
(報告出品方/作者:海通國際,姚書橋)
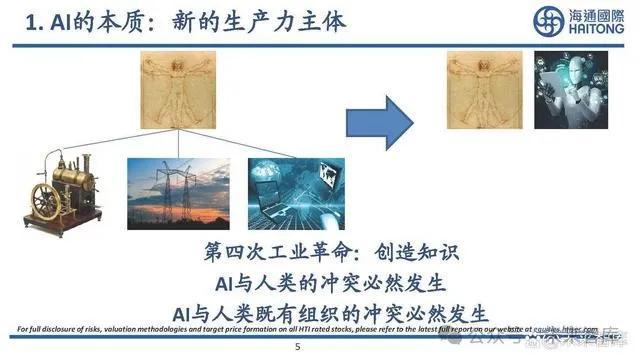
1. AI的本質:三大謬誤和五大悖論
悖論1:莫拉維克悖論 (Moravec’s Paradox)
實現類似人類的高階的認知任務(如推理和解決問題)需要很少的計算能力,但在模擬人類的基本感知和運動 技能時卻需要大量算力。
悖論2:腦科學悖論
計算機科學 = 硬件科學 + 軟件科學;智能科學 = 腦科學 + 心理學;人工智能 = 智能科學 + 計算機科學
悖論3:可解釋性與自主性悖論
AI系統的自主性增強但做出的決策越來越難以解釋。一方面,我們希望AI系統能夠自主地做出決策,但另一方 面,我們也需要理解這些決策背後的原因,以便進行監管和糾正錯誤。
悖論4:知識圖譜悖論
盡管AI和機器學習技術能夠從大量數據中發現模式和知識,但它們只能執行預設的算法和處理已有的信息,而 不會產生真正意義上的新知識。
悖論5:生成AI悖論
生成AI可能在生成內容時表現出高度的創造性,但這些內容的質量和邏輯性卻難以評估,因爲AI可能並不完理 解其自身創作的內容。
2. 通往AGI的路徑:美國看技術創新
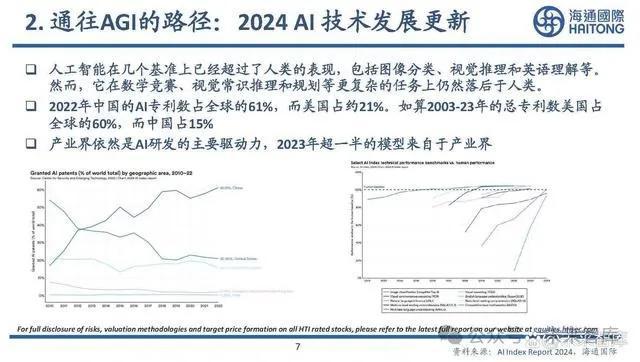
通往AGI的路徑:2024 AI 技術發展更新
人工智能在幾個基准上已經超過了人類的表現,包括圖像分類、視覺推理和英語理解等。然而,它在數學競賽、視覺常識推理和規劃等更復雜的任務上仍然落後於人類。2022年中國的AI專利數佔全球的61%,而美國佔約21%。如算2003-23年的總專利數美國佔 全球的60%,而中國佔15% 。產業界依然是AI研發的主要驅動力,2023年超一半的模型來自於產業界。
