來源:半導體產業縱橫

同實驗室博士用GPU得靠搶。

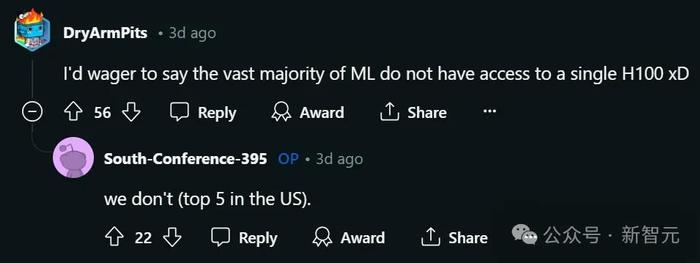
全美TOP 5高校的機器學習博士,實驗室卻連一塊H100都沒有?
最近,這位網友在reddit上發的這個帖子,立刻引發了社區大討論。

大家發現,普林斯頓、哈佛這樣的“GPU豪門”,手上的H100至少以三四百塊打底,然而絕大多數ML博士,卻連一塊H100都用不上。
不同學校、機構之間的GPU“貧富差距”,竟然已經到了如此懸殊的地步?

大部分實驗室,比斯坦福還差多了
兩個月前,AI教母李飛飛曾在採訪中表示,斯坦福的自然語言處理(NLP)小組只有64塊A100 GPU。
面對學術界如此匱乏的AI資源,李飛飛可謂是痛心疾首。

而這位發帖的網友也表示,自己在攻讀博士學位期間(全美排名前五的學校),計算資源是一個主要的瓶頸。
如果能有更多高性能的GPU,計算時間會顯著縮短,研究進度也會快很多。

所以,他的實驗室裏到底有多少H100呢?答案是0。
他向網友們發出提問:你們實驗室裏都有多少GPU?能從亞馬遜、英偉達那裏拿到額外的算力贊助嗎?
年輕的研究者們紛紛自曝自己所在學校或公司的GPU情況,暴露出的事實,讓所有人大爲驚訝。
1張2080Ti+1張3090,已是全部
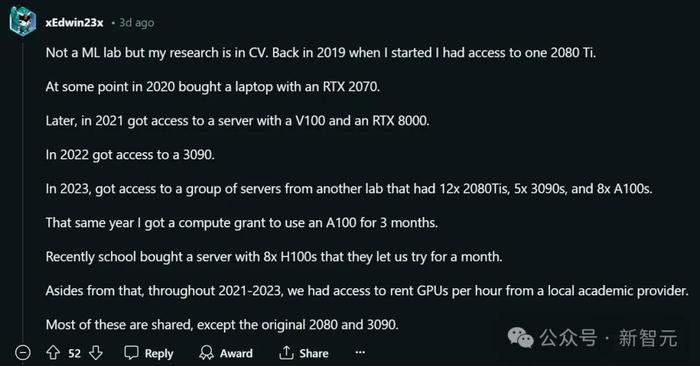
一位似乎是亞洲的網友表示,雖然自己的研究方向是計算機視覺(CV)並不是機器學習,但在2019年剛开始時,只能夠使用一塊2080 Ti顯卡。
2021年,有機會使用一台配備V100和RTX 8000顯卡的服務器。
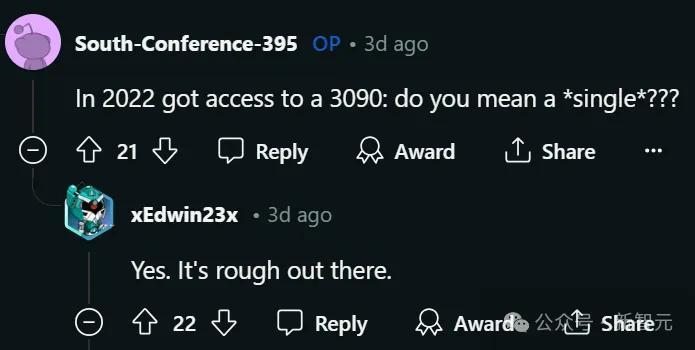
2022年,獲得了使用一塊3090顯卡的權限。
2023年,能夠使用另一個實驗室的一組服務器,這些服務器包括12塊2080 Ti、5塊3090和8塊A100顯卡。同年,還獲得了一項計算資助,可以使用A100顯卡三個月。
2024年,學校購买了一台配有8塊H100顯卡的服務器,並允許試用一個月。
此外,在2021年到2023年期間,也可以從一個本地學術提供商那裏按小時租用GPU。
除了2080 Ti和3090這兩張顯卡外,大多數這些資源都是共享的。
題主問:這裏的“a”就是字面意義上的“一個”么?
網友表示,是的,就是這么艱苦……
有人現身表示,自己可太慘了:沒有顯卡,沒有credits。因爲所在大學無法提供幫助,只能讓實習公司幫自己獲得一些。

