AI文生視頻這條賽道,將爲各行業帶來新的增量與繁榮。
在當下的AI賽道上,AI生文、生圖的應用,早已層出不窮,相關的技術,也在不斷日新月異。
而與之相比,AI文生視頻,卻是一個遲遲未被“攻下”的陣地。
抖動、閃現、時長太短,這一系列缺陷,讓AI生成的視頻只能停留在“圖一樂”的層面,很難拿來使用,更不要說提供商業上的賦能。
直到最近,某個爆火的應用,再次燃起了人們對這一賽道的關注。

關於這個叫做Pika的文生視頻AI,這些天想必大家已經了解了很多。
因此,這裏不再贅述Pika的各種功能、特點,而是單刀直入地探討一個問題,那就是:
Pika的出現,是否意味着AI文生視頻距離人們期望中的理想效果,還有多遠?
01 難題與瓶頸
實事求是地說,目前的AI文生視頻賽道,難度和價值都很大。
而其中最大的難點,莫過於讓畫面變得“抽風”的抖動問題。
關於這一點,任何使用過Gen-2 Runway 等文生視頻AI的人,都會深有體會。
抖動、閃現,以及不時出現的畫面突變,讓人們很難獲得一個穩定的生成效果。
而這種“鬼畜”現象的背後,其實是幀與幀之間聯系不緊密導致的。
具體來說,目前AI生成視頻技術,與早期的手繪動畫很相似,都是先繪制很多幀靜止的圖像,之後將這些圖像連接起來,並通過一幀幀圖像的漸變,實現畫面的運動。
但無論是手繪動畫還是AI生成的視頻,首先都需要確定關鍵幀。因爲關鍵幀定義了角色或物體在特定時刻的位置和狀態。
之後,爲了讓畫面看起來更流暢,人們需要在這些關鍵幀之間添加一些過渡畫面(也稱爲“過渡幀”或“內插幀”)。
可問題就在於,在生成這些“過渡幀”時,AI生成的幾十幀圖像,看起來雖然風格差不多,但連起來細節差異卻非常大,視頻也就容易出現閃爍現象。