通往AGI的路徑:尺度定律的終點
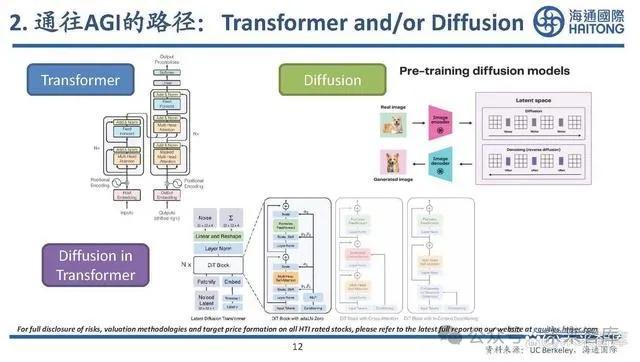
尺度定律(Scaling laws)是一種描述系統隨着規模的變化而發生的規律性變化的數學表達, 通常表現爲一些可測量的特徵隨着系統大小的增加而呈現出一種固定的比例關系。尺度定律 在不同學科領域中都有廣泛的應用,包括物理學、生物學、經濟學等,Open AI 2020年發現, 大語言模型也遵循着尺度定律(以Transformer爲代表) 。尺度定律是通過增加計算量、模型參數和數據集大小來提升單個大語言模型的“智能”水平 。但在多模態的數據集中,尺度定律的極限更加難以達到,模型性能會在達到極限前提前衰減。
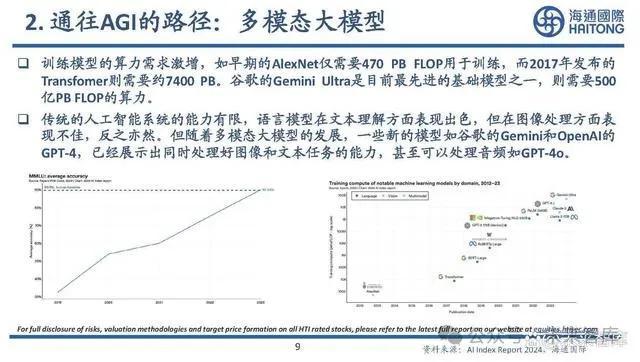
通往AGI的路徑:多模態大模型
訓練模型的算力需求激增,如早期的AlexNet僅需要470 PB FLOP用於訓練,而2017年發布的 Transfomer則需要約7400 PB。谷歌的Gemini Ultra是目前最先進的基礎模型之一,則需要500 億PB FLOP的算力。
傳統的人工智能系統的能力有限,語言模型在文本理解方面表現出色,但在圖像處理方面表 現不佳,反之亦然。但隨着多模態大模型的發展,一些新的模型如谷歌的Gemini和OpenAI的 GPT-4,已經展示出同時處理好圖像和文本任務的能力,甚至可以處理音頻如GPT-4o。
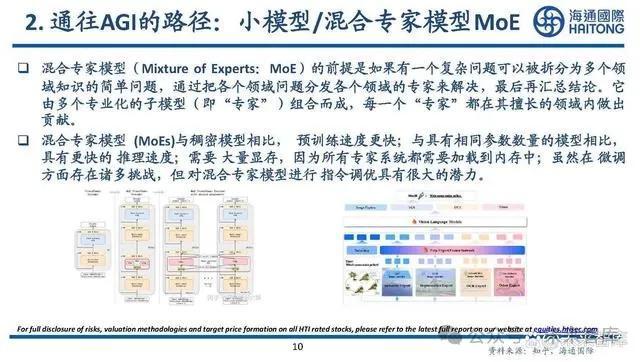