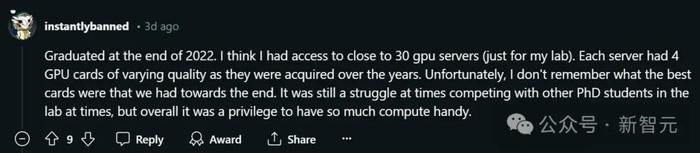
一位2022年底畢業的博士也自曝稱,實驗室專用的服務器共搭載了差不多30塊GPU,其中每台服務器配有4張顯卡。(由於購买時間不同,性能也參差不齊)
不過,同一實驗室裏搶GPU的事情還是時有發生。
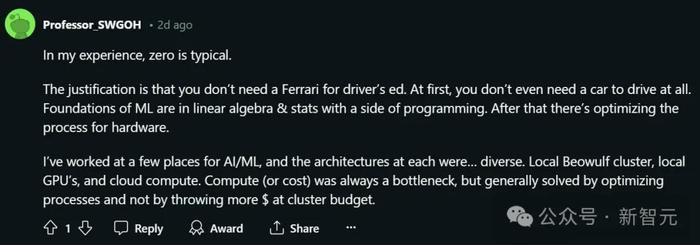
對此,有網友總結道,0 GPU很常見。
理由也非常簡單:我們並不需要开着法拉利來學車。而且在开始,機器學習的基礎是线代、統計和編程,之後才是硬件流程的優化。
而GPU嚴重匱乏的問題,在我國高校的實驗室內也很普遍。
甚至,有博主發帖稱,某大學的課程竟要求學生自備算力設備。
五人一組的學生,至少擁有2塊3090/4090,或者是1塊40G A100,才能完成課程要求的LLM訓練任務。
那么問題來了,爲何高校自己不能多採購一些GPU呢?

知友“網癮大爺”表示,高校直接購买GPU非常不劃算。LLM訓練參數規模增大,需要的是多機多卡,以及讓卡之間串聯的網絡。
不僅有學習成本、還有維護成本,這對於高校來說投入之大。所以比較常見的方式是,去租用服務器。

清華計算機系在讀博士孫恆提出了同樣的問題,卡可以买,但問題是,放在哪?


當然,有人在負重前行,自然也有人歲月靜好。
比如下面這些學校,相比起來就要“富裕”得多了。
H100,我們也就幾百塊吧
有網友透露,普林斯頓語言與智能研究所(PLI)和哈佛Kempner研究所擁有最大的計算集群,分別配備了300塊和400塊H100 GPU。

而這個信息,也得到了一位普林斯頓研究者的佐證——
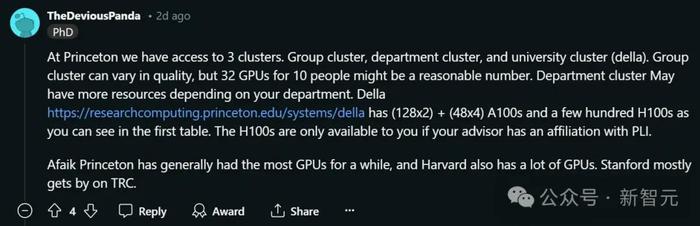
在普林斯頓,可以使用的集群有三種。
- 小組集群有所不同,但對於10個人來說,32塊GPU的分配很合理
- 部門集群的資源更多,不過也需要看具體的部門
- 大學集群Della則擁有(128x2)+(48x4)個A100和(96x8)個H100
總之,普林斯頓和哈佛都可以說是顯卡大戶。
此外,也有網友爆料說,UT Austin擁有600塊H100。
蒙特利爾大學的博士生表示,自己的實驗室大約有500塊GPU,主要是A100 40GB和80GB。

