將很快會在AWS,Databricks,Google Cloud,Hugging Face,Kaggle,IBM WatsonX,Microsoft Azure,NVIDIA NIM 以及Snowflake 上提供,並得到 AMD,AWS,Dell,Intel,NVIDIA 以及Qualcomm 硬件平台的支持。
當然,大家最期待的,還是即將推出的,參數超過400B+的版本。目前Llama3模型的最強參數是70B。這個數據已經十分優秀了,完全有能力和GPT-4-Turbo,Mistral-Large,Claude3-Opus相媲美。不過,相較於巨頭的最強模型,仍舊存在不小的差距。這也是大家如此期待400B+版本的重要原因。

400B+的版本仍在訓練中,單就目前釋放出的評測結果來看已經非常強了,堪稱Llama开源size中的“超大杯選手”。據悉,該模型的訓練成本會達到1億美元。 目前我們還不清楚Meta是否會开源“超大杯”。一旦开源,對於國內的大模型公司來說無疑是個重大利好。相信在此之後,也會有很多公司爭先跟上,推出後續的應用。但凡事都有兩面,對於OpenAI,Anthropic,Mistral,Google這些巨頭而言,這未必是個好消息。
“开源大模型”時代以來,AI會越來越失控嗎?
AI大模型如雨後春筍般不斷冒出,大家在見識到AI愈發強大,愈發智能的同時,也會感知到危機感。

AI是否會變得越來越失控?
對此,Meta CEO 馬可.扎克伯格也在最近接受的訪談中表達了自己的觀點。他認爲,AI的定位應該在於“一項非常基礎性的技術”。它的存在應該像計算機一樣,將催生一系列全新的應用。人們之所以會誕生AI會失控,很大程度上是因爲它發展的速度太快了,一時之間我們無法適應。
但在扎克伯格看來,這種情況不太可能發生,因爲這其中存在很多物理方面的限制。但有一點毋庸置疑:AI將真正改變我們的工作方式,爲人們提供創新的工具去做不同的事情。它將使人們能夠更自由地追求他們真正想做的事情。

事實上,我們無法預知AI未來的發展路徑究竟是怎樣的,是會真的造福人類,還是會給人類帶來災難。但有一點值得肯定:开源的AI系統確實有助於建立一個更公平,更平衡競技場。如果开源的機制可以運作成功,那應該會成爲大家所期待的未來。
原文標題 : 新火種AI|號稱“史上最強大开源模型”的Llama3,憑什么價值百億美金?
標題:號稱“史上最強大开源模型”的Llama3,憑什么價值百億美金?
地址:https://www.utechfun.com/post/361448.html