
「證據」終於來了。7 月 OpenAI 和 Meta 被美國作家 Sarah Silverman、Christopher Golden 和 Richard Kadrey 控告,指兩家公司未經作者同意,就把他們的書拿來當材料訓練大模型。

▲ 演員、作者Sarah Silverman和自傳。(Source:Michael Kovac / FilmMagic)
證據在哪?
OpenAI案件,原告輸入提示詞後,ChatGPT能摘要整本書。Meta案件,Meta大模型LLaMA論文就寫著,訓練資料包括EleutherAI整理的「The Pile」素材,The Pile又含「Books3」資料庫,內容正是網路盜版圖書庫Bibliotik數據。由此可見,當時原告的證據還相對間接。
直到現在,作家和工程師Alex Reisner,Meta大模型背後到底都盜用了哪些作家的書。意外的是,這些「證據」一直都在我們眼前,卻一直沒人看到,這是為什麼?甚至侵權素材的製造者,還一直堅持說這是「正義」之舉。
17萬本盜版書
Alex Reisner的「大專案」起於好奇心:
身為作家和電腦工程師,我一直很好奇生成式AI是用什麼書訓練模型。
今年夏天,Reisner開始在GitHub和Hugging Face等社群找答案,最終找到了The Pile。然而下載The Pile也不代表可以知道Books3有什麼書。因The Pile有800G,大到一般文字編輯器根本沒法看。Reisner寫了一系列程式才能抓取Books3的資料。
沒想到找到的資料沒有任何有書名、作者名等標籤資料,一切都只是「文本」。於是Reisner又另外寫了一個程式抓取ISBN編號(國際標準書號),並將這些數據和其他網路書庫比對,以辨別Books3收錄的書籍。
最後他找到19萬個ISBN,辨識出17萬個書名(實際數量可能略少這數字,因是同一本書不同版),另外2萬個編碼無法找到書名。這些書約三分之一是虛構作品,三分之二非虛構作品,來自大大小小出版社出版品。
能找到的書包括開頭提告OpenAI和Meta的三位作家,可說是Meta LLaMA以盜版書當作訓練材料的直接證據了。其他還有《我的天才女友》作者埃琳娜·費蘭特、《女僕的故事》作者、史蒂芬‧金、村上春樹、知名美食作家麥可·波倫、驚悚小說家詹姆斯·布蘭登·派特森等許多作品。
除了名作家作品,Reisner還在Books3找到「山達基教」創辦人拉法葉·羅納德·賀伯特102本低俗小說、90本信奉「年輕地球創造論」的牧師約翰·F·麥克阿瑟的書,以及「外星人創造論」支持者艾利希·馮·丹尼肯多部作品。
Reisner指出,雖然Books3資料庫在AI社群以外認知度不高,但在圈內頗受歡迎,因「可以下載,但要找到來源有難度,想瀏覽和分析也同樣很有挑戰性」。像Reisner大費周章寫程式分析比對,還撰文投書媒體更是首次。同時AI圈對Books3也是心照不宣維護,因以Books3創造者的話說,這是確保生成式AI發展不會被大公司壟斷的重要資源。
「盜火者」還是「竊賊」?
如果我們不需要Books3這類東西的確最好,但情況是如果沒有Books3,只有OpenAI可做到正在做的事。
Books3創造者、獨立開發者Shawn Presser對Reisner說。
Presser一開始做Books3,就是為了提供所有開發者「OpenAI等級訓練資料」。2020年Presser下載Bibliotik副本,再改寫駭客Aaron Swartz十多年前的程式,將所有ePub格式圖書轉成純文字──更適合大模型的格式。資料庫部分書籍版權資料遺失,Presser稱是轉換造成的意外,並非刻意為之。
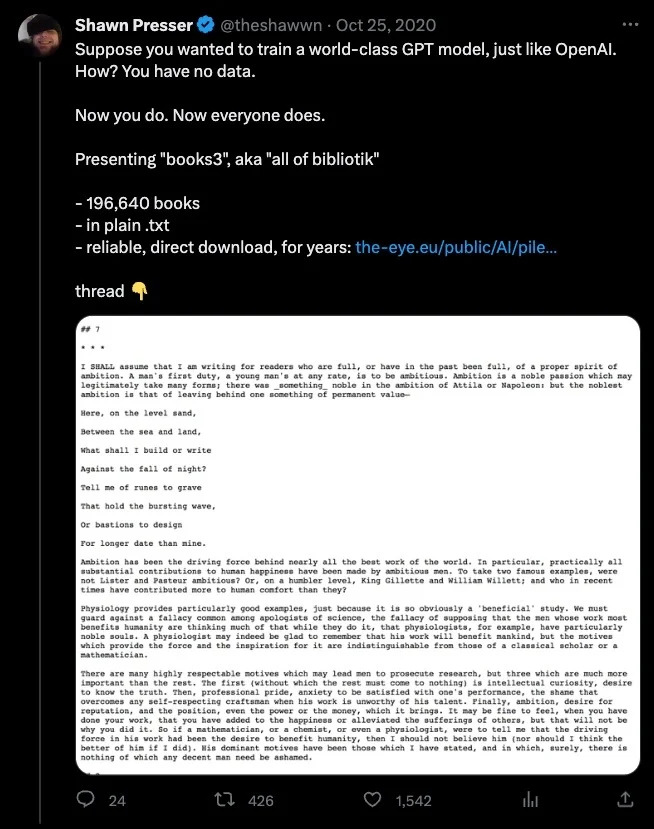
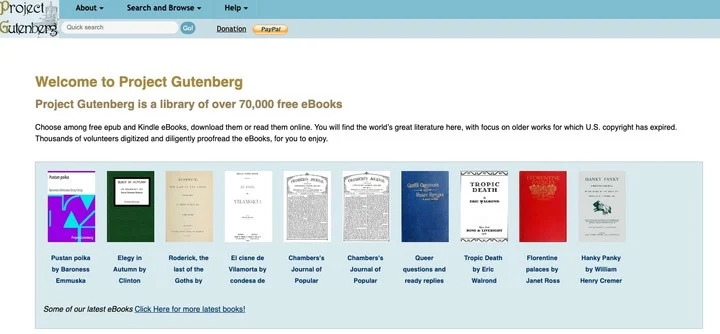