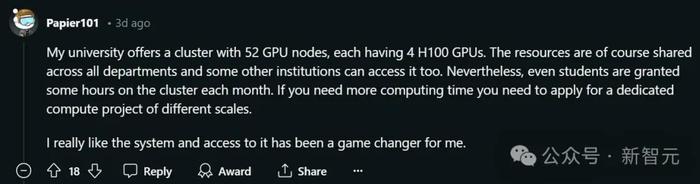
德國亞琛工業大學的網友表示,學提供了一個包含52塊GPU節點的計算集群,每個節點配備4塊H100 GPU。
這些資源當然是所有院系共享的,其他一些機構也能使用。
不過,即使是學生,每個月也會分配到一定的集群使用時間。如果你需要更多的計算時間,可以申請不同規模的專用計算項目。
“我非常喜歡這個系統,能夠使用它,對我來說是一次改變研究進程的機會。”
對如此充沛的算力,題主表示非常羨慕。
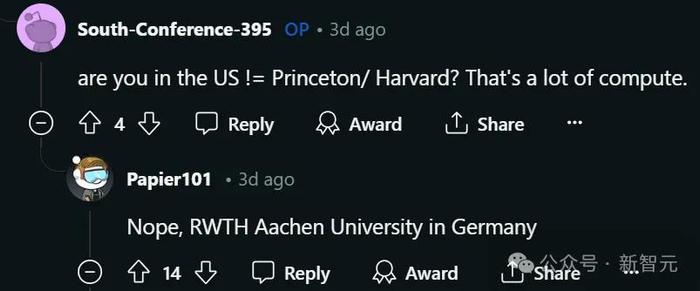
另一位歐洲的網友也表示,自己的實驗室有大約16塊實驗室專用的A100 GPU,並且還能通過幾個不同的額外集群訪問更多的GPU。
由於這些集群有很多用戶,所以具體規模很難估計,但每個集群大約每年提供12萬GPU小時的計算時間。
不過,超過80GB的GPU內存需求是一個瓶頸。目前來說,總共能用的約爲5塊H100。
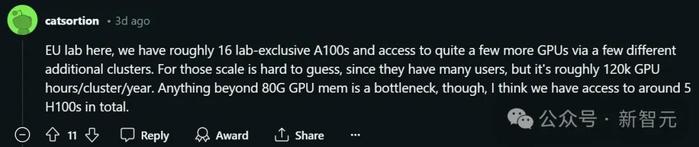
類似的,這位網友所在的實驗室,也相當富裕:
“我們實驗室有8塊H100和8塊L40S,專供5名博士生和3名博士後免費使用。”
最後,截取一些“凡爾賽”網友的發言。
比如,這位在雲計算供應商工作的網友就表示,這個帖子很有趣,因爲自己竟不知道H100是這么稀有。
或者,從單位分不到顯卡,那就幹脆自己买一塊。
緊俏的H100,爲何如此重要
這背後最耀眼的明星,莫過於它的H100 GPU了。