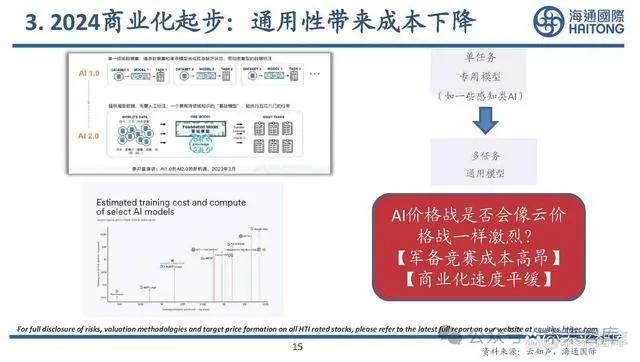
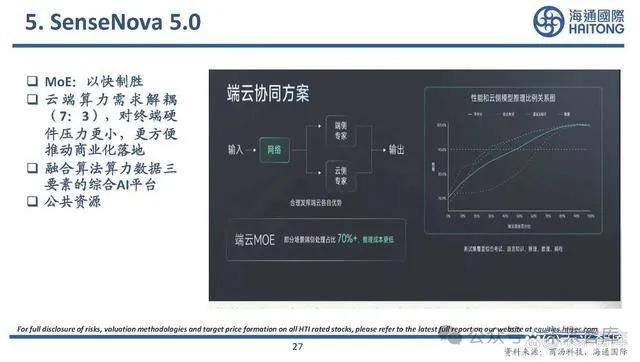
通往AGI的路徑:小模型/混合專家模型MoE
混合專家模型(Mixture of Experts:MoE)的前提是如果有一個復雜問題可以被拆分爲多個領 域知識的簡單問題,通過把各個領域問題分發各個領域的專家來解決,最後再匯總結論。它 由多個專業化的子模型(即“專家”)組合而成,每一個“專家”都在其擅長的領域內做出 貢獻。
混合專家模型 (MoEs)與稠密模型相比, 預訓練速度更快;與具有相同參數數量的模型相比, 具有更快的 推理速度;需要 大量顯存,因爲所有專家系統都需要加載到內存中;雖然在 微調 方面存在諸多挑战,但 對混合專家模型進行 指令調優具有很大的潛力。
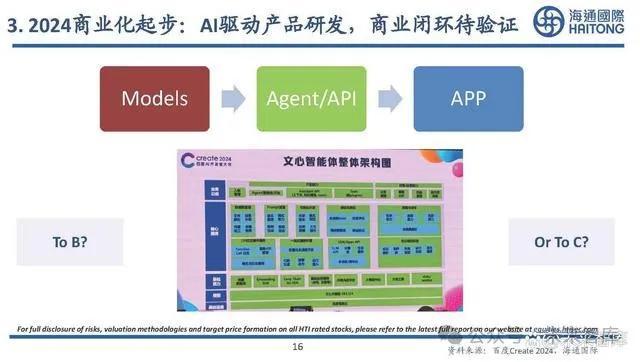
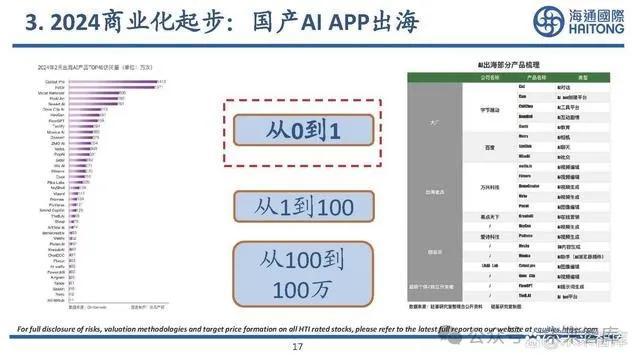
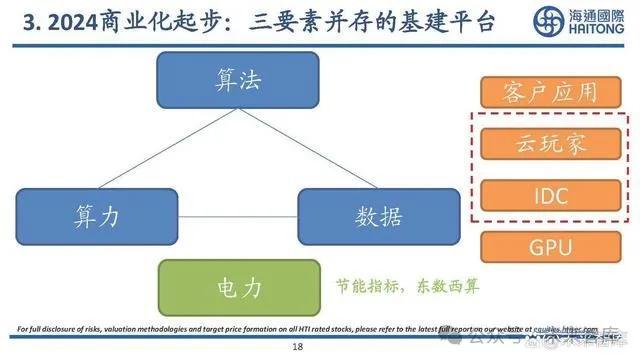
3. 2024商業化起步:中國看場景應用
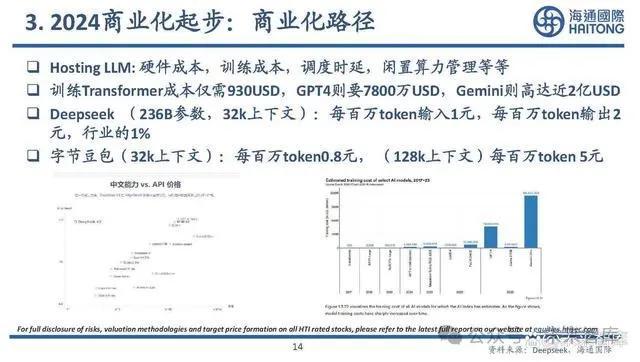
Hosting LLM: 硬件成本,訓練成本,調度時延,闲置算力管理等等 。訓練Transformer成本僅需930USD,GPT4則要7800萬USD,Gemini則高達近2億USD 。Deepseek (236B參數,32k上下文):每百萬token輸入1元,每百萬token輸出2 元,行業的1% 。字節豆包(32k上下文):每百萬token0.8元, (128k上下文)每百萬token 5元。