這樣的缺陷,也成了AI生成視頻最大的瓶頸之一。
而背後的根本原因,仍舊是所謂的“泛化”問題導致的。
用大白話說,AI的對視頻的學習,依賴於大量的訓練數據。如果訓練數據中沒有涵蓋某種特定的過渡效果或動作,AI就很難學會如何在生成視頻時應用這些效果。
這種情況,在處理某些復雜場景和動作時,就顯得尤爲突出。
除了關鍵幀的問題外,AI生成視頻還面臨着諸多挑战,而這些挑战,與AI生圖這種靜態的任務相比,難度根本不在一個層面。
例如:
動作的連貫性:爲了讓視頻看起來自然,AI需要理解動作的內在規律,預測物體和角色在時間线上的運動軌跡。
長期依賴和短期依賴:在生成視頻時,一些變化可能在較長的時間範圍內發生(如角色的長期動作),而另一些變化可能在較短的時間範圍內發生(如物體的瞬時運動)。
爲了解決這些難點,研究人員採用了各種方法,如使用循環神經網絡(RNN)、長短時記憶網絡(LSTM)和門控循環單元(GRU)來捕捉時間上的依賴關系等等。
但關鍵在於,目前的AI文生視頻,並沒有形成像LLM那樣統一的,明確的技術範式,關於怎樣生成穩定的視頻,業界其實都還處於探索階段。
02 難而正確的事
AI文生視頻賽道,難度和價值都很大。
其價值,就在於其能真切地解決很多行業的痛點和需求,而不是像現在的很多“套殼”應用那樣,要么錦上添花,要么圈地自萌。
關於這點,可以從“時間”和“空間”兩個維度上,對AI文生視頻的將來的價值空間做一番審視。
從時間維度上來說,判斷一種技術是不是“假風口”、假繁榮,一個最重要的標准,就是看人們對這類技術的未來使用頻率。
根據月狐iAPP統計的數據,從2022年Q2到今年6月,在移動互聯網的所有類別的APP中,短視頻的使用時長佔比均高達30%以上,爲所有類別中最高。
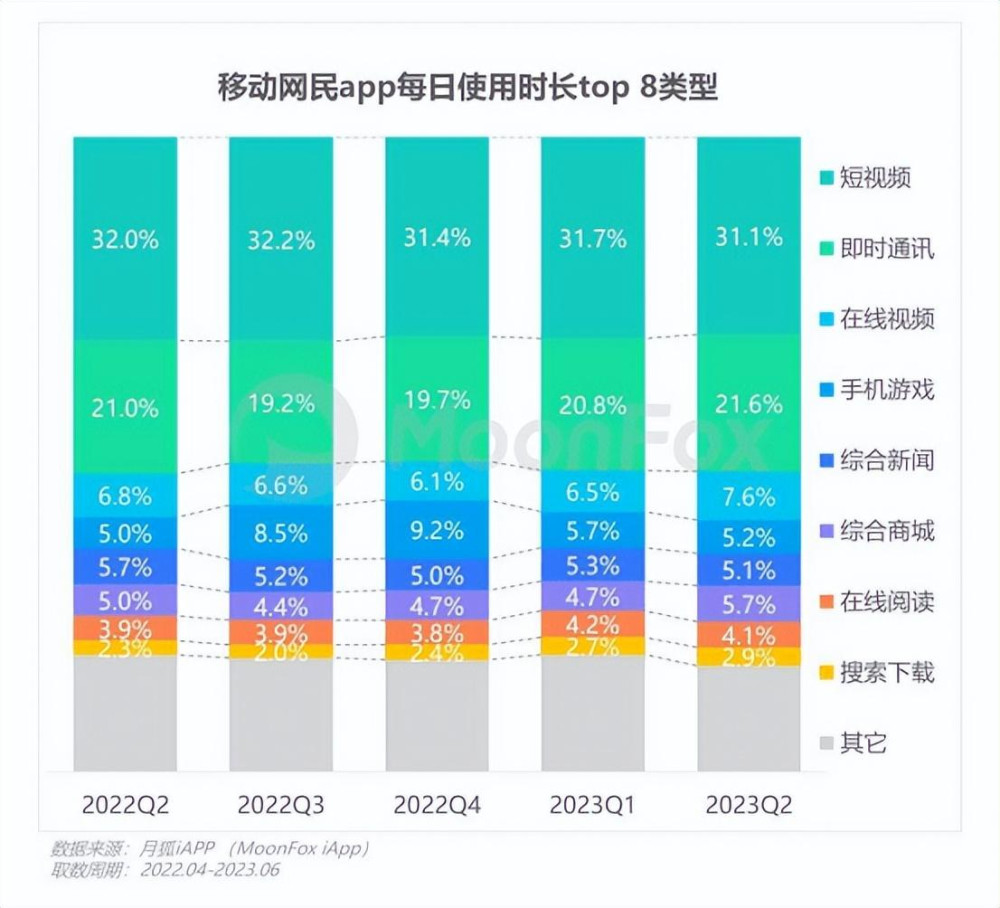
除了時間這一“縱向”維度外,倘若要在空間維度上,考量一種技術的生命力,最關鍵的指標,就是看其究竟能使多大範圍內的群體受益。
因爲任何技術想要“活”下來,就必須像生物體那樣,不斷地傳播、擴散自己,並在不同環境中自我調整,從而增加多樣性和穩定性。
例如在媒體領域,根據Tubular Labs的《2021年全球視頻指數報告》,新聞類別的視頻觀看量在2020年同比增長了40%。
同樣地,在電子商務方面,根據Adobe的一項調查,大約60%的消費者在購物時更愿意觀看產品視頻,而不是閱讀產品描述。
而在醫療領域,根據MarketsandMarkets的報告,全球醫學動畫市場預計從2020年到2025年將以12.5%的復合年增長率增長。
在金融行業中,HubSpot的一項研究表明,視頻內容在轉化率方面表現優異。視頻內容的轉化率比圖文內容高出4倍以上。