跟普通芯片不同的是,H100內的800億個晶體管排列在內核中,這些內核被調整爲高速處理數據,而非生成圖形。
成立於1993年的英偉達,押注並行工作的能力有一天將使自己的芯片在遊戲之外發揮價值,他們賭對了。
在訓練LLM時,H100比前代A100快四倍,在回復用戶提示時快30倍。對於急於訓練LLM執行新任務的公司來說,性能優勢至關重要。
也正是因此,全世界生成式AI的浪潮,正在轉化爲英偉達的實際收入。而H100的需求如此之大,以至於許多客戶不得不等待六個月才能收貨。
Nebius AI的IaaS技術產品經理Igor,探討了H100、L4、L40、A100、V100這些最流行的芯片之間的差異,並確定了每種GPU模型表現最佳的工作負載。
談到芯片之間的差異之前,重要的是強調Transformer神經網絡和數值精度的一些相關屬性。
數值精度的作用
如果沒有對FP8精度的硬件支持,英偉達的H100、L4和L40不可能取得巨大的成功,這對於Transformer模型尤其重要。
但是,是什么讓對FP8的支持如此重要呢?讓我們深入了解一下。
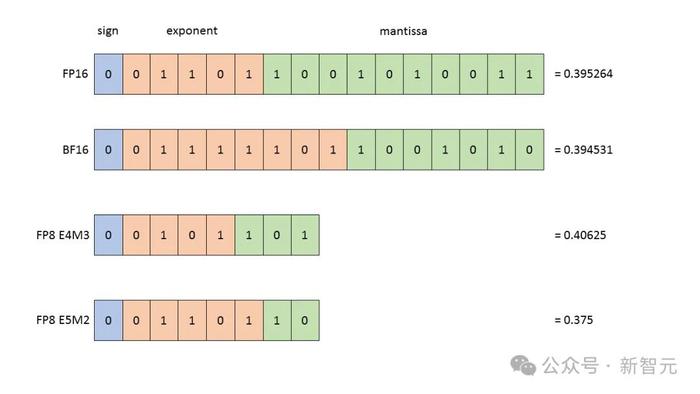
FP是「浮點」的縮寫,它是關於模型存儲在RAM中,並在其操作中使用的數字的精度。
最重要的是,這些數字決定了模型輸出的質量。

以下是一些關鍵的數字格式:
FP64,即雙精度浮點格式,是一種每個數字佔用64位內存的格式。
雖然這種格式未在機器學習中使用,但它在科學領域佔有一席之地。
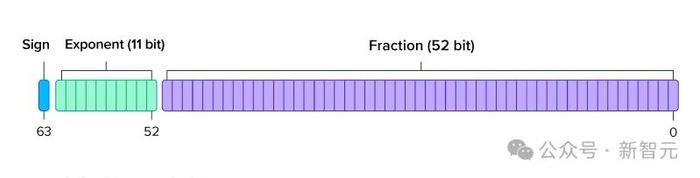
FP32和FP16:長期以來,FP32是所有深度學習計算的事實標准。
然而,數據科學家後來發現,將模型參數轉換爲FP16格式,可以減少內存消耗並加快計算速度,而且似乎不會影響質量。
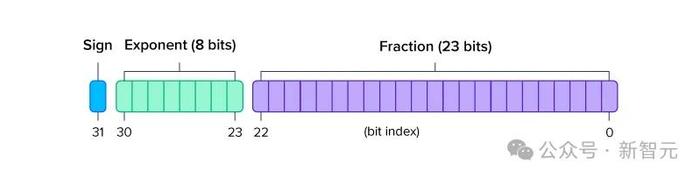
結果,FP16就成爲了新的黃金標准。
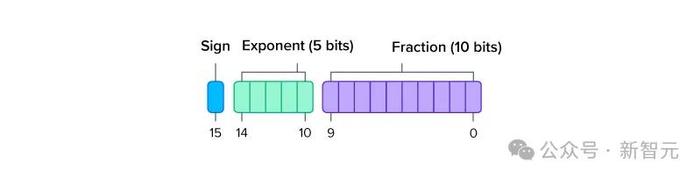
TF32,也是另一種至關重要的格式。
在進入張量內核上處理FP32值的計算之前,這些值可以在驅動程序級別自動轉換爲TF32格式,而無需更改代碼。
顯然,TF32雖然略有不同,但能提供更快的計算速度。也就是說,可以通過模型在張量內核上解釋FP32的方式進行編碼。