Books3之名也呼應OpenAI提過的「Books1」和「Books2」。2020年時OpenAI論文指出,GPT-3的訓練資料庫包括兩個基於網路書籍合集,人們推測OpenAI的Books1來自「古騰堡計畫」(Project Gutenberg)──專門收集版權過期的圖書。Books2內容是什麼一直無人知曉,有人從資料量猜是類似Bibliotik或Libgen的網路盜版圖書。
除了書籍,GPT-3還用了其他數據,如維基百科和其他網路文字,這也是為什麼EleutherAI整合的The Pile也同樣含大量資料,如維基百科、YouTube影片字幕、歐洲議會檔案和速記等。即便如此,書籍高品質文本仍很重要。
Meta曾,一開始LlaMA-65B大模型表現沒有很好,因「書籍及學術論文量有限」。MIT和康乃爾大學合作論文也,書籍在大模型訓練資料庫「對下遊表現有最強正面效果」,所以會在Meta後來推出的LlaMA 2資料庫看到The Pile和Books3。
這也是為什麼Books3最近因後,Presser卻憤慨不平。他覺得所有牟利大公司私下都用侵權內容訓練大模型,但他們不公開訓練資料來源,所以沒人能告他們,Books3被下架,但他是希望讓大模型更開放和有更高透明度而主動公開資料來源。
Presser說不能讓財大氣粗的大公司壟斷這種重塑文化的重要技術,而是要讓所有人都有資源:
我的目標是讓所有人都能(建造大模型)。
除非作者有方法把ChatGPT拉下來,或告到AI公司關門,否則你我都能建造自己的ChatGPT非常重要。
正如1990年代,確保任何人都能自己架設網站那樣重要。
至於把ChatGPT告到下架,也不是完全不可能。
人人都在告AI巨頭
知名作家官司也許能引起更多關注,但擁有把ChatGPT告到「重建」潛力的,卻是傳統新聞媒體。上週NPR知情人士消息,《紐約時報》也考慮提告OpenAI。前幾週《紐約時報》一直和OpenAI就授權內容談判,但進展不太順利,故《紐約時報》開始考慮提告OpenAI侵權。
美國聯邦版權法規定,每項「蓄意」侵權行為最高可罰15萬美元,以《紐約時報》的海量文章計算,最終罰金會高到「對任何公司都很致命」。除此以外,如果法官判定OpenAI的確非法以《紐約時報》文章訓練大模型,法院可以命令OpenAI銷毀ChatGPT資料庫,強制僅能用已獲授權內容訓練ChatGPT。
無論原告是《紐約時報》還是各創作者,官司(或潛在官司)能否勝訴,關鍵都在AI巨頭是否能把無告知使用說成「合理使用」──即特定情況,允許不經許可使用特定作品,如教學、評論、研究和報導等。支持「合理使用」的人有兩個論點:
- 生成式AI並不會重現書籍本身,而是創造新內容。
- 新內容不會損害原本作品的市場。
紐約大學科技法律與政策診所負責人Jason Schultz稱,圖書盜用方面,這論點頗有力,但《紐約時報》律師堅持,OpenAI報章新聞使用並不符合「合理使用」。假如使用者能用AI聊天機器人取得片段資訊,就不會去找原始新聞閱讀,有可能成為新聞的替代品,影響原有市場。
中國網紅樊百樂,智慧財產權法並非一成不變,但核心卻很堅定:繁榮創作市場,如果連估值數百億美元的AI公司都能不付一毛錢版權費,免費把作家耗費數年心血創作的作品拿去牟利,甚至盜用訓練出能取代作家的工具,對創作者無疑是致命打擊。Presser談到的「資訊不公平」問題,也不應是侵犯創作者權利的藉口。
版權問題終究是決定AI能走多遠的關鍵因素。範德堡大學知識產權計畫聯席主任Daniel Gervais:
版權法是懸在AI公司頭上的大刀,除非他們想出方法解決,否則這把刀幾年內都會掛在那裡。
這只是下階段的開始。最後整理部分進行中AI公司侵權官司,供讀者參考。


(本文由 授權轉載;首圖來源:)
延伸閱讀:

標題:17 萬本盜版書是「ChatGPT 們」變聰明的祕密
地址:https://www.utechfun.com/post/254175.html