

手機上跑大模型,有必要嗎?
作者|武靜靜
編輯|慄子
小米的大模型在雷軍2023年年度演講中首次公开亮相。
雷軍提到,和很多互聯網平台的思路不同,小米大模型的重點突破方向是輕量化和本地部署,能在手機端側跑通。
他稱,目前,13億參數規模的MiLM1.3B模型已經在手機上跑通,且效果可以媲美60億參數的大模型在雲端運算的結果。在他曬出的成績單中,小米端側大模型在CMMLU中文評估的各項主題中都比智譜AI的ChatGLM2-6B模型表現好,和百川智能的Baichuan-13B大模型的得分差距約在5分左右。
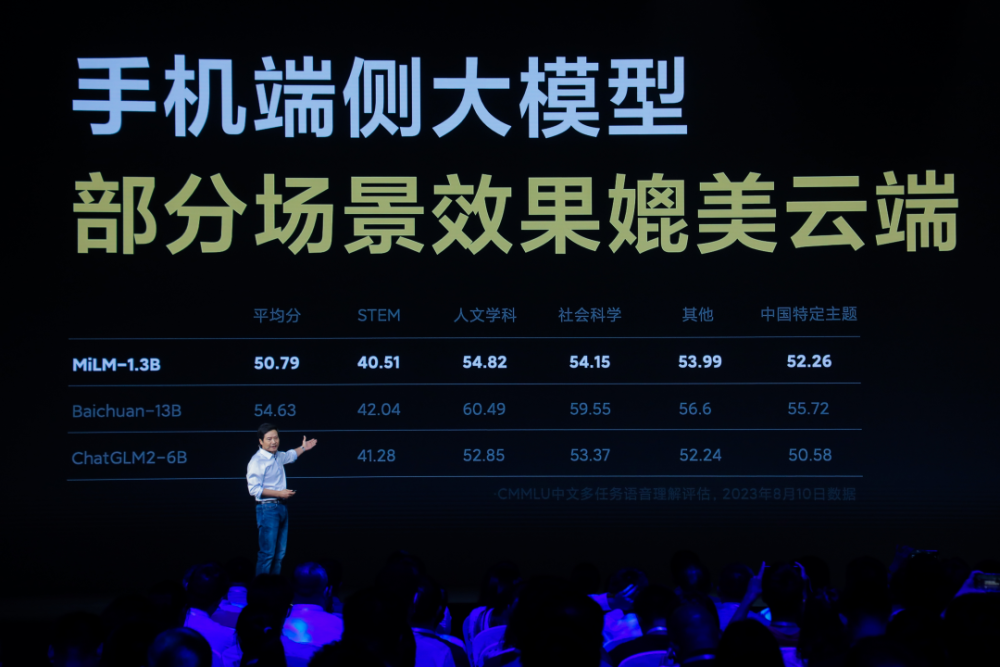
此前,小米开發的大規模預訓練語言模型MiLM-6B/1.3B已經登陸代碼托管平台GitHub,並在C-Eval總榜單排名第十、同參數量級排名第一,在中文大模型基准“CMMLU”上,“MiLM-6B”排名第一。
當然,由於這些測試榜單的維度都是公开的,根據測試任務進行刷榜刷分對於很多大模型公司並非難事,所以這些測評結果只能作爲參考,並不意味着效果上的絕對優秀。
同時,雷軍也宣布小愛同學作爲小米大模型第一個應用的業務,已經進行了全新的升級,並正式开啓邀測。
這是從今年4月宣布新設立大模型團隊以來,小米在4個月時間中做出的階段性大模型成果。
小米的實踐給大模型落地帶來什么新思考?對於借助新技術迭代的手機廠商而言,又意味着什么?