INT8:這是一種整數格式,不涉及浮點數。
訓練後,模型參數可以轉換爲其他佔用內存較少的類型,例如INT8。這種技術稱爲訓練後量化,可以減少內存需求並加快推理速度。它爲許多模型架構創造了奇跡,不過Transformer 是一個例外。
Transformer無法在訓練後進行轉換,以降低推理的硬件要求。量化感知訓練等創新技術確實在訓練過程中提供了一種解決方法,但重新訓練現有模型有可能成本高昂,而且極具挑战性。
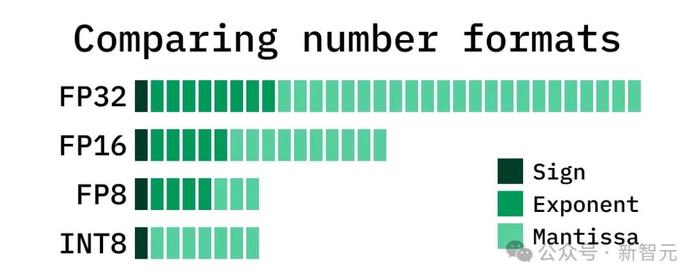
FP8:此格式解決了上述問題,尤其是Transformer模型。
可以採用預訓練的Transformer模型,將其參數轉換爲FP8格式,然後從A100切換到H100。
甚至我們可以在不進行轉換的情況下做到這一點,並仍然獲得性能,只是因爲H100速度更快。
借助FP8,只需大約四分之一的顯卡即可推斷出具有相同性能和負載的相同模型。
另外,使用FP8進行混合精度訓練也很不錯——這個過程會完成得更快,需要更少的RAM,並且在稍後的推理階段不再需要轉換,因爲模型的參數可能已經是FP8的參數。
ML、HPC和圖形的關鍵GPU規格及性能基准
下面讓我們來討論一下,GPU規格的演變及其突出功能。
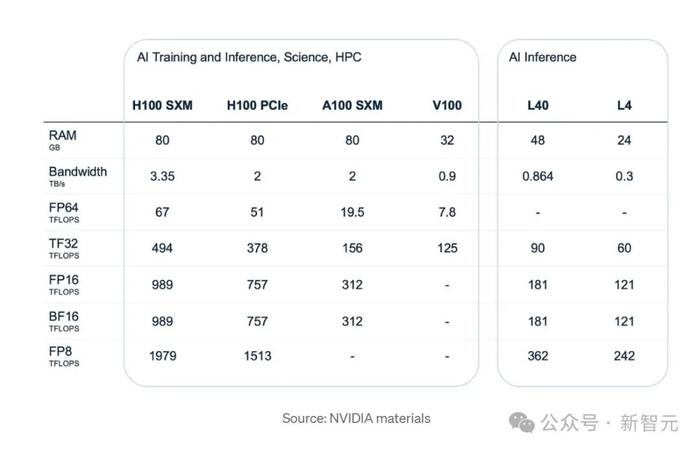
請特別注意上圖中的前兩行:RAM數量及其帶寬。
ML模型必須緊密適合運行時環境可訪問的GPU。否則,我們將需要多個GPU進行訓練。在推理過程中,通常可以將所有內容都安裝在單個芯片上。
注意SXM和PCIe接口之間的區別。英偉達的工作人員只是根據我們自己或我們的雲提供商已有的服務器來區分它們。
如果設置包括帶有PCI插槽的標准服務器,並且不想爲GPU直接連接到主板的專用機器(SXM)花錢,那么H100 PCIe就是我們的最佳選擇。
當然,它的規格可能比SXM版本要弱,但它與標准緊湊型服務器完全兼容。
但是,如果我們想從頭开始構建頂級集群,並且也能負擔得起,那么H100 SXM5顯然是更好的選擇。
各種 GPU 在訓練和推理中的性能指標,則可以依據下圖:
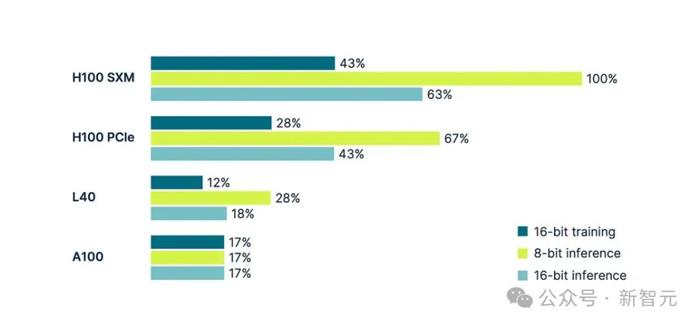 圖表源自Tim Dettmers的這篇著名文章《深度學習應該使用哪些GPU:我在深度學習中使用GPU的經驗和建議》