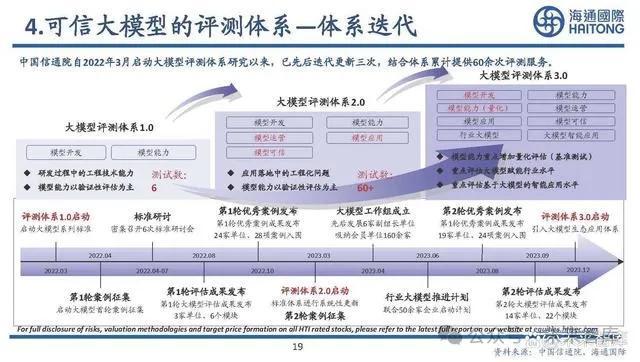
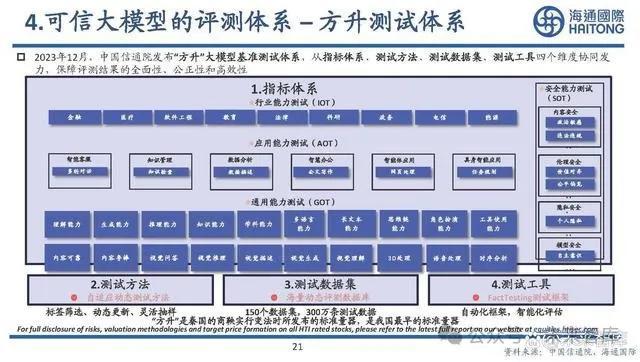
4.可信大模型的評測體系—體系迭代
可信大模型的評測體系 – 基准測試榜單
深度學習的評估一直使用基准測試(Benchmark),大模型也通過設計合理的測試任務和數據集來客觀、公正、量化的評估模 型的性能,是產學研各界最爲認可的人工智能評測方式。大模型基准測試榜單主要通過多維度評測考察模型綜合能力,測試方法主要分爲客觀考試和人工主觀評價。
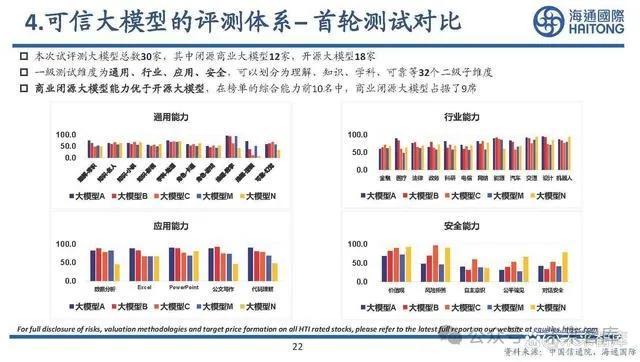
可信大模型的評測體系– 首輪測試對比
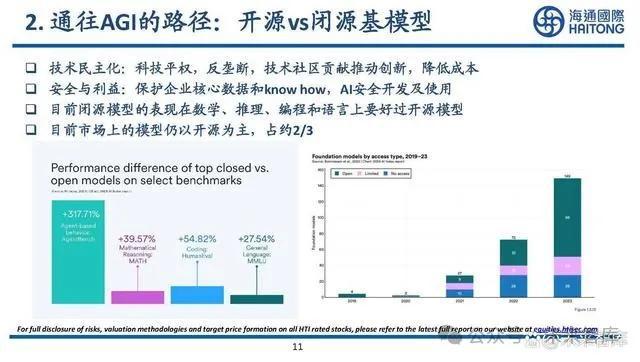
本次試評測大模型總數30家,其中閉源商業大模型12家,开源大模型18家。一級測試維度爲通用、行業、應用、安全,可以劃分爲理解、知識、學科、可靠等32個二級子維度。商業閉源大模型能力優於开源大模型,在榜單的綜合能力前10名中,商業閉源大模型佔據了9席。
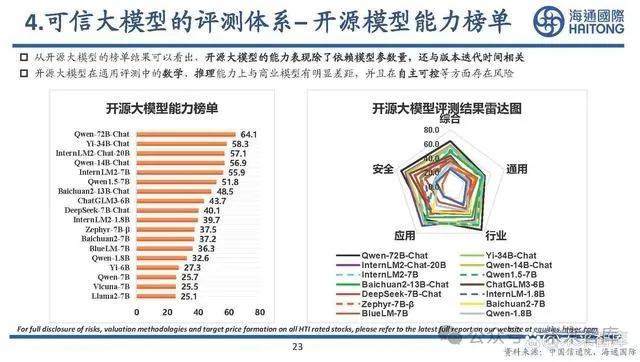
可信大模型的評測體系– 开源模型能力榜單
從开源大模型的榜單結果可以看出,开源大模型的能力表現除了依賴模型參數量,還與版本迭代時間相關。开源大模型在通用評測中的數學、推理能力上與商業模型有明顯差距,並且在自主可控等方面存在風險。
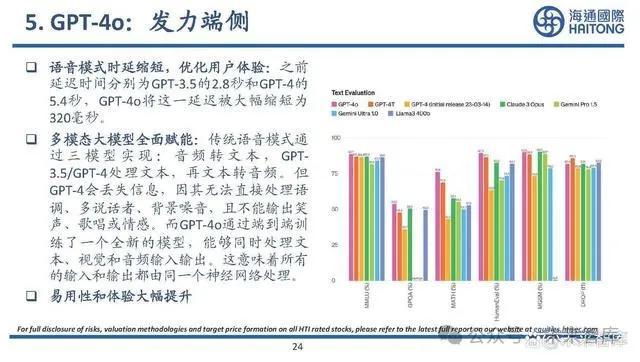