1.小米不做通用大模型,核心團隊約30人

小米在大模型路线上屬於理性派——不追求參數規模,不做通用大模型。
此前在財報電話會上,小米集團總裁盧偉冰就對外稱,小米會積極擁抱大模型,方向是與產品和業務深度結合,不會像OpenAI一樣去做通用大模型。
根據深燃此前的報道,小米集團AI實驗室主任王斌博士曾說,小米不會單獨發布一款類ChatGPT產品,自研大模型最終會由產品帶出來,相關投入約幾千萬人民幣級別。
他說:“對於大模型,我們屬於理智派。小米有應用場景優勢,我們看到的是大模型跟場景結合的巨大機會。”
他透露,在ChatGPT誕生之前,小米內部做過大模型相關的研發和應用,當時是通過預訓練+下遊任務監督微調的方式來做人機對話,參數規模在28億到30億。這主要是在預訓練基座模型的基礎上,通過對話數據的微調實現的,並非現在所說的通用大模型。
根據公开資料,目前小米大模型團隊負責人爲AI語音方向專家欒劍,向技術委員會副主席、AI實驗室主任王斌匯報。整個大模型團隊有30人左右。
欒劍曾是智能語音機器人“微軟小冰”首席語音科學家及語音團隊負責人,曾任東芝(中國)研究院研究員、微軟(中國)工程院高級語音科學家。加入小米後,欒劍曾先後負責語音生成、NLP等團隊,以及相關技術在小愛同學等產品中落地。王斌2018年加入小米,2019年起負責AI實驗室,加入小米前曾是中國科學院信息工程研究所研究員、博導,在信息檢索與自然語言處理領域有近30年研究經驗。
做大模型也依托於小米背後的AI團隊,雷軍稱,小米的AI團隊經過7年時間,6次擴展,已經超過3000人,覆蓋了CV、NLP、AI影像、自動駕駛、機器人等多個領域。
 (圖源:小米)
(圖源:小米)
2.谷歌、高通、華爲紛紛入局
小米之外,讓大模型跑在手機上是很多科技公司當前的重點目標。
科技公司正在想象大模型帶來這樣一種可能性:不管你打开的是WPS、石墨文檔還是郵件,只要輸入寫作等指令,手機就可以調用本地能力生成完整的一篇文章或者一封郵件。手機端,所有的App都可以隨時調用本地的大模型來幫忙處理工作和解決生活問題,人和手機上各種App的交互也不再是頻繁的點擊,而是通過語音就能進行智能召喚。
很多公司正在想方設法地壓縮模型體積,讓大模型在手機上的本地運行變得更實用且經濟。在今年5月的Google I/O大會上,谷歌發布PaLM2時,按照規模大小分爲四種規格,從小到大依次爲Gecko、Otter、Bison和Unicorn,其中體積最小的Gecko可以在手機上運行,並且速度很快,每秒可處理20個標記,大約相當於16或17個單詞,也可支持手機離线狀態運行。但當時谷歌沒說這款模型會具體用在哪一款手機上。
目前已經拿出具體成績的是高通。在今年3月的2023MWC上,高通在搭載第二代驍龍8的智能手機上,運行了超過10億參數的文生圖模型Stable Diffusion。演示中,工作人員在一部沒有聯網的安卓手機上用Stable Diffusion生成了圖像,整個過程用了15秒。
6月的計算機視覺學術頂會CVPR上,高通又展示了在安卓手機上運行15億參數規模的ControlNet模型,出圖時間僅用了11.26 秒。高通產品管理高級副總裁兼AI負責人Ziad Asghar稱:從技術上,把這些超10億參數大模型搬進手機,只需要不到一個月的時間。
最新的動作是高通宣布和Meta合作,探索基於高通驍龍芯片,在不聯網的情況下,在智能手機、PC、AR / VR頭顯設備、汽車等設備上,運行基於Llama 2模型的應用和服務。高通稱,和基於雲端的LLM相比,在設備本地運行Llama 2 等大型語言模型,不僅成本更低,性能更好,且不需要連接到在线服務,服務也更個性化、更安全和更私密。
尚未官宣任何大模型動作的蘋果也正在探索大模型在設備端側的落地。據《金融時報》報道,蘋果正在全面招聘工程師和研究人員來壓縮大語言模型,以便它們能夠在iPhone和iPad上高效運行,主要負責的團隊是機器智能和神經設計 (MIND) 團隊。
目前,在Github上,一個熱門的开源模型MLC LLM項目就可以支持本地部署,它通過仔細規劃分配和積極壓縮模型參數來解決內存限制,可以在iPhone等各類硬件設備上運行AI模型。該項目是由CMU助理教授,OctoML CTO陳天奇等多位研究者共同开發的,團隊以機器學習編譯(MLC)技術爲基礎來高效部署AI模型。MLC-LLM上线不到兩天,GitHub的Star量已經接近一千。有人已經測試了在iPhone的飛行模式下本地跑大語言模型。
和國外谷歌、高通強調大模型在端側本地部署,可以離线運行不同,目前國內手機廠商優先考慮的是將大模型落地在手機語音助手或者現有的圖片搜索功能上,這種升級本質還是調用更多雲端能力來使用大模型。
此次,小米就是將大模型用在了語音助手小愛同學上。但由於目前小米端側大模型相關信息尚未披露,無法准確判斷之後小米大模型的發展路徑。從雷軍強調的本地部署和輕量化的方向來看,未來小米可能會嘗試大模型在手機端離线運行。
華爲也在嘗試大模型在手機端的落地,不過重點瞄准的依舊是手機語音助手和搜圖場景。此前4月,華爲新發布的手機P60上,智慧搜圖新功能背後就是多模態大模型技術,過程中在手機端側對模型進行小型化處理。近期,華爲新升級的終端智能助手小藝也基於大模型進行體驗優化,可以根據語音提示推薦餐廳、進行摘要總結等新功能。
OPPO、vivo也在這個方向發力,8月13日,OPPO宣布,基於AndesGPT打造的全新小布助手即將开啓體驗,從資料中可以看到,小布助手集合大模型能力之後,在對話、文案撰寫等方面的能力會有所加強。AndesGPT是OPPO 安第斯智能雲團隊打造的基於混合雲架構的生成式大語言模型。
對於手機廠商而言,不管是本地部署,還是調用雲端能力,大模型之於手機,都是一個不可錯失的新機會。
3.大模型跑在手機上,關鍵難題在哪兒?