圖表源自Tim Dettmers的這篇著名文章《深度學習應該使用哪些GPU:我在深度學習中使用GPU的經驗和建議》
H100 SXM指標用作100%基准,所有其他指標均相對於此進行標准化。
該圖表顯示,H100 GPU上的8位推理,比相同GPU模型上的16位推理快37%。這是由於硬件支持FP8精度計算。
所謂“硬件支持”,是指將數據從RAM移動到張量核心進行計算的整個低級管线。在此過程中,各種緩存开始發揮作用。
而在A100中,由於硬件級別不支持FP8,此類GPU上的 8 位推理速度並不會更快。來自RAM 的緩存僅以與FP16格式相同的速度處理數字。
更詳細的圖表如下:
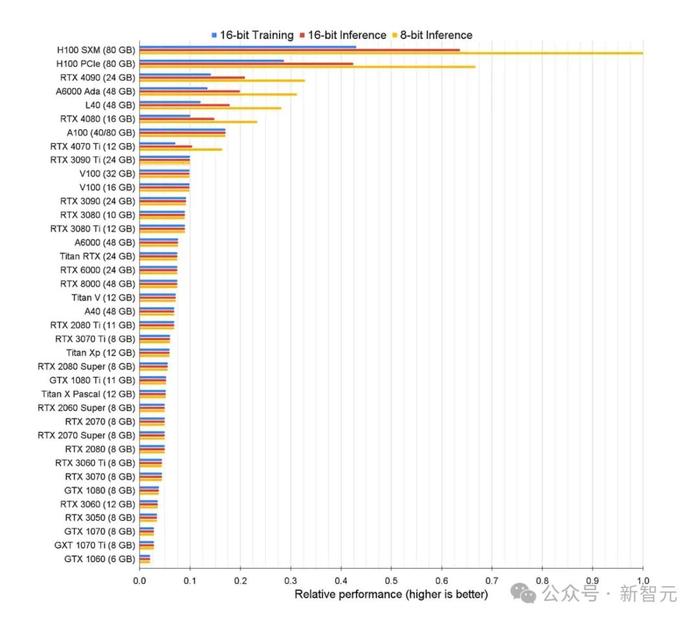
你肯定注意到了,某些RTX顯卡在AI任務中的結果也不錯。通常,它們的內存比起數據中心專用卡要少,並且不支持集群,但它們的價格顯然便宜很多。
所以,如果計劃用於內部實驗的本地基礎設施,也可以考慮這類RTX顯卡。
然而,GeForce驅動程序EULA直接禁止在數據中心使用此類卡,所以任何雲提供商都無權在服務中使用它們。
現在,我們再比較一下圖形和視頻處理相關任務中的GPU。以下是與此類用例相關的關鍵規範:
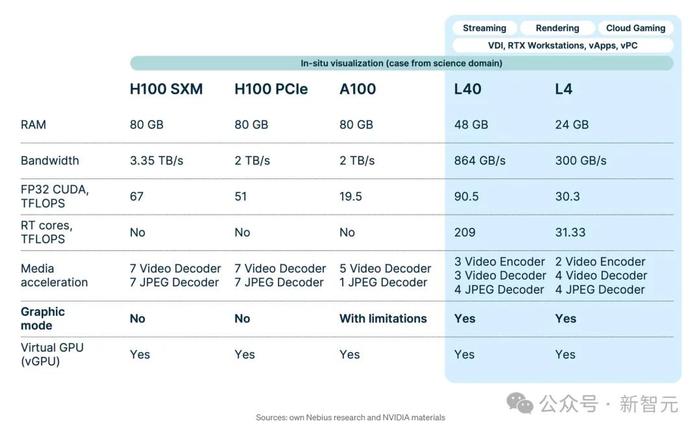
我們需要再次關注RAM大小和帶寬。另外,還要注意RT核心的獨特性能指標,以及解碼器和編碼器計數,這些專用芯片負責壓縮和解壓縮視頻源。
“圖形模式”行會指示GPU是否可以切換到面向圖形的模式 (WDDM)。
H100完全沒有這個功能;A100有此功能,但也會受限,因此不一定實用。
形成鮮明對比的是,L4和L40配備了這種模式,因此它們被定位爲適用於各種任務(包括圖形和訓練)的多功能卡。
英偉達在有些材料中甚至首先將它們作爲面向圖形的卡進行營銷。然而,它們也非常適合機器學習和神經網絡訓練和推理,至少沒有任何硬性技術障礙。
而用戶來說,這些數字意味着H100變體以及A100都不適合以圖形爲中心的任務。
V100有可能充當處理圖形工作負載虛擬工作站的GPU。