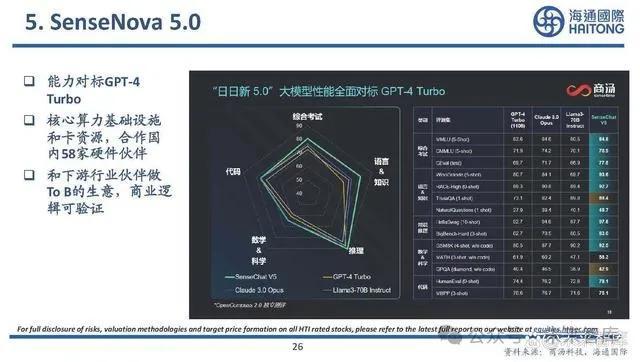
5. GPT-4o:發力端側
語音模式時延縮短,優化用戶體驗:之前 延遲時間分別爲GPT-3.5的2.8秒和GPT-4的 5.4秒,GPT-4o將這一延遲被大幅縮短爲 320毫秒。多模態大模型全面賦能:傳統語音模式通 過 三 模 型 實 現 :音 頻 轉 文 本 , GPT3.5/GPT-4處理文本,再文本轉音頻。但 GPT-4會丟失信息,因其無法直接處理語 調、多說話者、背景噪音,且不能輸出笑 聲、歌唱或情感。而GPT-4o通過端到端訓 練了一個全新的模型,能夠同時處理文 本、視覺和音頻輸入輸出。這意味着所有 的輸入和輸出都由同一個神經網絡處理。
Google I/O 2024
Gemini Live:谷歌發布了語音對話人工智能助手Gemini Live,用戶可以在移動 應用上與Gemini進行對話,對標GPT-4o。輕量化模型Gemini 1.5 Flash:基於“蒸餾”技術,專爲大規模服務設計,速度 更快、成本低至0.35美元/百萬Token。圖像、視頻和音樂的人工智能生成工具:谷歌發布了針對圖像、視頻和音樂的 人工智能生成工具,分別爲Imagen 3、Veo和Music AI Sandbox 。Gemini支持的AI Overview功能:谷歌即將在瀏覽器搜索中引入Gemini支持的AI Overview功能,新功能可以使瀏覽器支持多輪推理,將復雜問題分解處理,將 原本需要幾分鐘甚至幾個小時的研究壓縮到在幾秒鐘內完成,還將支持在搜索 中對視頻提問。硬件生態:TPU,ARM架構的CPU,GPU同NVIDIA合作,通過Cloud賣算力。現有產業生態賦能:Ask Photos,Workspace, etc。