讓大模型跑在手機上不是一件容易的事。
算力是首要問題。在手機端使用大模型,不僅需要調用雲端算力還需要調用終端設備的算力,由於大模型的大資源消耗,每一次的調用都意味着很高的成本。Alphabet董事長John Hennessy曾提到,用大語言模型的搜索成本比此前的關鍵詞搜索成本高出10倍。去年,谷歌有3.3萬億次搜索查詢,成本約爲每次五分之一美分。華爾街分析師預測,如果谷歌用大語言模型來處理一半的搜索問題,每次提供的答案爲50個單詞左右,到2024年,谷歌可能面臨60億美元的支出增長。
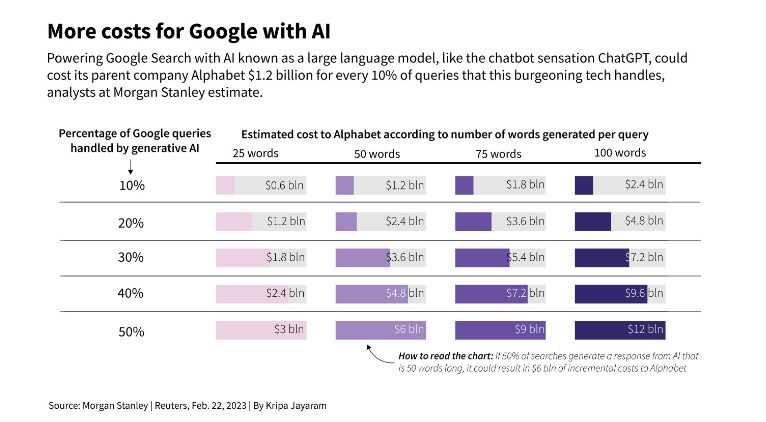
(圖源:路透社)
手機端運行大模型面對類似的成本難題,在高通發布的《混合AI是AI的未來》報告中提到,就像傳統計算從大型主機和客戶端,演變爲當前雲端和邊緣終端相結合的模式一樣,端側運行大模型也需要混合AI架構,讓雲端和邊緣終端之間分配並協調AI工作負載,從而能讓手機廠商利用邊緣終端的計算能力降低成本。讓大模型實現本地部署就是出於這一成本問題的考量。
此外,手機作爲每個人的私人物品,是數據產生的地方,本地也存放着大量的私人數據,如果能夠實現進行本地部署,在安全性、隱私等方面爲個人提供了保障。
這就帶來了第二個難題,如果想更多地調用端側能力來運行大模型,如何讓手機的能耗很低,同時還能讓模型的效果很強?
高通曾對外稱,之所以能將大模型部署到手機等本地設備上,關鍵能力在於高通軟硬件全棧式的AI優化,其中包括高通AI模型增效工具包(AIMET)、高通AI引擎和高通AI軟件棧等相關技術,可以壓縮模型體積,加速了推理,並降低運行時延和功耗。高通全球副總裁兼高通AI研究負責人侯紀磊曾提到,高通在高效能AI研發中,一個重要的部分是整體模型效率研究,目的是在多個方向縮減AI模型,使其在硬件上高效運行。
單模型壓縮就是一個不小的難點。有的模型壓縮會對大模型的性能造成損失,有一些技術方式可以做到無損壓縮,這些都需要借助各種工具進行不同方向的工程化嘗試。
這些關鍵的軟硬件能力對於手機廠商而言都是很大挑战。如今,很多手機廠商都邁出了在手機上跑大模型的第一步。接下來,如何讓更好的大模型,更經濟、更高效地落在每一部手機中反而是更難、更關鍵的一步。
冒險才剛剛开始。
(封面圖來源:小米)

本文作者可以追加內容哦 !
標題:卷入大模型,手機廠商的新敘事|甲子光年
地址:https://www.utechfun.com/post/249746.html