L40是資源最密集的4K遊戲體驗無可爭議的冠軍,而L4支持1080p遊戲。這兩種卡還能以各自的分辨率渲染視頻。
總結
我們可以得出下表,根據不同顯卡的設計目的,展示了不同顯卡的特性。
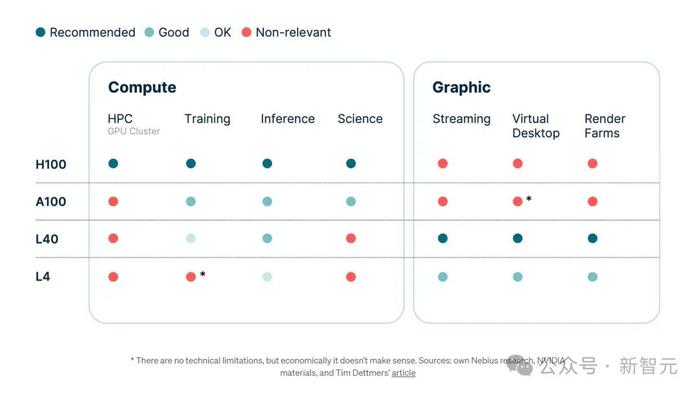
該表中有兩個主要用例類別:純粹專注於計算的任務(「計算」)和包含可視化的任務(「圖形」)。
我們已經知道,A100和H100完全不適合圖形,而L4和L40則是爲此量身定制的。
乍一看,你可能會覺得A100或L40的推理能力同樣出色。然而,有一些細微差別需要考慮。
在“HPC”一列中,顯示了是否可以將多個主機合並到單個集群中。
在推理中,很少需要集群——但這取決於模型的大小。關鍵是確保模型適合主機上所有GPU的內存。
如果模型超出了此邊界,或者主機無法爲其組合RAM容納足夠的GPU,那么就需要GPU集群。
L40和L4的可擴展性受到單個主機功能的限制, H100和A100則沒有這個限制。
我們應該在ML工作負載中選擇哪種GPU呢?推薦如下:
L4:經濟實惠的通用GPU,適用於各種用例。它是一款入門級模型,是通往GPU加速計算世界的門戶。
L40:針對生成式AI推理和視覺計算工作負載進行了優化。
A100:爲傳統CNN網絡的單節點訓練提供了卓越的性價比。
H100:BigNLP、LLMs和Transformer的最佳選擇。它還非常適合分布式訓練場景以及推理。
圖形場景可分爲三組:流式傳輸、虛擬桌面和渲染農場。如果沒有視頻輸入模型,那么它就不是圖形場景。這就是推理,而此類任務最好被描述爲人工智能視頻。
卡可以處理加密的視頻源,並且A100配備了硬件視頻解碼器來完成此類任務。這些解碼器將饋送轉換爲數字格式,使用神經網絡對其進行增強,然後將其傳回。
在整個過程中,顯示器上不會出現任何視覺內容,因此雖然H100和A100可以熟練地訓練與視頻或圖像相關的模型,但它們實際上並不產生任何視頻。
這就是另一個故事了。
*聲明:本文系原作者創作。文章內容系其個人觀點,我方轉載僅爲分享與討論,不代表我方贊成或認同,如有異議,請聯系後台。
標題:全美TOP 5機器學習博士:痛心,實驗室H100數量爲0!
地址:https://www.utechfun.com/post/394273.html