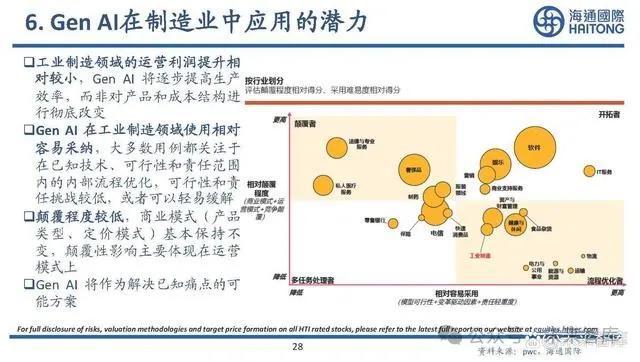
6. Gen AI在制造業中應用的潛力
工業制造領域的運營利潤提升相 對較小,Gen AI 將逐步提高生產 效率,而非對產品和成本結構進 行徹底改變。Gen AI 在工業制造領域使用相對 容易採納,大多數用例都關注於 在已知技術、可行性和責任範圍 內的內部流程優化,可行性和責 任挑战較低,或者可以輕易緩解。顛覆程度較低,商業模式(產品 類型、定價模式)基本保持不 變,顛覆性影響主要體現在運營 模式上 。Gen AI 將作爲解決已知痛點的可 能方案。
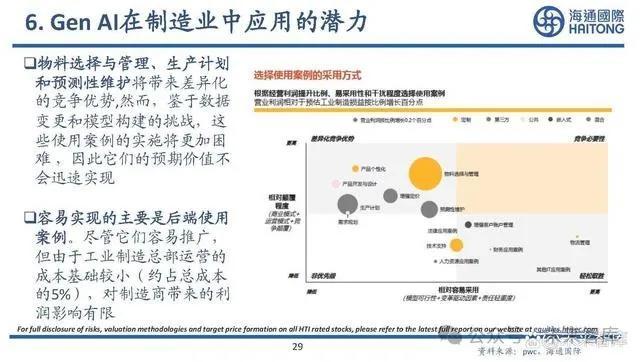
物料選擇與管理、生產計劃 和預測性維護將帶來差異化 的競爭優勢,然而,鑑於數據 變更和模型構建的挑战,這 些使用案例的實施將更加困 難 ,因此它們的預期價值不 會迅速實現。容易實現的主要是後端使用 案例。盡管它們容易推廣, 但由於工業制造總部運營的 成本基礎較小(約佔總成本 的5%),對制造。
報告節選:







(本文僅供參考,不代表我們的任何投資建議。如需使用相關信息,請參閱報告原文。)
特別聲明:以上文章內容僅代表作者本人觀點,不代表新浪網觀點或立場。如有關於作品內容、版權或其它問題請於作品發表後的30日內與新浪網聯系。標題:AI革命,終於來了!
地址:https://www.utechfun.com/post/391017.html