這樣的需求,表明了從時間、空間這兩個維度上來說,視頻制作領域,都是一個蕴含着巨大增量的“蓄水池”。
然而,要想將這個“蓄水池”的潛力完全釋放出來,卻並不是一件容易的事。
因爲在各個行業中,對於非專業人士來說,學習如何使用復雜的視頻制作工具(如Adobe Premiere Pro、Final Cut Pro或DaVinci Resolve)可能非常困難。
而對於專業人士來說,制作視頻還是個耗時的過程。他們得從故事板开始,規劃整個視頻的內容和結構,然後進行拍攝、剪輯、調色等等。
有時候,僅僅一分半的廣告視頻,就可能耗時一個月之久。

從這個角度來說,打开了AI文生視頻這條賽道,就相當於疏通了連接在這個蓄水池管道裏的“堵塞物”。
在這之後,暗藏的財富之泉,將噴湧而出,爲各個行業帶來新的增量與繁榮。
從這樣的角度來看,文生視頻這條賽道,即使再難,也是正確的,值得的。
03 行業引領者
賽道既已確定,接下來更重要的,就是判斷在這樣的賽道中,有哪些企業或團隊會脫穎而出,成爲行業的引領者。
目前,在AI文生視頻這條賽道上,除了之前提到的Pika,其他同類企業也動作頻繁。

科技巨頭Adobe Systems收購了Rephrase.ai,Meta推出了Emu Video,Stability AI發布了Stable Video Diffusion,Runway對RunwayML進行了更新。
而就在昨天,AI視頻新秀NeverEnds也推出了最新的2.0版本。
從目前來看,Pika、Emu Video、NeverEnds等應用,已經顯示出了不俗的實力,其生成的視頻,已大體上能保持穩定,並減少了抖動。
但從長遠來看,要想在AI文生視頻領域持續保持領先,至少需要具備三個方面的條件:
1、強大的算力
在視頻領域,AI對算力的要求,比以往的LLM更甚。
這是因爲,視頻數據包含的時間維度和空間維度,都要比圖片和文字數據更高。同時爲了捕捉視頻中的時間動態信息,視頻模型通常需要具有更復雜的結構。
更復雜的結構,就意味着更多的參數,而更多的參數,則意味着所需的算力倍增。
因此,在將來的AI視頻賽道上,算力資源仍舊是一個必須跨過的“硬門檻”。
2、跨領域合作
與圖片或文字大模型相比,視頻大模型通常涉及更多的領域,綜合性更強。
其需要整合多種技術,例如來實現高效的視頻分析、生成和處理。包括但不限於:圖像識別、目標檢測、圖像分割、語義理解等。

如果將當前的生成式AI比作一棵樹,那么LLM就是樹的主幹,文生圖模型則是主幹延伸出的枝葉和花朵,而視頻大模型,則是汲取了各個部位(不同類型數據)的養分後,結出的最復雜的果實。
因此,如何通過較強的資源整合能力,進行跨領域的交流、合作,就成了決定團隊創新力的關鍵。
3、技術自主性
誠如之前所說,在目前的文生視頻領域,業界並沒有形成像LLM那樣明確的、統一的技術路线。業界都在往各種方向嘗試。
而在一個未確定的技術方向上,如何給予一线的技術人員較大的包容度,讓其不斷試錯,探索,就成了打造團隊創新機制的關鍵。
對於這個問題,最好解決辦法,就是讓技術人員親自掛帥,使其具有最大的“技術自主性”。
誠如Pika Labs的創始人Chenlin所說:“如果訓練數據集不夠好看,模型學到的人物也不會好看,因此最終你需要一個具有藝術審美修養的人,來選擇數據集,把控標注的質量。”

Pika Labs創始人Demi Guo 和 Chenlin Meng
在各企業、團隊不斷競爭,行業新品不斷湧現的情況下,文生視頻AI的爆發期,就成了一件十分具體的,可以預期的態勢。
按照Pika Labs創始人Demi的判斷,行業也許會在明年迎來AI視頻的“GPT時刻”。
盡管技術的發展,有時並不會以人的意志爲轉移,但當對一種技術的渴望,成爲業界的共識,並使越來越多的資源向其傾斜時,變革的風暴,就終將會到來。
原文標題 : AI文生視頻,會在明年迎來“GPT時刻”
標題:AI文生視頻,會在明年迎來“GPT時刻”
地址:https://www.utechfun.com/post/300436.html